¿Piensas en algo cuando creas una nueva base de datos? Supongo que la mayoría de vosotros diría que no, ya que todos usamos parámetros predeterminados, aunque están lejos de ser óptimos. Sin embargo, hay un montón de configuraciones de disco que realmente ayudan a aumentar la confiabilidad y el rendimiento del sistema.
No hablaremos de la importancia del sistema de archivos NTFS para la confiabilidad de los datos, aunque este sistema de archivos permite que MS SQL Server use el disco de la manera más efectiva.
Si tiene pocos recursos y algo comienza a funcionar lentamente, lo primero que le viene a la mente es actualizar. Pero la actualización no es necesaria en todos los casos. Puede salirse con la suya con el ajuste, aunque no debe hacerse cuando el servidor comienza a funcionar lentamente, sino en la etapa de diseño e instalación.
La optimización es un proceso complejo y, a menudo, está relacionado no solo con un determinado programa (en nuestro caso, con una determinada base de datos), sino también con el sistema operativo y el hardware. Aunque hablaremos principalmente de bases de datos, no podemos ignorar las cosas externas.
Arquitectura de datos
SQL Server almacena, lee y escribe datos por bloques de 8 KB cada uno. Estos bloques se llaman páginas. Una base de datos puede almacenar 128 páginas por megabyte (1 megabyte o 1048576 bytes dividido por 8 kilobytes o 8192 bytes). Todas las páginas se almacenan en una extensión. Una extensión son las últimas 8 páginas secuenciales o 64 KB. Por lo tanto, 1 megabyte almacena 16 extensiones.
Las páginas y las extensiones son la base de la estructura de la base de datos física de SQL Server. MS SQL Server utiliza varios tipos de página, algunos de ellos rastrean el espacio asignado, algunos contienen datos de usuario e índices. Las páginas que rastrean el espacio asignado contienen los datos densamente comprimidos. Permite que MS SQL Server los almacene de manera efectiva en la memoria para facilitar la lectura.
SQL Server usa dos tipos de extensiones:
- Las extensiones que almacenan páginas de dos a muchos objetos se denominan extensiones mixtas. Cada tabla comienza como una extensión mixta. Utiliza la extensión mixta principalmente para las páginas que almacenan espacio y contienen objetos pequeños.
- Las extensiones que tienen las 8 páginas asignadas a un objeto se denominan extensiones uniformes. Se utilizan cuando una tabla o índice requiere más de 64 KB.
La primera extensión de cada archivo es uniforme y contiene páginas del encabezado del archivo, las siguientes extensiones contienen 3 páginas asignadas cada una. El servidor asigna estas extensiones mixtas cuando crea un archivo de datos básico y utiliza estas páginas para sus tareas internas. La página de encabezado del archivo contiene atributos de archivo, como el nombre de la base de datos almacenada en el archivo, grupo de archivos, tamaño mínimo, tamaño de incremento. Esta es la primera página de cada archivo (página 0).
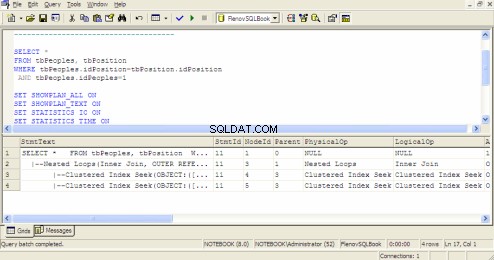
Plan de ejecución de consultas en SQL Query Analyzer
Espacio libre de página (PFS ) en una página asignada que contiene información sobre el espacio libre disponible en el archivo. Esta información se almacena en la página 1. Cada una de estas páginas puede extenderse a 8000 páginas contiguas, lo que equivale a aproximadamente 64 Mb de datos.
El registro de transacciones recopila toda la información sobre los cambios que tienen lugar en el servidor para restaurar una base de datos en el momento del error del sistema y garantizar la integridad de los datos.
Tenga en cuenta que todos los números son múltiplos de 8 o 16. Esto se debe a que el controlador del disco duro lee datos de este tamaño más fácilmente. Los datos se leen del disco por páginas, es decir, por 8 kilobytes, que es un valor bastante óptimo.
Protección de página
A partir de MS SQL Server 2005, el servidor de base de datos presenta una nueva opción:el control de datos a nivel de página. Si el AGE_VERIFY_CHECKSUM está habilitado (está habilitado de forma predeterminada), el servidor controlará las sumas de verificación de las páginas. Si buscamos en el manual para este parámetro, veremos que la suma de verificación permite rastrear los errores de entrada/salida que el sistema operativo no puede rastrear. ¿Qué tipo de errores son? Parece que son problemas internos del servidor de la base de datos.
La verificación de integridad de datos nunca falla, por lo que es mejor habilitarla. Para esto, necesitamos ejecutar el siguiente comando:
ALTER DATABASE имя базы SET PAGE_VERIFY
Si hay un error en la página, el servidor nos lo notificará. Pero, ¿cómo podemos solucionarlo rápidamente? Hay una opción para restaurar datos en el nivel de página para esto.
