En publicaciones de blog anteriores, hemos cubierto temas para monitorear su clúster de Galera, ya sea MySQL o MariaDB. Aunque las versiones de tecnología no difieren mucho, MariaDB Cluster tiene algunos cambios importantes desde la versión 10.4.2. En esta versión, es compatible con Galera Cluster 4 y tiene algunas características nuevas excelentes que veremos en esta publicación de blog.
Para principiantes que aún no están familiarizados con MariaDB Cluster, es un clúster multimaestro virtualmente síncrono para MariaDB. Está disponible solo en Linux y solo es compatible con los motores de almacenamiento XtraDB/InnoDB (aunque hay soporte experimental para MyISAM; consulte la variable de sistema wsrep_replicate_myisam).
El software es una tecnología integrada que funciona con MariaDB Server, el parche MySQL-wsrep para MySQL Server y MariaDB Server desarrollado por Codership (compatible con sistemas operativos similares a Unix) y la biblioteca de proveedores Galera wsrep.
Puede comparar este producto con MySQL Group Replication o con MySQL InnoDB Cluster, cuyo objetivo es proporcionar alta disponibilidad. (Aunque difieren de manera diversa en los principios y enfoques para proporcionar HA).
Ahora que hemos cubierto los conceptos básicos, en este blog vamos a proporcionar consejos que consideramos útiles al monitorear su clúster de MariaDB.
Los fundamentos del clúster de MariaDB
Cuando comienza a usar MariaDB Cluster, debe identificar cuál es exactamente su propósito y por qué eligió MariaDB Cluster en primer lugar. Primero debe digerir cuáles son las características y sus beneficios al usar MariaDB Cluster. La razón para identificarlos es que son esencialmente lo que debe monitorearse y verificarse para que pueda determinar el rendimiento, las condiciones de salud normales y si se está ejecutando de acuerdo con sus planes.
Esencialmente, se identifica como ausencia de retraso de esclavo, transacciones perdidas, escalabilidad de lectura y latencias de cliente más pequeñas. Entonces pueden surgir preguntas como, ¿cómo hace que no haya retrasos en los esclavos ni transacciones perdidas? ¿Cómo hace que la lectura sea escalable o con latencias más pequeñas en el lado del cliente? Estas áreas son una de las áreas clave que debe observar y monitorear, especialmente para el uso intensivo de la producción.
Aunque el propio clúster de MariaDB se puede personalizar en consecuencia. La aplicación de cambios en el comportamiento predeterminado, como pc.weight o pc.ignore_quorum, o incluso el uso de multidifusión con UDP para una gran cantidad de nodos, puede afectar la forma en que supervisa la naturaleza de su clúster de MariaDB. Pero, por otro lado, las variables de estado más esenciales suelen ser su lado positivo aquí, sabiendo que el estado y el flujo de su clúster están funcionando bien o se está degradando y muestra un posible problema que conduce a una falla catastrófica de antemano.
Supervise siempre la actividad de su servidor (red, disco, carga, memoria y CPU)
Supervisar la actividad de su servidor también puede ser una tarea compleja si tiene una pila muy complicada que está entrelazada en la arquitectura de su base de datos. Sin embargo, para un clúster de MariaDB, siempre es mejor tener sus nodos configurados de la manera más dedicada y simple posible. Aunque eso no le impide usar todos los recursos de repuesto, a continuación se encuentran las áreas clave comunes que debe investigar.
Red
Galera Cluster 4 presenta la replicación de transmisión como una de las funciones y cambios clave con respecto a la versión anterior. Dado que la replicación de transmisión soluciona los inconvenientes que tenía en las versiones anteriores, pero le permite administrar más de 2 GB de conjuntos de escritura desde Galera Cluster 4. Esto permite que se fragmenten grandes transacciones y se recomienda habilitar esto solo durante el nivel de sesión. Esto significa que monitorear la actividad de su red es muy importante y crucial para la actividad normal de su clúster MariaDB. Esto lo ayudará a identificar qué nodo tuvo la mayor cantidad o el mayor tráfico de red según el período de tiempo.
