En nuestros blogs anteriores, justificamos por qué necesita una conmutación por error de la base de datos y explicamos cómo funciona un mecanismo de conmutación por error. Estoy compartiendo esto en caso de que tenga preguntas sobre por qué debería configurar un mecanismo de conmutación por error para su base de datos MySQL. Si es así, lea nuestras publicaciones de blog anteriores.
Cómo configurar la conmutación por error automática
La ventaja de usar MySQL o MariaDB para administrar automáticamente su conmutación por error es que hay herramientas disponibles que puede usar e implementar en su entorno. Desde los de código abierto hasta las soluciones de nivel empresarial. La mayoría de las herramientas no solo tienen capacidad de conmutación por error, sino que también cuentan con otras funciones, como conmutación, supervisión y funciones avanzadas que pueden ofrecer más capacidades de administración para su clúster de base de datos MySQL. A continuación, repasaremos los más comunes que puede usar.
Uso de MHA (alta disponibilidad principal)
Hemos abordado este tema con MHA con sus problemas más comunes y cómo solucionarlos. También hemos comparado MHA con MRM o con MaxScale.
La configuración con MHA para alta disponibilidad puede no ser fácil, pero es eficiente de usar y flexible, ya que hay parámetros ajustables que puede definir para personalizar su conmutación por error. MHA ha sido probado y utilizado. Pero a medida que avanza la tecnología, MHA se ha quedado atrás, ya que no es compatible con GTID para MariaDB y no ha estado impulsando ninguna actualización durante los últimos 2 o 3 años.
Al ejecutar el script masterha_manager,
masterha_manager --conf=/etc/app1.cnfDonde una muestra /etc/app1.cnf se verá como sigue,
[server default]
user=cmon
password=pass
ssh_user=root
# working directory on the manager
manager_workdir=/var/log/masterha/app1
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=node1
candidate_master=1
[server2]
hostname=node2
candidate_master=1
[server3]
hostname=node3
no_master=1Parámetros como no_master y Candidate_master serán cruciales cuando establezca la lista blanca de los nodos deseados para que sean su maestro de destino y los nodos que no desea que sean maestros.
Una vez configurado, está listo para tener conmutación por error para su base de datos MySQL en caso de que ocurra una falla en la principal o maestra. El script masterha_manager administra la conmutación por error (automática o manual), toma decisiones sobre cuándo y dónde realizar la conmutación por error y administra la recuperación del esclavo durante la promoción del maestro candidato para aplicar registros de retransmisión diferencial. Si la base de datos maestra deja de funcionar, MHA Manager se coordinará con el agente de nodo de MHA, ya que aplica registros de retransmisión diferencial a los esclavos que no tienen los últimos eventos binlog del maestro.
Consulte lo que hace el agente de nodo MHA y los scripts involucrados. Básicamente, es la secuencia de comandos que invocará MHA Manager cuando se produzca una conmutación por error. Esperará el mandato de MHA Manager mientras busca el último esclavo que contiene los eventos binlog y copia los eventos faltantes del esclavo usando scp y se los aplica a sí mismo. Como se mencionó, aplica registros de retransmisión, purga registros de retransmisión o guarda registros binarios.
Si desea saber más acerca de los parámetros ajustables y cómo personalizar su administración de conmutación por error, consulte la página wiki de Parámetros para MHA.
Uso del orquestador
Orchestrator es una herramienta de administración de replicación y alta disponibilidad de MySQL y MariaDB. Es publicado por Shlomi Noach bajo los términos de la Licencia Apache, versión 2.0. Este es un software de código abierto y maneja la conmutación por error automática, pero hay muchas cosas que puede personalizar o hacer para administrar su base de datos MySQL/MariaDB además de la recuperación o la conmutación por error automática.
Instalar Orchestrator puede ser fácil o directo. Una vez que haya descargado los paquetes específicos necesarios para su entorno de destino, estará listo para registrar el clúster y los nodos para que los supervise Orchestrator. Proporciona una interfaz de usuario para la cual es muy fácil de administrar, pero tiene muchos parámetros ajustables o un conjunto de comandos que puede usar para lograr su administración de conmutación por error.