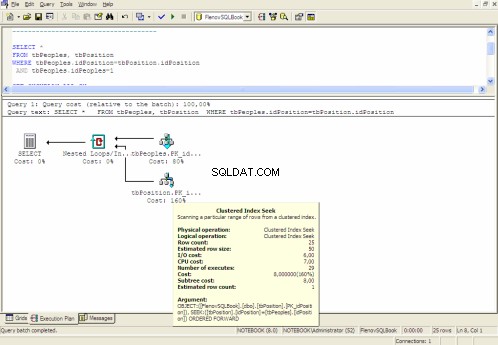
Plan de Ejecución Gráfico
Crecimiento de archivos
Cuando creamos una base de datos, se nos pide que seleccionemos el tamaño inicial y el método de incremento. Cuando nos falta el espacio actual, el servidor lo amplía en correspondencia con el método de incremento preestablecido.
Hay tres métodos de incremento para archivos:
- Crecimiento en megabytes.
- Crecimiento por porcentaje.
- Crecimiento manual.
Los primeros dos métodos se realizan automáticamente, pero se recomiendan solo para bases de datos de prueba ya que un administrador no tiene control sobre el tamaño del archivo.
Si un archivo se incrementa en una cierta cantidad de megabytes, en algún momento, la velocidad de inserción de datos puede aumentar y el crecimiento del archivo puede volverse demasiado frecuente, y esto es un costo adicional. El crecimiento de archivos en porcentajes tampoco es rentable. Se recomienda usar un crecimiento de archivo del 10% y esto está bien para bases de datos pequeñas y medianas. Pero cuando alcance los 1000 gigabytes, requerirá 100 gigabytes en cada crecimiento. Conducirá a una pérdida de espacio en disco sin sentido.
Controle siempre los cambios en el tamaño de los archivos y los registros de transacciones. Le permitirá utilizar los recursos del disco de la forma más eficaz.
Propiedades de la base de datos de MS SQL Server
Compresión de datos
El disco duro sigue siendo un lugar sensible de una computadora. El rendimiento de los procesadores crece vertiginosamente, mientras que los discos duros no pueden ofrecer nada nuevo. Para ahorrar el número de operaciones de entrada/salida y reducir los datos almacenados en el disco duro, puede utilizar discos con compresión. Solo estos discos son buenos para almacenar grupos de archivos de solo lectura. Quizás se deba a que se requiere compresión para los escritos y requiere costos de procesador adicionales.
La compresión de datos y el estado de solo lectura son buenos para los datos de archivo. Por ejemplo, los datos contables de los últimos años no son necesarios para escribir y pueden ocupar demasiado espacio. Al colocar datos en la sección de archivo del disco, ahorrará mucho espacio.
Discos para confiabilidad
El siguiente método permite aumentar la confiabilidad y el rendimiento al mismo tiempo y, nuevamente, está relacionado con los discos duros. Pues ahí está, la mecánica no solo es la más lenta sino la más poco fiable. En cuanto a la confiabilidad, no recopilé las estadísticas, pero tanto en casa como en el trabajo, trato principalmente con discos duros.
Por lo tanto, para aumentar el rendimiento y la confiabilidad, simplemente puede usar dos o más discos duros en lugar de uno. Será aún mejor si se conectan a controladores separados. Puede almacenar la base de datos en un disco y los registros de transacciones en otro. Si hay un tercer disco, puede almacenar el sistema.
El almacenamiento de datos y un registro en discos separados le permite aumentar considerablemente la confiabilidad. Suponga que tiene todo en un disco y se cae. ¿Qué hacer? Puede comunicarse con una empresa que intentará recuperar todo o intentar hacer lo mismo por su cuenta, pero la posibilidad de recuperación está lejos del 100%. Además, devolver el servidor al trabajo puede llevar una cantidad considerable de tiempo. La recuperación rápida se puede realizar solo hasta el momento de la última copia de seguridad. El resto es cuestionable.
Y ahora, suponga que tiene datos y un registro de transacciones en diferentes discos. Si el disco con el registro se apaga, los datos seguirán allí. Lo único es que no puedes añadir nuevos datos, pero si creas un nuevo registro, puedes seguir trabajando.
Si el disco con datos se apaga, aún podemos reservar el registro de transacciones para evitar la más mínima pérdida de datos. Después de eso, recuperamos los datos de la copia de seguridad completa (siempre se debe hacer antes, un buen administrador lo hace al menos una vez al día) y agregamos cambios desde la copia de seguridad del registro.
Discos para rendimiento
Si los datos y un registro están ubicados en discos separados, no solo significa seguridad sino también un aumento del rendimiento. La cuestión es que el servidor de la base de datos puede escribir datos simultáneamente en el registro y el archivo de datos.