Entonces, ¿cómo le ayudará eso a mejorar dónde se han identificado los nodos con el mayor tráfico de red? Bueno, esto le brinda margen de mejora con la topología de su base de datos o la capa arquitectónica de su clúster de base de datos. El uso de balanceadores de carga o un proxy de base de datos le permite configurar de manera proactiva el tráfico de su base de datos, especialmente al determinar qué escrituras específicas irán a un nodo específico. Digamos, de los 3 nodos, uno de ellos es más capaz de manejar consultas grandes y grandes debido a las diferencias con las especificaciones del hardware. Esto le permite administrar una mayor parte de su gasto de capital y mejorar su capacidad de planificación a medida que cambia la demanda en un período específico de tiempo.
Disco
Como la actividad de la red también es importante para el rendimiento de su disco, especialmente durante el tiempo de vaciado. También es mejor determinar el rendimiento del tiempo comprometido y la recuperación cuando se alcanza una carga máxima alta. Hay momentos en los que abastece el host de su base de datos no solo para dedicarlo a una actividad de Galera Cluster, sino también para combinarlo con otras herramientas como docker, proxies SQL como ProxySQL o MaxScale. Esto le brinda control con servidores de baja carga y le permite utilizar los recursos de repuesto disponibles que pueden utilizarse para otros fines beneficiosos, especialmente para su pila de arquitectura de base de datos. Una vez que pueda determinar qué nodo al monitorear tiene la carga más baja pero aún es capaz de administrar su utilización de E/S de disco, puede seleccionar el nodo específico mientras observa el paso del tiempo. Nuevamente, esto aún le brinda una mejor administración con su planificación de capacidad.
CPU, memoria y actividad de carga
Permítanme mencionar brevemente estas tres áreas a tener en cuenta al monitorear. En esta sección, siempre es mejor tener una mejor observabilidad de las siguientes áreas a la vez. Es más rápido y más fácil de entender, especialmente descartando un cuello de botella en el rendimiento o identificando errores que provocan que sus nodos se detengan y que también pueden afectar a los otros nodos y la posibilidad de caer en el clúster.
Entonces, ¿cómo la CPU, la memoria y la actividad de carga al monitorear ayudan a su clúster de MariaDB? Bueno, como mencioné anteriormente, esas son una de las pocas cosas que aún son un factor importante para los controles de rutina diarios. Ahora, esto también lo ayuda a identificar si se trata de ocurrencias periódicas o aleatorias. Si es periódico, podría estar relacionado con las copias de seguridad que se ejecutan en uno de sus nodos de Galera, o es una consulta masiva que requiere optimización. Por ejemplo, consultas incorrectas sin índices adecuados o uso desequilibrado de la recuperación de datos, como hacer una comparación de cadenas para una cadena tan grande. Eso puede ser innegablemente inaplicable para bases de datos de tipo OLTP como MariaDB Cluster, especialmente si es realmente la naturaleza y los requisitos de su aplicación. Utilice mejor otras herramientas analíticas como MariaDB Columnstore u otras herramientas de procesamiento analítico de terceros (Apache Spark, Kafka o MongoDB, etc.) para la recuperación de datos de cadenas grandes y/o la coincidencia de cadenas.
