El tipo de datos de cadena es uno de los tipos de datos más significativos en cualquier lenguaje de programación. Difícilmente se puede escribir un programa útil sin él. Sin embargo, muchos desarrolladores desconocen ciertos aspectos de este tipo. Por lo tanto, consideremos estos aspectos.
Representación de cadenas en memoria
En .Net, las cadenas se ubican de acuerdo con la regla BSTR (cadena básica o cadena binaria). Este método de representación de datos de cadena se usa en COM (la palabra "básico" se origina en el lenguaje de programación Visual Basic en el que se usó inicialmente). Como sabemos, PWSZ (Pointer to Wide-character String, Zero-terminated) se usa en C/C++ para la representación de cadenas. Con tal ubicación en la memoria, una terminación nula se ubica al final de una cadena. Este terminador permite determinar el final de la cadena. La longitud de la cadena en PWSZ está limitada solo por un volumen de espacio libre.
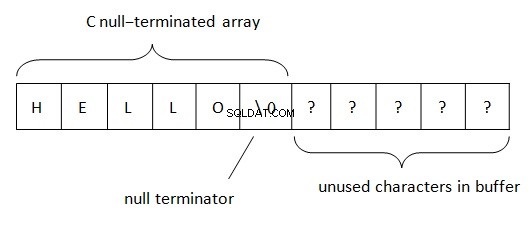
En BSTR, la situación es ligeramente diferente.
Los aspectos básicos de la representación de cadenas BSTR en la memoria son los siguientes:
- La longitud de la cadena está limitada por un cierto número. En PWSZ, la longitud de la cadena está limitada por la disponibilidad de memoria libre.
- La cadena BSTR siempre apunta al primer carácter del búfer. PWSZ puede apuntar a cualquier carácter en el búfer.
- En BSTR, similar a PWSZ, el carácter nulo siempre se ubica al final. En BSTR, el carácter nulo es un carácter válido y se puede encontrar en cualquier parte de la cadena.
- Debido a que el terminador nulo se encuentra al final, BSTR es compatible con PWSZ, pero no al revés.
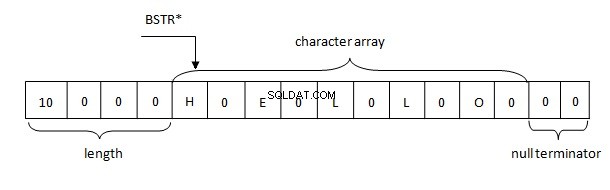
Por lo tanto, las cadenas en .NET se representan en la memoria según la regla BSTR. El búfer contiene una longitud de cadena de 4 bytes seguida de caracteres de dos bytes de una cadena en formato UTF-16, que, a su vez, es seguida por dos bytes nulos (\u0000).
El uso de esta implementación tiene muchos beneficios:la longitud de la cadena no debe volver a calcularse ya que se almacena en el encabezado, una cadena puede contener caracteres nulos en cualquier lugar. Y lo más importante es que la dirección de una cadena (anclada) se puede pasar fácilmente por código nativo donde WCHAR* se espera.
¿Cuánta memoria ocupa un objeto de cadena?
Encontré artículos que indican que el tamaño del objeto de cadena es igual a tamaño =20 + (longitud/2) * 4, pero esta fórmula no es del todo correcta.
Para empezar, una cadena es un tipo de enlace, por lo que los primeros cuatro bytes contienen SyncBlockIndex y los siguientes cuatro bytes contienen el puntero de tipo.
Tamaño de la cadena =4 + 4 +...
Como dije anteriormente, la longitud de la cadena se almacena en el búfer. Es un campo de tipo int, por lo que necesitamos agregar otros 4 bytes.
Tamaño de la cadena =4 + 4 + 4 + …
Para pasar una cadena al código nativo rápidamente (sin copiar), el terminador nulo se encuentra al final de cada cadena que ocupa 2 bytes. Por lo tanto,
Tamaño de la cadena =4 + 4 + 4 + 2 +...