Supongamos que finalmente configuró y registró el clúster agregando nuestro nodo principal o maestro mediante el siguiente comando,
$ orchestrator -c discover -i pupnode21:3306
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: pupnode21
2021-01-07 12:32:31 DEBUG Cache hostname resolve pupnode21 as pupnode21
2021-01-07 12:32:31 DEBUG Connected to orchestrator backend: orchestrator:[email protected](127.0.0.1:3306)/orchestrator?timeout=1s
2021-01-07 12:32:31 DEBUG Orchestrator pool SetMaxOpenConns: 128
2021-01-07 12:32:31 DEBUG Initializing orchestrator
2021-01-07 12:32:31 INFO Connecting to backend 127.0.0.1:3306: maxConnections: 128, maxIdleConns: 32
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.222
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.222 as 192.168.40.222
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.223
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.223 as 192.168.40.223
pupnode21:3306Ahora, hemos agregado nuestro clúster.
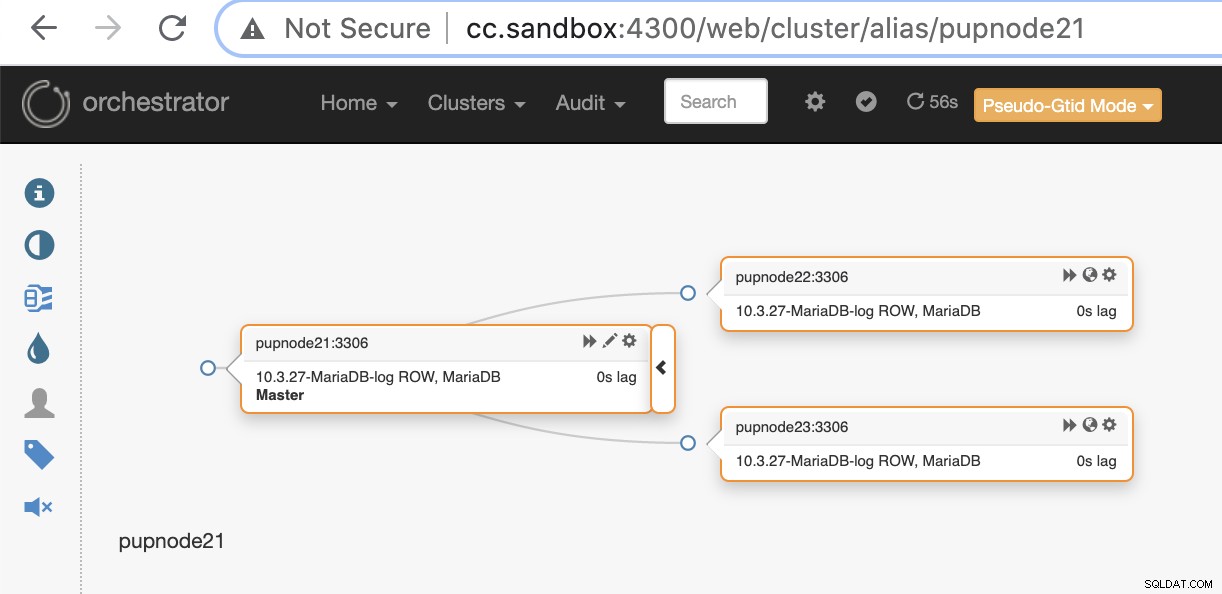
Si un nodo principal falla (falla de hardware o falla), Orchestrator detectar y encontrar el nodo más avanzado para promoverlo como nodo principal o principal.