Entonces, con todas estas áreas clave siendo monitoreadas, la pregunta es, ¿cómo se monitoreará? Tiene que ser monitoreado al menos por minuto. Con un monitoreo refinado, es decir, por segundo de métricas colectivas, puede ser un recurso intensivo y muy codicioso en términos de sus recursos. Aunque medio minuto de colectividad es aceptable, especialmente si sus datos y RPO (objetivo de punto de recuperación) son muy bajos, por lo que necesita métricas de datos más granulares y en tiempo real. Es muy importante que pueda supervisar la imagen completa de su clúster de base de datos. Aparte de esto, también es mejor e importante que, independientemente de las métricas que esté monitoreando, tenga la herramienta adecuada para llamar su atención cuando las cosas estén en peligro o incluso solo sean advertencias. El uso de la herramienta adecuada, como ClusterControl, lo ayuda a administrar estas áreas clave que se monitorearán. Estoy usando aquí una versión gratuita o una edición comunitaria de ClusterControl y me ayuda a monitorear mis nodos sin problemas desde la instalación hasta el monitoreo de los nodos con solo unos pocos clics. Por ejemplo, vea las capturas de pantalla a continuación:

La vista es una descripción general más refinada y rápida de lo que está sucediendo actualmente. También se puede usar un gráfico más granular,
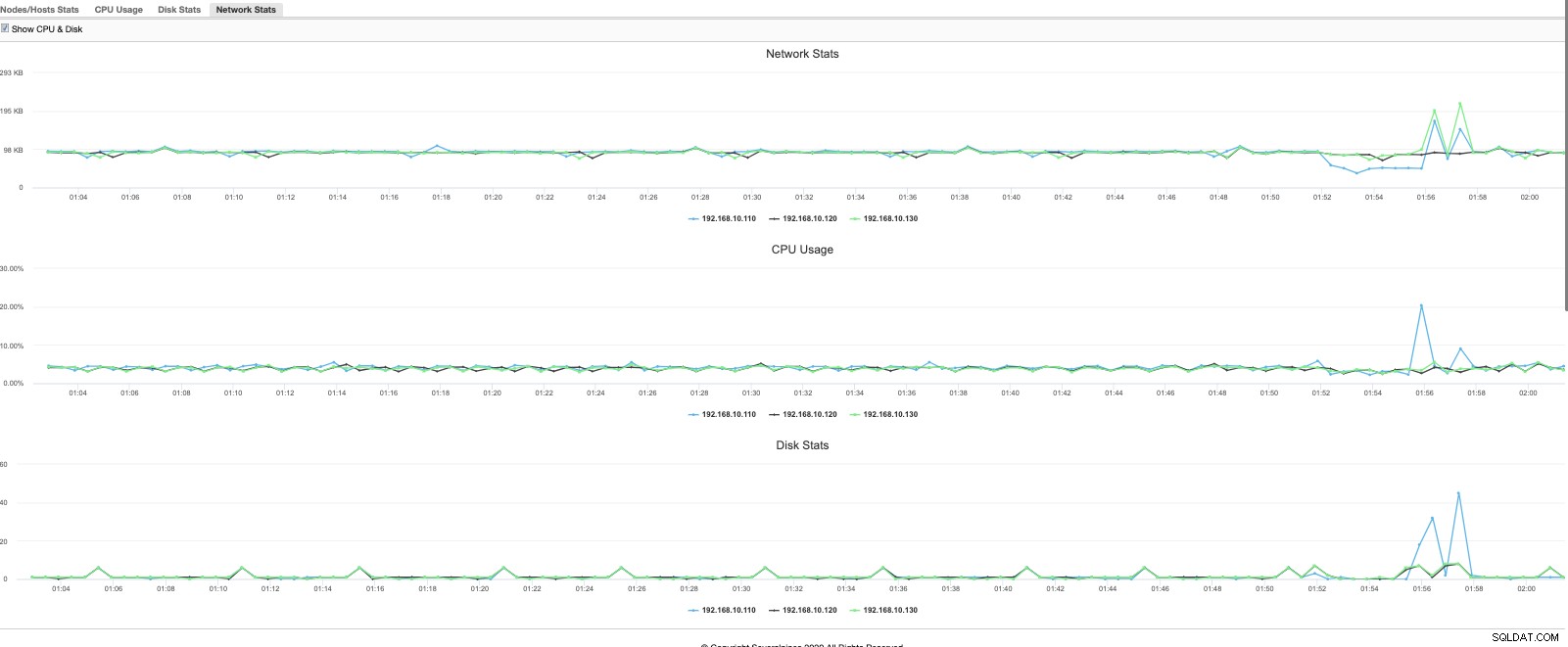
o con un modelo de datos más poderoso y rico que también admita el lenguaje de consulta puede proporcionarle un análisis del rendimiento de su clúster de MariaDB en función de datos históricos que comparen su rendimiento de manera oportuna. Por ejemplo,
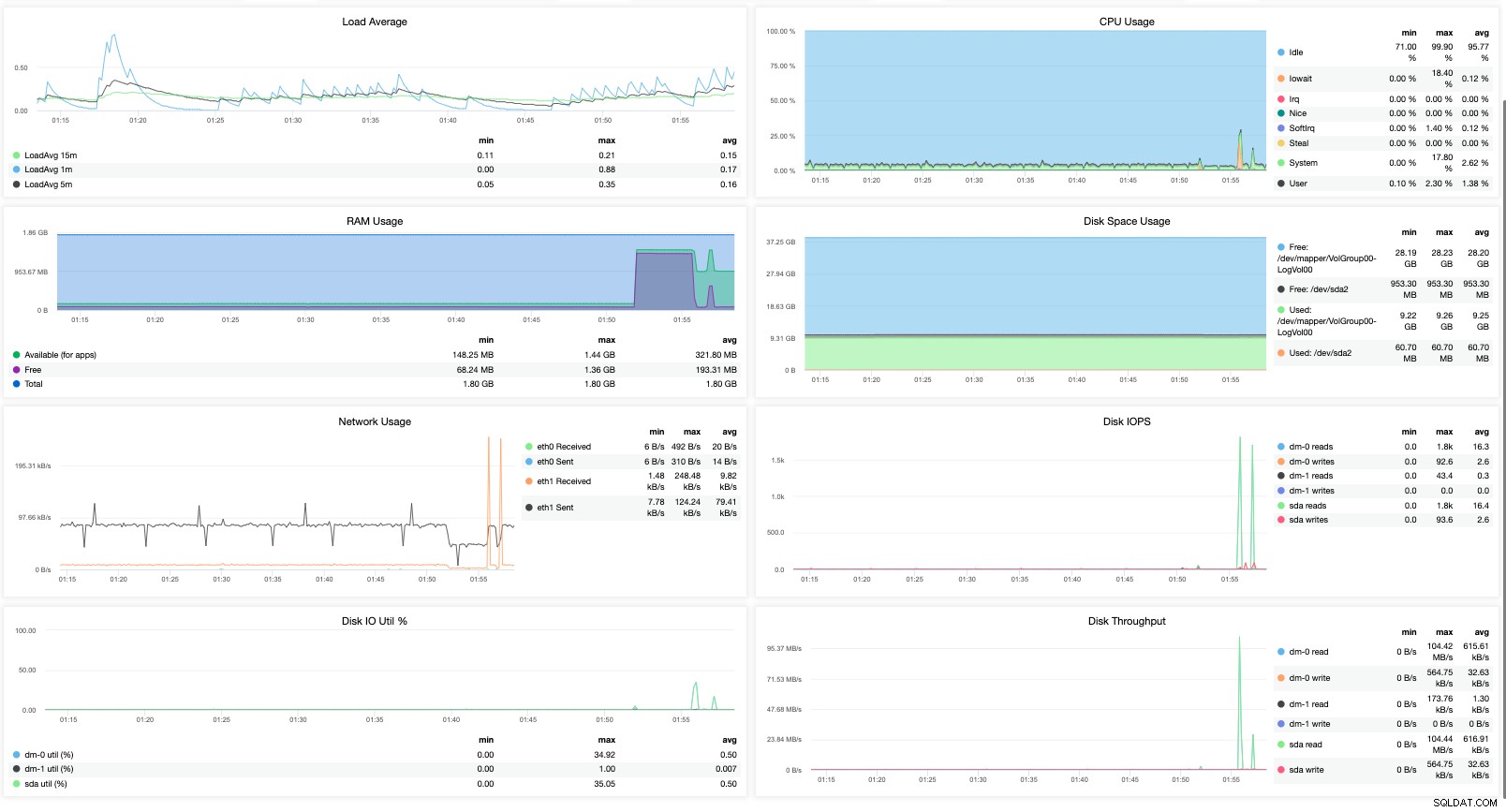
Eso solo le proporciona métricas más visibles. Entonces puede ver lo importante que es realmente tener la herramienta adecuada al monitorear su clúster de MariaDB.