Solo queda recordar que cada carácter de una cadena está en la codificación UTF-16 y también ocupa 2 bytes. Por lo tanto:
Tamaño de la cadena =4 + 4 + 4 + 2 + 2 * longitud =14 + 2 * longitud
Una cosa más y listo. La memoria asignada por el administrador de memoria en CLR es múltiplo de 4 bytes (4, 8, 12, 16, 20, 24, …). Entonces, si la longitud de la cadena toma 34 bytes en total, se asignarán 36 bytes. Necesitamos redondear nuestro valor al número mayor más cercano que sea múltiplo de cuatro. Para esto, necesitamos:
Tamaño de cadena =4 * ((14 + 2 * longitud + 3) / 4) (división de enteros)
La cuestión de las versiones :hasta .NET v4, había un m_arrayLength adicional campo del tipo int en la clase String que tomó 4 bytes. Este campo es una longitud real del búfer asignado para una cadena, incluido el terminador nulo, es decir, tiene una longitud + 1. En .NET 4.0, este campo se eliminó de la clase. Como resultado, un objeto de tipo cadena ocupa 4 bytes menos.
El tamaño de una cadena vacía sin m_arrayLength (es decir, en .Net 4.0 y superior) es igual a =4 + 4 + 4 + 2 =14 bytes, y con este campo (es decir, inferior a .Net 4.0), su tamaño es igual a =4 + 4 + 4 + 4 + 2 =18 bytes Si redondeamos de 4 bytes, el tamaño será de 16 y 20 bytes, respectivamente.
Aspectos de cadena
Entonces, consideramos la representación de las cadenas y el tamaño que toman en la memoria. Ahora, hablemos de sus peculiaridades.
Los aspectos básicos de las cadenas en .NET son los siguientes:
- Las cadenas son tipos de referencia.
- Las cadenas son inmutables. Una vez creada, una cadena no se puede modificar (por medios justos). Cada llamada del método de esta clase devuelve una nueva cadena, mientras que la cadena anterior se convierte en presa del recolector de basura.
- Las cadenas redefinen el método Object.Equals. Como resultado, el método compara valores de caracteres en cadenas, no valores de enlace.
Consideremos cada punto en detalle.
Las cadenas son tipos de referencia
Las cadenas son tipos de referencia reales. Es decir, siempre se encuentran en el montón. Muchos de nosotros los confundimos con tipos de valor, ya que se comportan de la misma manera. Por ejemplo, son inmutables y su comparación se realiza por valor, no por referencias, pero hay que tener en cuenta que es un tipo de referencia.
Las cadenas son inmutables
- Las cadenas son inmutables por un propósito. La inmutabilidad de cadenas tiene varios beneficios:
- El tipo de cadena es seguro para subprocesos, ya que ni un solo subproceso puede modificar el contenido de una cadena.
- El uso de cadenas inmutables conduce a una disminución de la carga de memoria, ya que no es necesario almacenar 2 instancias de la misma cadena. Como resultado, se gasta menos memoria y la comparación se realiza más rápido, ya que solo se comparan las referencias. En .NET, este mecanismo se llama string interning (grupo de cadenas). Hablaremos de ello un poco más tarde.
- Al pasar un parámetro inmutable a un método, podemos dejar de preocuparnos de que se modifique (si no se pasó como referencia o fuera, por supuesto).
Las estructuras de datos se pueden dividir en dos tipos:efímeras y persistentes. Las estructuras de datos efímeros almacenan solo sus últimas versiones. Las estructuras de datos persistentes guardan todas sus versiones anteriores durante la modificación. Estos últimos son, de hecho, inmutables, ya que sus operaciones no modifican la estructura en el sitio. En su lugar, devuelven una nueva estructura que se basa en la anterior.
Dado el hecho de que las cadenas son inmutables, podrían ser persistentes, pero no lo son. Las cadenas son efímeras en .Net.
A modo de comparación, tomemos cadenas de Java. Son inmutables, como en .NET, pero además son persistentes. La implementación de la clase String en Java tiene el siguiente aspecto:
public final class String
{
private final char value[];
private final int offset;
private final int count;
private int hash;
.....
}
Además de los 8 bytes en el encabezado del objeto, incluida una referencia al tipo y una referencia a un objeto de sincronización, las cadenas contienen los siguientes campos:
- Una referencia a una matriz de caracteres;
- Un índice del primer carácter de la cadena en la matriz char (desplazamiento desde el principio)
- El número de caracteres en la cadena;
- El código hash calculado después de llamar primero al HashCode() método.
Las cadenas en Java ocupan más memoria que en .NET, ya que contienen campos adicionales que les permiten ser persistentes. Debido a la persistencia, la ejecución de String.substring() método en Java toma O(1) , ya que no requiere la copia de cadenas como en .NET, donde la ejecución de este método toma O(n) .