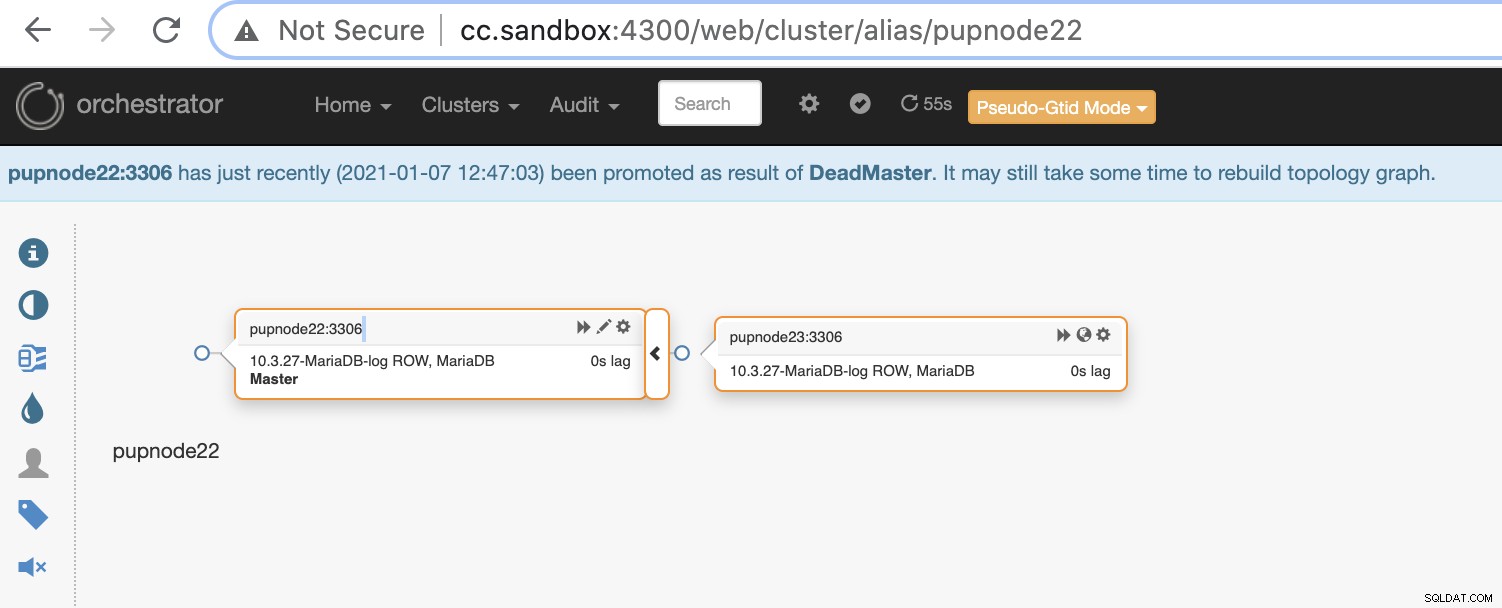
Ahora, tenemos dos nodos restantes en el clúster mientras que el principal está inactivo .
$ orchestrator-client -c topology -i pupnode21:3306
pupnode21:3306 [unknown,invalid,10.3.27-MariaDB-log,rw,ROW,>>,downtimed]
$ orchestrator-client -c topology -i pupnode22:3306
pupnode22:3306 [0s,ok,10.3.27-MariaDB-log,rw,ROW,>>]
+ pupnode23:3306 [0s,ok,10.3.27-MariaDB-log,ro,ROW,>>,GTID]Usando MaxScale
MariaDB MaxScale ha sido compatible como equilibrador de carga de base de datos. A lo largo de los años, MaxScale ha crecido y madurado, se ha ampliado con varias características ricas y eso incluye la conmutación por error automática. Desde que se lanzó MariaDB MaxScale 2.2, presenta varias características nuevas, incluida la administración de conmutación por error del clúster de replicación. Puede leer nuestro blog anterior sobre el mecanismo de conmutación por error de MaxScale.
El uso de MaxScale está bajo BSL, aunque el software está disponible gratuitamente, pero requiere que al menos compre el servicio con MariaDB. Puede que no sea adecuado, pero en caso de que haya adquirido los servicios empresariales de MariaDB, esto puede ser una gran ventaja si necesita administración de conmutación por error y sus otras funciones.
La instalación de MaxScale es fácil, pero establecer la configuración requerida y definir sus parámetros no lo es, y requiere que usted comprenda el software. Puede consultar su guía de configuración.
Para una implementación rápida y rápida, puede usar ClusterControl para instalar MaxScale en su entorno MySQL/MariaDB existente.