Asegure el monitoreo colectivo de sus variables estadísticas del clúster de MariaDB
De vez en cuando, no puede ser inevitable que las versiones de MariaDB Cluster produzcan nuevas estadísticas para monitorear o mejorar la naturaleza del monitoreo de la base de datos al proporcionar más variables de estado y refinar valores para observar. Como mencioné anteriormente, estoy usando ClusterControl para monitorear mis nodos en este blog de ejemplo. Sin embargo, eso no significa que sea la mejor herramienta que existe. Quiero decir que PMM de Percona es muy rico cuando se trata de monitoreo colectivo para cada variable estadística que cada vez que MariaDB Cluster tiene variables estadísticas más nuevas para ofrecer, puede aprovechar esto y también cambiarlo ya que PMM es una herramienta de código abierto. Es una gran ventaja que también tenga toda la visibilidad de su clúster MariaDB, ya que cada aspecto cuenta, especialmente en una base de datos basada en producción que atiende cientos de miles de solicitudes por minuto.
Pero seamos más específicos en el problema aquí. ¿Cuáles son estas variables estadísticas a investigar? Hay muchos con los que contar para un clúster de MariaDB, pero centrándonos nuevamente en las características y los beneficios que creemos que usa el clúster de MariaDB y lo que tiene para ofrecer, entonces nos enfocaremos en eso.
Clúster Galera - Control de flujo
El control de flujo de su clúster de MariaDB le brinda una descripción general de cómo funciona el estado de la replicación en todo el clúster. El proceso de replicación en Galera Cluster utiliza un mecanismo de retroalimentación, lo que significa que envía señales a todos los nodos dentro de ese clúster y señala si el nodo debe pausar o reanudar la replicación según sus necesidades. Esto también evita que cualquier nodo se retrase demasiado mientras los demás aplican las transacciones entrantes. Así es como el control de flujo cumple su función dentro de Galera. Ahora, esto debe verse y no pasarse por alto al monitorear su clúster de MariaDB. Esto, como se menciona en uno de los beneficios de usar MariaDB Cluster, es que se evita el retraso del esclavo. Aunque eso es demasiado ingenuo para entender sobre el control de flujo y el retraso del esclavo, pero con el control de flujo, afectará el rendimiento de su clúster de Galera cuando hay mucha cola y confirmaciones o el vaciado de páginas en el disco es muy bajo para tales problemas de disco o es solo que la consulta en ejecución es una consulta incorrecta. Si es un principiante en el funcionamiento de Galera, es posible que le interese leer esta publicación externa sobre qué es el control de flujo en Galera.
Bytes enviados/recibidos
Los bytes enviados o recibidos se correlacionan con la actividad de la red e incluso es una de las áreas clave para observar junto con el control de flujo. Esto le permite determinar qué nodo es el más afectado o el que se atribuye a los problemas de rendimiento que están sufriendo dentro de su Galera Cluster. Es muy importante, ya que puede verificar si puede haber alguna degradación en términos de hardware, como su dispositivo de red o el dispositivo de almacenamiento subyacente para el cual la sincronización de páginas sucias puede llevar demasiado tiempo.