Implementación del método String.substring() en Java:
public String substring(int beginIndex, int endIndex)
{
if (beginIndex < 0) throw new StringIndexOutOfBoundsException(beginIndex); if (endIndex > count)
throw new StringIndexOutOfBoundsException(endIndex);
if (beginIndex > endIndex)
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
return ((beginIndex == 0) && (endIndex == count)) ? this : new String(offset + beginIndex, endIndex - beginIndex, value);
}
public String(int offset, int count, char value[])
{
this.value = value;
this.offset = offset;
this.count = count;
} Sin embargo, si una cadena de origen es lo suficientemente grande y la subcadena recortada tiene varios caracteres de largo, la matriz completa de caracteres de la cadena inicial estará pendiente en la memoria hasta que haya una referencia a la subcadena. O bien, si serializa la subcadena recibida por medios estándar y la pasa por la red, se serializará toda la matriz original y la cantidad de bytes que se pasan por la red será grande. Por lo tanto, en lugar del código
s =ss.subcadena(3)
se puede utilizar el siguiente código:
s =nueva Cadena(ss.subcadena(3)),
Este código no almacenará la referencia a la matriz de caracteres de la cadena de origen. En cambio, copiará solo la parte realmente utilizada de la matriz. Por cierto, si llamamos a este constructor en una cadena cuya longitud es igual a la longitud de la matriz de caracteres, no se realizará la copia. En su lugar, se usará la referencia a la matriz original.
Al final resultó que, la implementación del tipo de cadena se ha cambiado en la última versión de Java. Ahora, no hay campos de desplazamiento y longitud en la clase. El nuevo hash32 (con un algoritmo hash diferente) se ha introducido en su lugar. Esto significa que las cadenas ya no son persistentes. Ahora, el String.substring El método creará una nueva cadena cada vez.
String redefine Onbject.Equals
La clase de cadena redefine el método Object.Equals. Como resultado, la comparación tiene lugar, pero no por referencia, sino por valor. Supongo que los desarrolladores están agradecidos con los creadores de la clase String por redefinir el operador ==, ya que el código que usa ==para la comparación de cadenas parece más profundo que la llamada al método.
if (s1 == s2)
Comparado con
if (s1.Equals(s2))
Por cierto, en Java, el operador ==compara por referencia. Si necesita comparar cadenas por carácter, debemos usar el método string.equals().
Pasantía en cuerdas
Finalmente, consideremos la pasantía de cuerdas. Echemos un vistazo a un ejemplo simple:un código que invierte una cadena.
var s = "Strings are immutuble";
int length = s.Length;
for (int i = 0; i < length / 2; i++)
{
var c = s[i];
s[i] = s[length - i - 1];
s[length - i - 1] = c;
} Obviamente, este código no se puede compilar. El compilador arrojará errores para estas cadenas, ya que tratamos de modificar el contenido de la cadena. Cualquier método de la clase String devuelve una nueva instancia de la cadena, en lugar de su modificación de contenido.
La cadena se puede modificar, pero necesitaremos usar el código inseguro. Consideremos el siguiente ejemplo:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
} Después de la ejecución de este código, elbatummi era sgnirtS se escribirá en la cadena, como se esperaba. La mutabilidad de las cadenas conduce a un caso elegante relacionado con la interconexión de cadenas.
Pasantía de cuerdas es un mecanismo donde los literales similares se representan en la memoria como un solo objeto.
En resumen, el objetivo de la internación de cadenas es el siguiente:hay una sola tabla interna con hash dentro de un proceso (no dentro de un dominio de aplicación), donde las cadenas son sus claves y los valores son referencias a ellas. Durante la compilación JIT, las cadenas literales se colocan en una tabla secuencialmente (cada cadena en una tabla se puede encontrar solo una vez). Durante la ejecución, las referencias a cadenas literales se asignan desde esta tabla. Durante la ejecución, podemos colocar una cadena en la tabla interna con String.Intern método. Además, podemos verificar la disponibilidad de una cadena en la tabla interna usando String.IsInterned método.
var s1 = "habrahabr"; var s2 = "habrahabr"; var s3 = "habra" + "habr"; Console.WriteLine(object.ReferenceEquals(s1, s2));//true Console.WriteLine(object.ReferenceEquals(s1, s3));//true
Tenga en cuenta que solo los literales de cadena están internados de forma predeterminada. Dado que la tabla interna con hash se utiliza para la implementación interna, la búsqueda en esta tabla se realiza durante la compilación JIT. Este proceso lleva algún tiempo. Entonces, si todas las cadenas están internas, reducirá la optimización a cero. Durante la compilación en código IL, el compilador concatena todas las cadenas literales, ya que no es necesario almacenarlas en partes. Por lo tanto, la segunda igualdad devuelve verdadero .