Una vez instalada, la configuración de su base de datos de Moodle se puede realizar apuntando su host a la IP de MaxScale o nombre de host y el puerto de lectura y escritura. Por ejemplo,
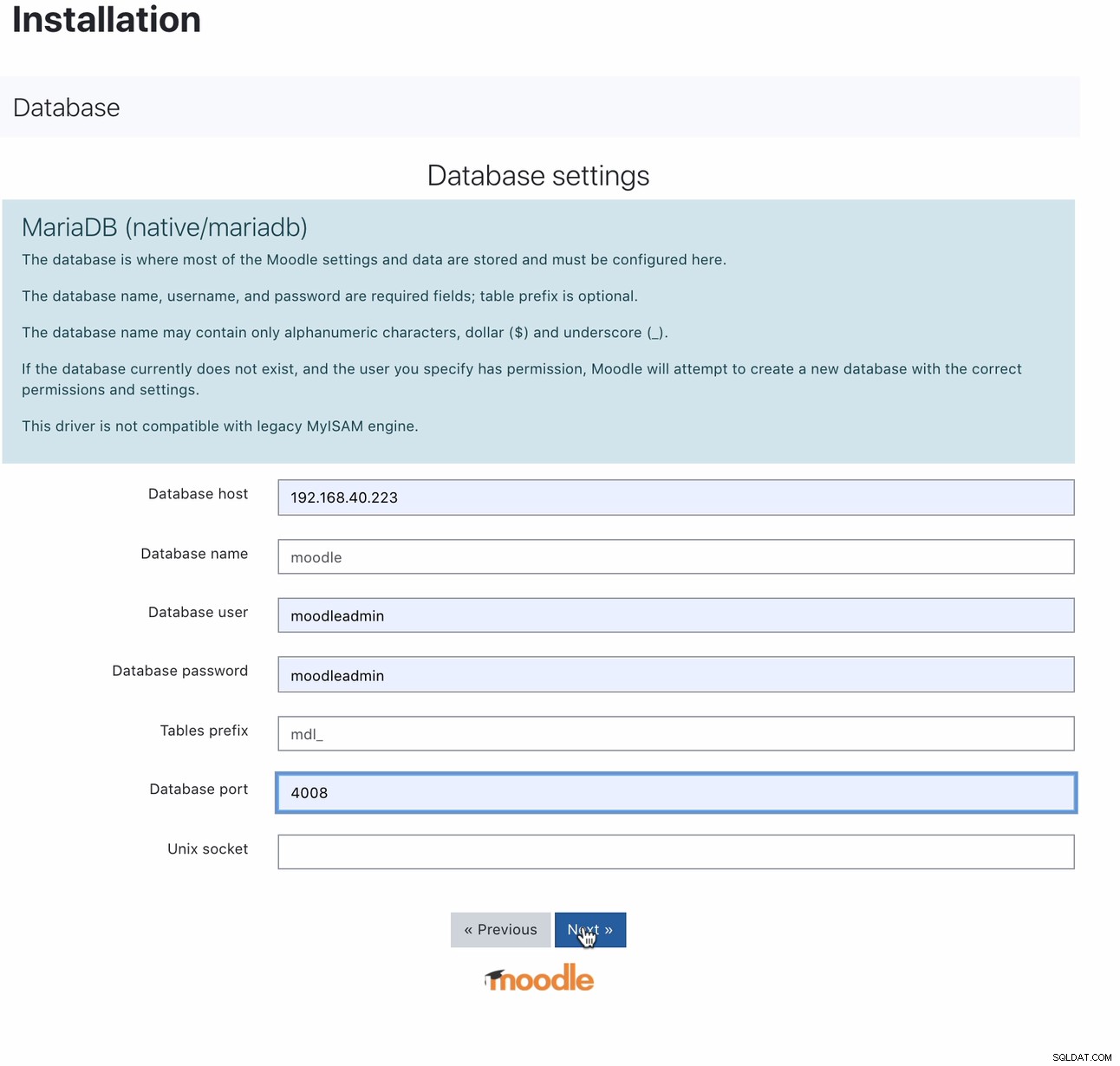
Para qué puerto 4008 es su lectura-escritura para su servicio de escucha. Por ejemplo, aquí está la siguiente configuración de escucha y servicio para mi MaxScale.