Carga de clúster
Bueno, se trata más de la actividad de la base de datos de cuántos cambios o recuperación de datos se han consultado o realizado hasta ahora desde el tiempo de actividad del servidor. Le ayuda a descartar qué tipo de consultas afectan principalmente el rendimiento del clúster de su base de datos. Esto le permite brindar margen de mejora, especialmente en el equilibrio de la carga de las solicitudes de su base de datos. El uso de ProxySQL lo ayuda aquí con un enfoque más refinado y granular para el enrutamiento de consultas. Aunque MaxScale también ofrece esta función, ProxySQL tiene más granularidad, aunque también tiene un impacto en el rendimiento o en el costo. El impacto se produce cuando solo tiene un ProxySQL como proxy SQL para resolver el enrutamiento de consultas y puede tener problemas cuando hay mucho tráfico en curso. Teniendo un costo, si agrega más nodos ProxySQL para equilibrar más tráfico que un KeepAlived subyacente. Aunque, este es un combo perfecto, pero se puede ejecutar a un bajo costo hasta que se necesite. Sin embargo, ¿cómo podrá determinar si es necesario, verdad? Esa es la pregunta que queda aquí, por lo que un buen ojo para monitorear estas áreas clave es muy importante, no solo para la observabilidad, sino también para mejorar el rendimiento de su clúster de base de datos a medida que pasa el tiempo.