Podemos ir más allá y asignar un disco duro al registro de transacciones y varios discos duros a los datos. El servidor trabaja con datos con más frecuencia, por eso requiere varios almacenamientos con los que puedas trabajar al mismo tiempo. Y si estos almacenamientos están conectados a diferentes controladores, el trabajo simultáneo está garantizado.
La variante más rápida y fiable es utilizar RAID . Sin embargo, no todos los RAID es fiable y rápido al mismo tiempo. Para los grupos de archivos, se recomienda elegir RAID10 , ya que contiene funciones bien balanceadas, pero dependiendo de los datos de la base de datos, puede elegir otra variante.
Puede utilizar una solución de software o hardware como RAID . Una solución de software es más barata, pero requiere recursos adicionales de CPU. Y un procesador no tiene recursos de repuesto. Por eso es mejor utilizar soluciones de hardware donde un chip dedicado se encarga de RAID .
Índices
Todo el mundo sabe que los índices ayudan a aumentar la velocidad de búsqueda de datos. La mayoría de nosotros entendemos que los índices afectan negativamente la inserción y actualización de datos, por lo que cuantos más índices tenga, más difícil será para el servidor mantenerlos. En eso, no muchos piensan que los índices requieren mantenimiento. Las páginas de la base de datos que contienen datos de índice pueden desbordarse y eventualmente desequilibrarse.
Sí, podemos ignorar varios parámetros y simplemente recrear índices una vez al mes, lo cual es similar al mantenimiento. SQL Server incluye dos parámetros que evitan que los índices se desactualicen media hora después de su creación:FILLFACTOR y PAD_INDEX .
Puede utilizar la opción FILLFACTOR para optimizar el rendimiento de las operaciones de inserción y actualización que contienen un índice agrupado o no agrupado. Los datos de índice se pueden almacenar en muchas páginas de datos. Como mencioné anteriormente, cada página consta de 8 KB. Cuando una página de índice está llena, el servidor crea una nueva página y divide la página para la inserción de datos en dos.
El servidor requiere tiempo para la división de la página y la creación de una nueva página. Para optimizar la división de páginas, utilice el FILLFACTOR opción para determinar el porcentaje de espacio libre en todas las hojas de la página de índice. Cuanto mayor sea el espacio en disco que tengan las páginas de nivel de hoja, menos frecuente tendrá que dividir las páginas de índice. En ese momento, el árbol de índice será demasiado grande y su omisión llevará más tiempo.
El PAD_INDEX La opción indica el porcentaje de llenado de las páginas que no son hojas. Puedes usar PAD_INDEX solo cuando el FACTOR DE RELLENO la opción se especifica desde el valor porcentual de PAD_INDEX depende del porcentaje especificado en FILFACTOR .
Estadísticas
Las estadísticas permiten que el servidor tome la decisión correcta entre el uso del índice y el escaneo completo de la tabla. Suponga que tiene una lista de empleados de un taller de fundición. Dicha lista estará compuesta por aproximadamente el 90% de los hombres.
Ahora, supongamos que necesitamos encontrar a todas las mujeres. Como no hay muchos de ellos, la opción más efectiva será utilizar el índice. Pero si necesitamos encontrar a todos los hombres, la eficiencia del índice se ralentiza. El número de registros seleccionados es demasiado grande y pasar por alto el árbol de índice para cada uno de ellos será una sobrecarga. Es mucho más sencillo escanear toda la tabla:la ejecución será mucho más rápida ya que el servidor necesitará leer todas las hojas de bajo nivel del índice una vez sin necesidad de lecturas múltiples de todos los niveles.
SQL Server recopila estadísticas leyendo todos los valores de campo o con una plantilla para la creación de la lista de valores ordenados y distribuidos uniformemente. SQL Server detecta dinámicamente el porcentaje de filas que se deben probar en función del número de filas de la tabla. Al recopilar estadísticas, el optimizador de consultas ejecutará un análisis completo o plantillas de filas.
Para que las estadísticas funcionen, se deben crear. En caso de actualización masiva de datos, las estadísticas pueden contener datos incorrectos y el servidor tomará una decisión equivocada. Pero todo se puede arreglar, necesita monitorear las estadísticas. Para obtener información más detallada, consulte los libros sobre Transact-SQL o MS SQL Server.
Resumen
La configuración predeterminada no permite utilizar todo el potencial del hardware y trabajar con toda la variedad de servidores. La responsabilidad de la configuración recae en los administradores. El hecho de que los productos de Microsoft tengan programas de instalación simples, utilidades de administración gráfica y la capacidad de trabajar sin conexión no significa que esta sea una variante óptima.
No consideramos tales opciones de ajuste de base de datos como aceleración de hardware. Si se agotan todas las opciones de ajuste, es mejor pensar en la actualización, ya que la aceleración del hardware afecta negativamente la confiabilidad del sistema.
Lo más importante es que cualquier optimización del servidor de base de datos o cualquier actualización no ayudará si las consultas no están optimizadas.