Ahora, volvamos a nuestro caso. Considere el siguiente código:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
}
Console.WriteLine("Strings are immutable"); Parece que todo es bastante obvio y el código debería devolver Las cadenas son inmutables . Sin embargo, ¡no es así! El código devuelve elbatummi era sgnirtS . Sucede exactamente debido a la internación. Cuando modificamos cadenas, modificamos su contenido, y como es literal, se interna y representa por una sola instancia de la cadena.
Podemos abandonar la interconexión de cadenas si aplicamos el CompilationRelaxationsAttribute atribuye a la asamblea. Este atributo controla la precisión del código creado por el compilador JIT del entorno CLR. El constructor de este atributo acepta CompilationRelaxations enumeración, que actualmente incluye solo CompilationRelaxations.NoStringInterning . Como resultado, el montaje se marca como el que no requiere internamiento.
Por cierto, este atributo no se procesa en .NET Framework v1.0. Por eso, era imposible deshabilitar la internación. A partir de la versión 2, mscorlib ensamblado está marcado con este atributo. Entonces, resulta que las cadenas en .NET se pueden modificar con el código inseguro.
¿Qué pasa si nos olvidamos de lo inseguro?
Da la casualidad de que podemos modificar el contenido de la cadena sin el código inseguro. En su lugar, podemos usar el mecanismo de reflexión. Este truco tuvo éxito en .NET hasta la versión 2.0. Posteriormente, los desarrolladores de la clase String nos privaron de esta oportunidad. En .NET 2.0, la clase String tiene dos métodos internos:SetChar para verificación de límites y InternalSetCharNoBoundsCheck que no hace verificación de límites. Estos métodos establecen el carácter especificado por un cierto índice. La implementación de los métodos se ve de la siguiente manera:
internal unsafe void SetChar(int index, char value)
{
if ((uint)index >= (uint)this.Length)
throw new ArgumentOutOfRangeException("index", Environment.GetResourceString("ArgumentOutOfRange_Index"));
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
}
internal unsafe void InternalSetCharNoBoundsCheck (int index, char value)
{
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
} Por lo tanto, podemos modificar el contenido de la cadena sin código no seguro con la ayuda del siguiente código:
var s = "Strings are immutable";
int length = s.Length;
var method = typeof(string).GetMethod("InternalSetCharNoBoundsCheck", BindingFlags.Instance | BindingFlags.NonPublic);
for (int i = 0; i < length / 2; i++)
{
var temp = s[i];
method.Invoke(s, new object[] { i, s[length - i - 1] });
method.Invoke(s, new object[] { length - i - 1, temp });
}
Console.WriteLine("Strings are immutable");
Como era de esperar, el código devuelve elbatummi era sgnirtS .
La cuestión de las versiones :en diferentes versiones de .NET Framework, string.Empty puede integrarse o no. Consideremos el siguiente código:
string str1 = String.Empty;
StringBuilder sb = new StringBuilder().Append(String.Empty);
string str2 = String.Intern(sb.ToString());
if (object.ReferenceEquals(str1, str2))
Console.WriteLine("Equal");
else
Console.WriteLine("Not Equal"); En .NET Framework 1.0, .NET Framework 1.1 y .NET Framework 3.5 con el Service Pack 1 (SP1), str1 y str2 no son iguales Actualmente, string.Empty no está internado.
Aspectos del rendimiento
Hay un efecto secundario negativo de la pasantía. La cuestión es que la referencia a un objeto interno de cadena almacenado por CLR se puede guardar incluso después del final del trabajo de la aplicación e incluso después del final del trabajo del dominio de la aplicación. Por lo tanto, es mejor omitir el uso de cadenas literales grandes. Si aún es necesario, la internación debe deshabilitarse aplicando las Relajaciones de compilación atributo al ensamblado.