¿Qué hace la indexación?
La indexación es la forma de colocar una tabla desordenada en un orden que maximizará la eficiencia de la consulta durante la búsqueda.
Cuando una tabla no está indexada, es probable que la consulta no distinga el orden de las filas como optimizado de ninguna manera y, por lo tanto, su consulta tendrá que buscar en las filas de forma lineal. En otras palabras, las consultas tendrán que buscar en cada fila para encontrar las filas que coincidan con las condiciones. Como puedes imaginar, esto puede llevar mucho tiempo. Mirar a través de cada fila no es muy eficiente.
Por ejemplo, la siguiente tabla representa una tabla en una fuente de datos ficticia, que está completamente desordenada.
| id_compañía | unidad | costo_por_unidad |
|---|---|---|
| 10 | 12 | 1.15 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 16 | 12 | 1.31 |
| 10 | 12 | 1.15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1.36 |
| 12 | 12 | 1.05 |
| 20 | 6 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 14 | 24 | 1.05 |
Si tuviéramos que ejecutar la siguiente consulta:
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18
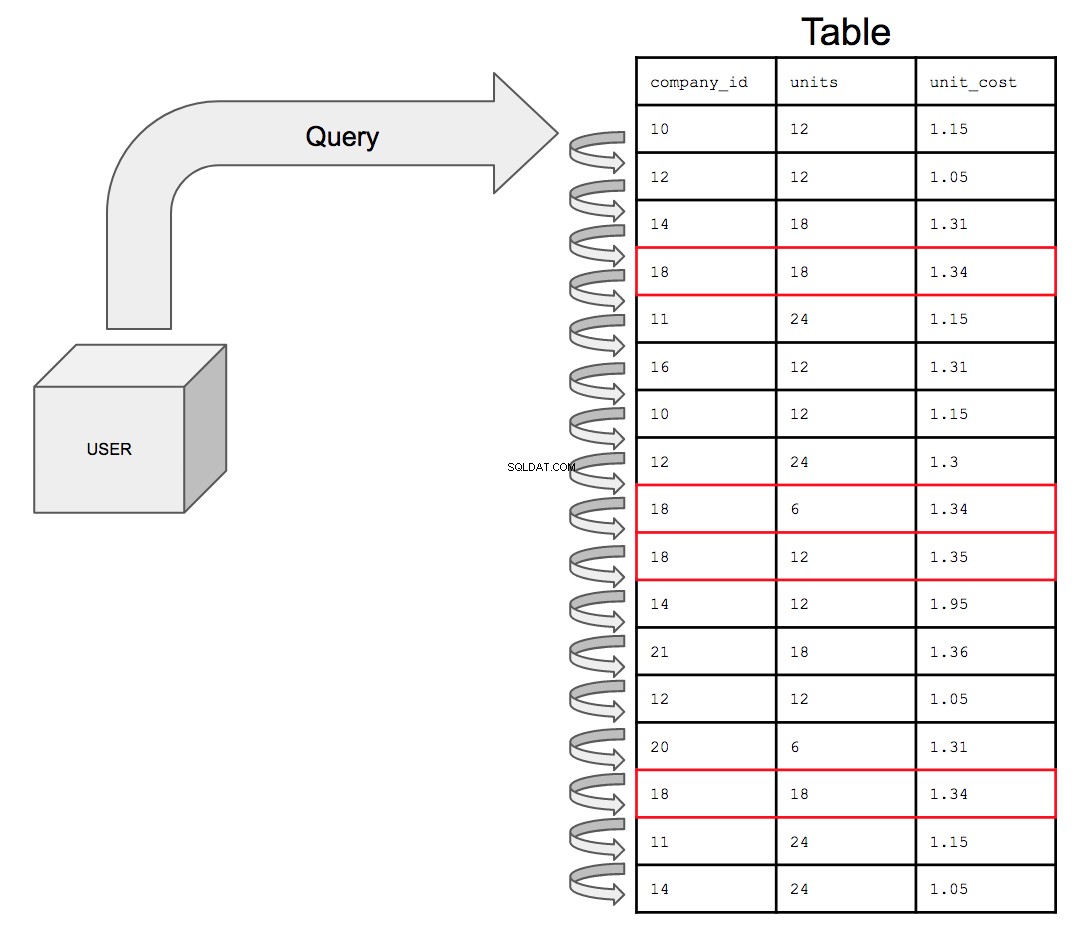
La base de datos tendría que buscar en las 17 filas en el orden en que aparecen en la tabla, de arriba a abajo, una a la vez. Entonces, para buscar todas las instancias potenciales de company_id número 18, la base de datos debe buscar en toda la tabla todas las apariciones de 18 en company_id columna.