Como tal, hay toneladas de variables para observar en un clúster de MariaDB. Lo más importante que debe tener en cuenta aquí es la herramienta que está utilizando para monitorear su clúster de base de datos. Como se mencionó anteriormente, prefiero usar la licencia de versión gratuita de ClusterControl (Community Edition) aquí en este blog, ya que me brinda más formas de flexibilidad para mirar en un Galera Cluster. Vea el ejemplo a continuación,
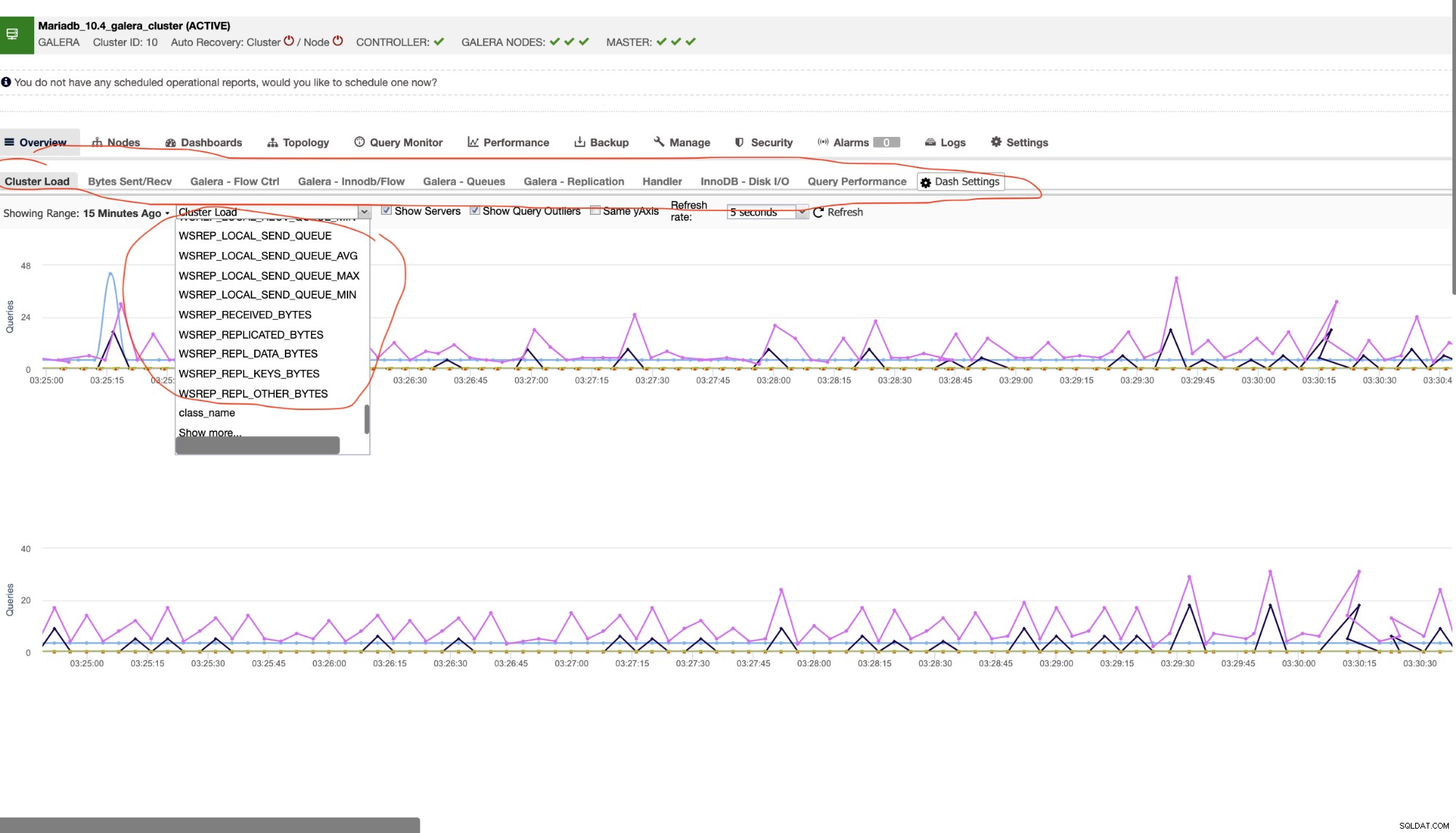
He marcado o encerrado en rojo las pestañas que me permiten supervisar visualmente la salud de mi clúster MariaDB. Digamos, si su aplicación es codiciosa sobre el uso de la replicación de transmisión de vez en cuando y envía una gran cantidad de fragmentos (transferencia de red grande) para la interactividad del clúster, es mejor determinar qué tan bien sus nodos pueden manejar el estrés. Especialmente durante las pruebas de estrés antes de impulsar cambios específicos en su aplicación, siempre es mejor probar y probar para determinar la administración de capacidad de su producto de aplicación y determinar si los nodos y el diseño de su base de datos actual pueden manejar la carga de los requisitos de su aplicación.
