Probablemente sepa cómo insertar registros en una tabla utilizando cláusulas VALUES únicas o múltiples. También sabe cómo hacer inserciones masivas usando SQL INSERT INTO SELECT. Pero aun así hiciste clic en el artículo. ¿Se trata de manejar duplicados?
Muchos artículos cubren SQL INSERT INTO SELECT. Google o Bing y elija el título que más le guste, lo hará. Tampoco cubriré ejemplos básicos de cómo se hace. En cambio, verá ejemplos de cómo usarlo Y manejar duplicados al mismo tiempo . Por lo tanto, puede crear este mensaje familiar a partir de sus esfuerzos INSERTAR:
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
Pero lo primero es lo primero.

[ID de formulario de envío de pulso =”12989″]
Preparar datos de prueba para SQL INSERT INTO SELECT Code Samples
Estoy pensando en pasta esta vez. Entonces, usaré datos sobre platos de pasta. Encontré una buena lista de platos de pasta en Wikipedia que podemos usar y extraer en Power BI usando una fuente de datos web. Ingresé la URL de Wikipedia. Luego especifiqué los datos de 2 tablas de la página. Lo limpié un poco y copié los datos a Excel.
Ahora tenemos los datos, puedes descargarlos desde aquí. Es crudo porque vamos a hacer 2 tablas relacionales a partir de él. Usar INSERT INTO SELECT nos ayudará a hacer esta tarea,
Importar los datos en SQL Server
Puede usar SQL Server Management Studio o dbForge Studio para SQL Server para importar 2 hojas en el archivo de Excel.
Cree una base de datos en blanco antes de importar los datos. Llamé a las tablas dbo.ItalianPastaDishes y dbo.NonItalianPastaDishes .
Crear 2 tablas más
Definamos las dos tablas de salida con el comando ALTER TABLE de SQL Server.
CREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
Nota:Hay índices únicos creados en dos tablas. Evitará que insertemos registros duplicados más adelante. Las restricciones harán que este viaje sea un poco más difícil pero emocionante.
Ahora que estamos listos, profundicemos.
5 formas fáciles de manejar duplicados usando SQL INSERT INTO SELECT
La forma más fácil de manejar los duplicados es eliminar las restricciones únicas, ¿verdad?
¡Error!
Sin restricciones únicas, es fácil cometer un error e insertar los datos dos veces o más. No queremos eso. ¿Y si tenemos una interfaz de usuario con una lista desplegable para elegir el origen del plato de pasta? ¿Los duplicados harán felices a sus usuarios?
Por lo tanto, eliminar las restricciones únicas no es una de las cinco formas de manejar o eliminar registros duplicados en SQL. Tenemos mejores opciones.
1. Usando INSERTAR EN SELECCIONAR DISTINTO
La primera opción para identificar registros SQL en SQL es usar DISTINCT en su SELECT. Para explorar el caso, completaremos el Origen mesa. Pero primero, usemos el método incorrecto:
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
Esto activará los siguientes errores duplicados:
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
Hay un problema cuando intenta seleccionar filas duplicadas en SQL. Para iniciar la verificación SQL de duplicados que existían antes, ejecuté la parte SELECT de la instrucción INSERT INTO SELECT:
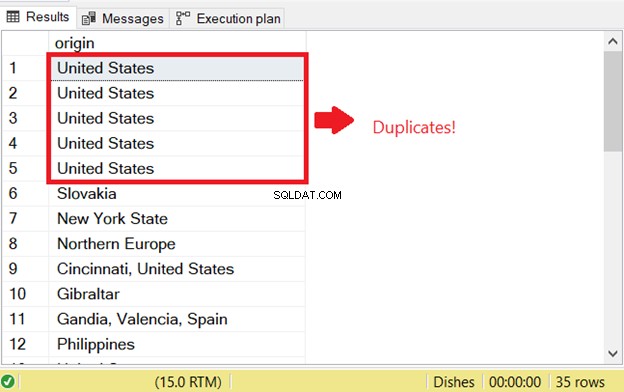
Esa es la razón del primer error de duplicación de SQL. Para evitarlo, agregue la palabra clave DISTINCT para que el conjunto de resultados sea único. Aquí está el código correcto:
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
Inserta los registros con éxito. Y hemos terminado con el Origen mesa.
El uso de DISTINCT creará registros únicos a partir de la instrucción SELECT. Sin embargo, no garantiza que no existan duplicados en la tabla de destino. Es bueno cuando está seguro de que la tabla de destino no tiene los valores que desea insertar.
Por lo tanto, no ejecute estas declaraciones más de una vez.
2. Usando DONDE NO EN
A continuación, completamos los Platos de pasta mesa. Para eso, primero necesitamos insertar registros de los platos de pasta italianos mesa. Aquí está el código:
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
Desde platos de pasta italianos contiene datos sin procesar, necesitamos unirnos al Origen texto en lugar del OriginID . Ahora, intente ejecutar el mismo código dos veces. La segunda vez que se ejecute no se insertarán registros. Ocurre debido a la cláusula WHERE con el operador NOT IN. Filtra registros que ya existen en la tabla de destino.
A continuación, debemos completar los Platos de pasta tabla de los platos de pasta no italianos mesa. Dado que solo estamos en el segundo punto de esta publicación, no insertaremos todo.
Elegimos platos de pasta de los Estados Unidos y Filipinas. Aquí va:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
Hay 9 registros insertados de esta declaración; consulte la Figura 2 a continuación:
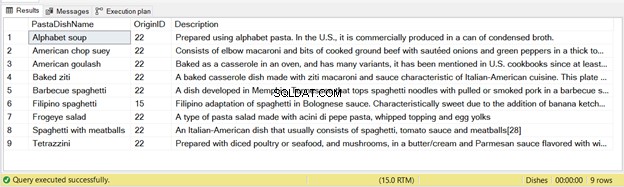
Nuevamente, si ejecuta el código anterior dos veces, la segunda ejecución no tendrá registros insertados.