$ cat maxscale.cnf.d/rw-listener.cnf
[rw-listener]
type=listener
protocol=mariadbclient
service=rw-service
address=0.0.0.0
port=4008
authenticator=MySQLAuth
$ cat maxscale.cnf.d/rw-service.cnf
[rw-service]
type=service
servers=DB_123,DB_122,DB_124
router=readwritesplit
user=maxscale_adm
password=42BBD2A4DC1BF9BE05C41A71DEEBDB70
max_slave_connections=100%
max_sescmd_history=15000000
causal_reads=true
causal_reads_timeout=10
transaction_replay=true
transaction_replay_max_size=32Mi
delayed_retry=true
master_reconnection=true
max_connections=0
connection_timeout=0
use_sql_variables_in=master
master_accept_reads=true
disable_sescmd_history=falseMientras esté en la configuración de su monitor, no debe olvidar habilitar la conmutación por error automática o también habilitar la reincorporación automática si desea que el maestro anterior no pueda reincorporarse automáticamente cuando vuelva a estar en línea. Va así,
$ egrep -r 'auto|^\[' maxscale.cnf.d/replication_monitor.cnf
[replication_monitor]
auto_failover=true
auto_rejoin=1Tome nota de que las variables que he indicado no son para uso en producción sino solo para esta publicación de blog y propósitos de prueba. Lo bueno de MaxScale es que, una vez que el principal o maestro deja de funcionar, MaxScale es lo suficientemente inteligente como para promover al candidato ideal o mejor para asumir el rol de maestro. Por lo tanto, no es necesario cambiar su IP y puerto, ya que hemos utilizado el host/IP de nuestro nodo MaxScale y su puerto como nuestro punto final una vez que el maestro deja de funcionar. Por ejemplo,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Nodo DB_123 que apunta a 192.168.40.221 es el maestro actual. Terminar el nodo DB_123 activará MaxScale para realizar una conmutación por error y se verá así,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Down │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Si bien, nuestra base de datos de Moodle aún está en funcionamiento, ya que MaxScale apunta al último maestro que se promocionó.
$ mysql -hmaxscale.local.domain -umoodleuser -pmoodlepassword -P4008
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 9
Server version: 10.3.27-MariaDB-log MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> select @@hostname;
+------------+
| @@hostname |
+------------+
| 192.168.40.222 |
+------------+
1 row in set (0.001 sec)Uso de ClusterControl
ClusterControl se puede descargar gratuitamente y ofrece licencias para Community, Advance y Enterprise. La conmutación por error automática solo está disponible en Advance y Enterprise. La conmutación por error automática está cubierta por nuestra función de recuperación automática que intenta recuperar un clúster fallido o un nodo fallido. Si desea obtener más detalles sobre cómo realizar esto, consulte nuestra publicación anterior Cómo realiza ClusterControl la recuperación automática de bases de datos y la conmutación por error. Ofrece parámetros ajustables que son muy convenientes y fáciles de usar. Lea también nuestra publicación anterior sobre cómo automatizar la conmutación por error de la base de datos con ClusterControl.
La administración de la conmutación por error automática para su base de datos de Moodle debe requerir al menos una IP virtual (VIP) como punto final para su cliente de aplicación de Moodle que interactúa con el backend de su base de datos. Para hacer esto, puede implementar Keepalived con HAProxy (o ProxySQL, depende de su elección de equilibrador de carga) encima. En este caso, el extremo de su base de datos de Moodle apuntará a la IP virtual, que básicamente es asignada por Keepalived una vez que la haya implementado, tal como le mostramos anteriormente al configurar MaxScale. También puede consultar este blog sobre cómo hacerlo.
Como se mencionó anteriormente, hay parámetros ajustables disponibles que puede configurar a través de /etc/cmon.d/cmon_
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- Replication_post_failover_script
- replication_post_unsuccessful_failover_script
- replicación_pre_failover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
ClusterControl es muy flexible cuando administra la conmutación por error, por lo que puede realizar algunas tareas previas o posteriores a la conmutación por error.
Conclusión
Hay otras excelentes opciones al configurar y administrar automáticamente su conmutación por error para su base de datos MySQL para Moodle. Depende de su presupuesto y en lo que probablemente tenga que gastar dinero. El uso de los de código abierto requiere experiencia y requiere múltiples pruebas para familiarizarse, ya que no hay soporte que pueda ejecutar cuando necesita ayuda que no sea la comunidad. Las soluciones empresariales tienen un precio, pero le ofrecen soporte y facilidad, ya que se puede disminuir el trabajo que consume mucho tiempo. Tenga en cuenta que si la conmutación por error se usa por error, puede dañar su base de datos si no se maneja y administra adecuadamente. Concéntrese en lo que es más importante y cómo es capaz de las soluciones que está utilizando para administrar la conmutación por error de su base de datos de Moodle.