Incluso en una edición comunitaria de ClusterControl, puedo recopilar resultados granulares y más refinados del estado de mi clúster de MariaDB. Véase más abajo,
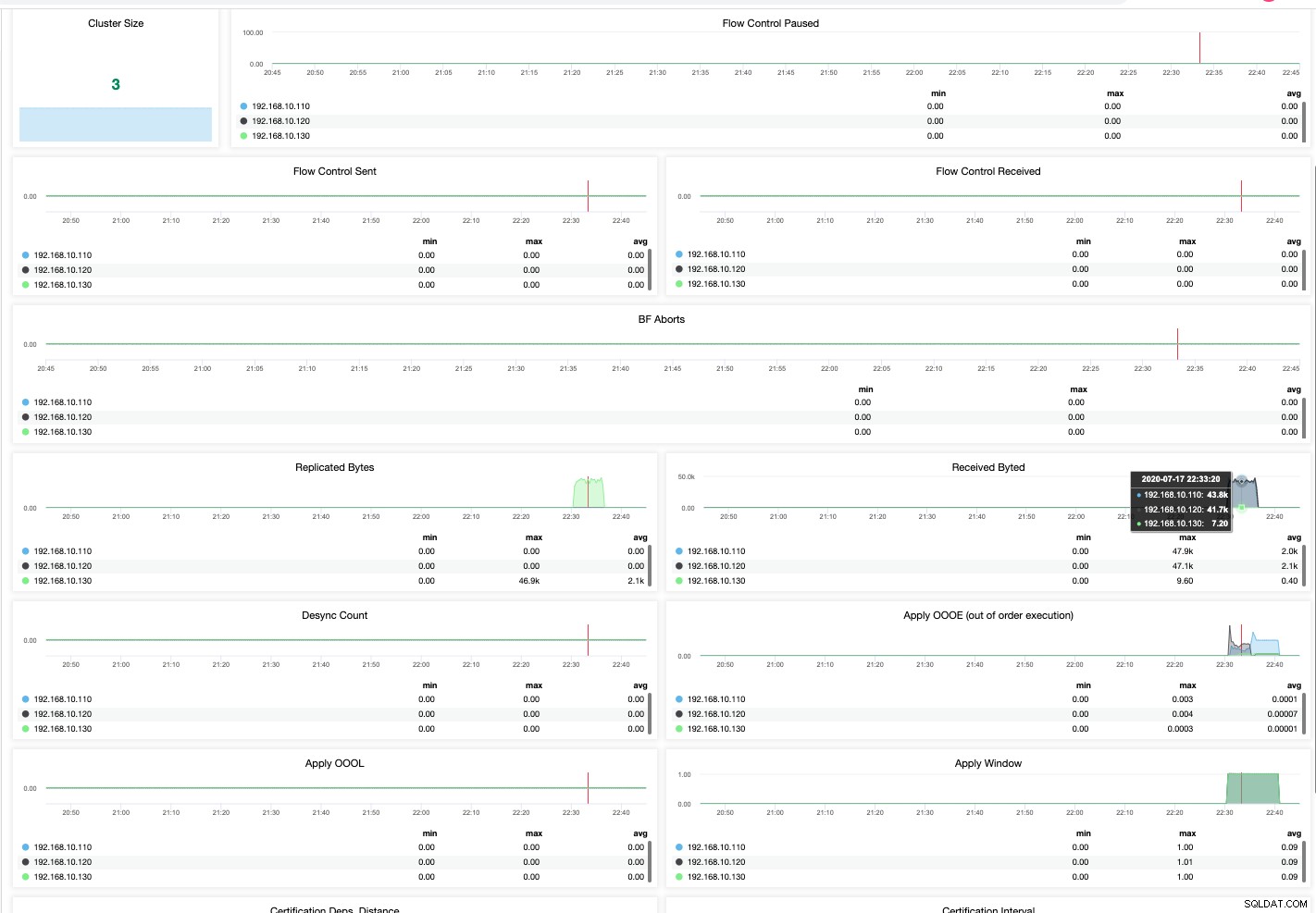
Así es como abordará el monitoreo de su MariaDB Cluster. Una visualización perfecta es siempre más fácil y rápida de gestionar. Cuando las cosas van mal, no puede darse el lujo de perder su productividad y también el tiempo de inactividad puede afectar su negocio. Aunque tener gratis no le brinda el lujo y la comodidad al administrar bases de datos de alto tráfico, tener alarmas, notificaciones y administración de bases de datos en un área son complementos fáciles de usar que ClusterControl puede hacer.
Conclusión
MariaDB Cluster no es tan simple de monitorear en comparación con las configuraciones tradicionales asíncronas de MySQL/MariaDB maestro-esclavo. Funciona de manera diferente y debe tener las herramientas adecuadas para determinar qué está pasando y qué está pasando en su clúster de base de datos. Prepare siempre su planificación de capacidad con anticipación antes de ejecutar su clúster de MariaDB sin una supervisión adecuada de antemano. Siempre es mejor conocer la carga y la actividad de su base de datos antes de un evento catastrófico.