3. Usando DONDE NO EXISTE
Otra forma de encontrar duplicados en SQL es usar NOT EXISTS en la cláusula WHERE. Intentémoslo con las mismas condiciones del apartado anterior:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
El código anterior insertará los mismos 9 registros que vio en la Figura 2. Evitará insertar los mismos registros más de una vez.
4. Usando SI NO EXISTE
A veces, es posible que necesite implementar una tabla en la base de datos y es necesario verificar si ya existe una tabla con el mismo nombre para evitar duplicados. En este caso, el comando SQL DROP TABLE IF EXISTS puede ser de gran ayuda. Otra forma de asegurarse de que no insertará duplicados es usando SI NO EXISTE. Nuevamente, usaremos las mismas condiciones de la sección anterior:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
El código anterior verificará primero la existencia de 9 registros. Si devuelve verdadero, INSERT continuará.
5. Usando CONTAR(*) =0
Finalmente, el uso de COUNT (*) en la cláusula WHERE también puede garantizar que no insertará duplicados. He aquí un ejemplo:
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
Para evitar duplicados, el COUNT o los registros devueltos por la subconsulta anterior deben ser cero.
Nota :Puede diseñar cualquier consulta visualmente en un diagrama utilizando la función Query Builder de dbForge Studio para SQL Server.
Comparación de diferentes formas de manejar duplicados con SQL INSERT INTO SELECT
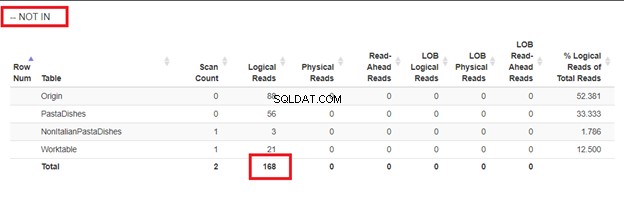
4 secciones usaron el mismo resultado pero diferentes enfoques para insertar registros masivos con una instrucción SELECT. Quizás se pregunte si la diferencia está solo en la superficie. Podemos verificar sus lecturas lógicas de STATISTICS IO para ver qué tan diferentes son.
Usando DONDE NO EN:
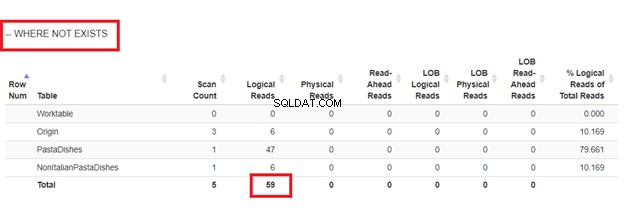
Usando NO EXISTE:
Usando SI NO EXISTE:
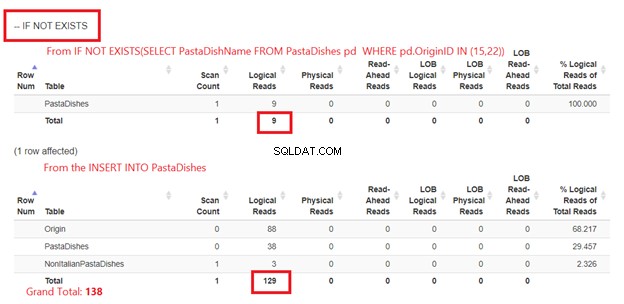
La figura 5 es un poco diferente. Aparecen 2 lecturas lógicas para PastaDishes mesa. El primero es de IF NOT EXISTS(SELECT PastaDishName de Platos de pasta DONDE ID de origen EN (15,22)). El segundo es de la instrucción INSERT.
Finalmente, usando COUNT(*) =0
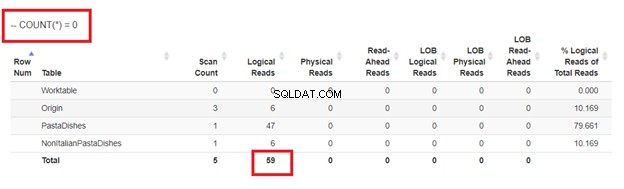
De las lecturas lógicas de 4 enfoques que tuvimos, la mejor opción es WHERE NOT EXISTS o COUNT(*) =0. Cuando inspeccionamos sus planes de ejecución, vemos que tienen el mismo QueryHashPlan . Por lo tanto, tienen planes similares. Mientras tanto, el menos eficiente es usar NOT IN.
¿Significa que DONDE NO EXISTE siempre es mejor que NO EN? En absoluto.
¡Inspeccione siempre las lecturas lógicas y el Plan de Ejecución de sus consultas!
Pero antes de concluir, debemos terminar la tarea en cuestión. Luego insertaremos el resto de los registros e inspeccionaremos los resultados.
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
Hojear la lista de 179 platos de pasta de Asia a Europa me da hambre. Echa un vistazo a una parte de la lista de Italia, Rusia y más a continuación:

Conclusión
Después de todo, evitar duplicados en SQL INSERT INTO SELECT no es tan difícil. Tienes operadores y funciones a mano para llevarte a ese nivel. También es un buen hábito revisar el Plan de Ejecución y las lecturas lógicas para comparar cuál es mejor.
Si cree que alguien más se beneficiará de esta publicación, compártala en sus plataformas de redes sociales favoritas. Y si tiene algo que agregar que olvidamos, háganoslo saber en la sección de Comentarios a continuación.