Esto solo consumirá más y más tiempo a medida que aumente el tamaño de la tabla. A medida que aumenta la sofisticación de los datos, lo que eventualmente podría suceder es que una tabla con mil millones de filas se una a otra tabla con mil millones de filas; la consulta ahora tiene que buscar el doble de filas, lo que cuesta el doble de tiempo.
Puede ver cómo esto se vuelve problemático en nuestro mundo siempre saturado de datos. Las tablas aumentan de tamaño y la búsqueda aumenta el tiempo de ejecución.
Consultar una tabla no indexada, si se presenta visualmente, se vería así:
Lo que hace la indexación es configurar la columna en la que se encuentran las condiciones de búsqueda en un orden ordenado para ayudar a optimizar el rendimiento de las consultas.
Con un índice en company_id columna, la tabla, esencialmente, "se vería" así:
| id_compañía | unidad | costo_por_unidad |
|---|---|---|
| 10 | 12 | 1.15 |
| 10 | 12 | 1.15 |
| 11 | 24 | 1.15 |
| 11 | 24 | 1.15 |
| 12 | 12 | 1.05 |
| 12 | 24 | 1.3 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1.05 |
| 16 | 12 | 1.31 |
| 18 | 18 | 1.34 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 18 | 18 | 1.34 |
| 20 | 6 | 1.31 |
| 21 | 18 | 1.36 |
Ahora, la base de datos puede buscar company_id número 18 y devolver todas las columnas solicitadas para esa fila y luego pasar a la siguiente fila. Si el comapny_id de la siguiente fila el número también es 18, entonces devolverá todas las columnas solicitadas en la consulta. Si el company_id de la fila siguiente es 20, la consulta sabe que debe dejar de buscar y la consulta finalizará.
¿Cómo funciona la indexación?
En realidad, la tabla de la base de datos no se reordena cada vez que cambian las condiciones de la consulta para optimizar el rendimiento de la consulta:eso sería poco realista. En realidad, lo que sucede es que el índice hace que la base de datos cree una estructura de datos. Es muy probable que el tipo de estructura de datos sea un árbol B. Si bien las ventajas del B-Tree son numerosas, la principal ventaja para nuestros propósitos es que se puede ordenar. Cuando la estructura de datos se ordena en orden, hace que nuestra búsqueda sea más eficiente por las razones obvias que señalamos anteriormente.
Cuando el índice crea una estructura de datos en una columna específica, es importante tener en cuenta que no se almacena ninguna otra columna en la estructura de datos. Nuestra estructura de datos para la tabla anterior solo contendrá el company_id números. Unidades y unit_cost no se mantendrá en la estructura de datos.
¿Cómo sabe la base de datos qué otros campos de la tabla devolver?
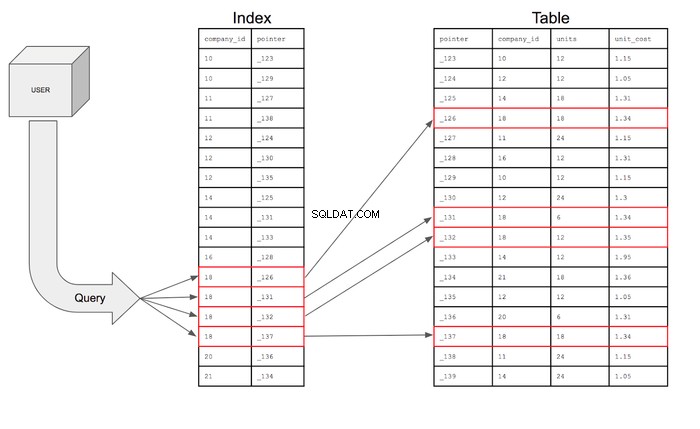
Los índices de la base de datos también almacenarán punteros que son simplemente información de referencia para la ubicación de la información adicional en la memoria. Básicamente, el índice contiene el company_id y la dirección particular de esa fila en el disco de memoria. El índice en realidad se verá así:
| id_compañía | puntero |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
Con ese índice, la consulta puede buscar solo las filas en company_id columna que tiene 18 y luego usar el puntero puede ir a la tabla para encontrar la fila específica donde vive ese puntero. Luego, la consulta puede ir a la tabla para recuperar los campos de las columnas solicitadas para las filas que cumplen las condiciones.
Si la búsqueda se presentara visualmente, se vería así:
Resumen
- La indexación agrega una estructura de datos con columnas para las condiciones de búsqueda y un puntero
- El puntero es la dirección en el disco de memoria de la fila con el resto de la información
- La estructura de datos del índice se ordena para optimizar la eficiencia de las consultas
- La consulta busca la fila específica en el índice; el índice se refiere al puntero que encontrará el resto de la información.
- El índice reduce el número de filas que la consulta debe buscar de 17 a 4.