La replicación de MariaDB es una de las soluciones de alta disponibilidad más populares para MariaDB y es ampliamente utilizada por las principales empresas como Booking.com y Google. Es muy fácil de configurar, con algunas compensaciones en el mantenimiento continuo, como actualizaciones de software, cambios de esquema, cambios de topología, conmutación por error y recuperación, que siempre han sido complicados. Sin embargo, con el conjunto de herramientas adecuado, debería poder manejar la topología con facilidad. En esta publicación de blog, veremos algunos consejos para monitorear la replicación de MariaDB de manera eficiente usando ClusterControl.
Uso del visor de topología
Una configuración de replicación consta de varios roles. Un nodo en una configuración de replicación podría ser:
- Maestro - El escritor/lector principal.
- Maestro de respaldo:un esclavo de solo lectura con replicación semisincrónica, únicamente para la redundancia del maestro.
- Maestro intermedio:replica desde un maestro, mientras que otros esclavos replican desde este nodo.
- Servidor binlog:solo recopila/almacena binlogs sin servir datos.
- Esclavo:replica desde un maestro y, por lo general, se configura como de solo lectura.
- Esclavo de múltiples fuentes - Replicar desde múltiples maestros.
Cada rol tiene su propia responsabilidad y limitación y uno debe comprender la topología correcta cuando se trata de los nodos de la base de datos. Esto también es cierto para la aplicación, donde la aplicación tiene que escribir solo en el nodo maestro en un momento dado. Por lo tanto, es importante tener una visión general de qué nodo está desempeñando qué rol, para que no arruinemos nuestra base de datos.
En ClusterControl, el Visor de topología puede brindarle una descripción general de la topología de replicación y su estado, como se muestra en la siguiente captura de pantalla:
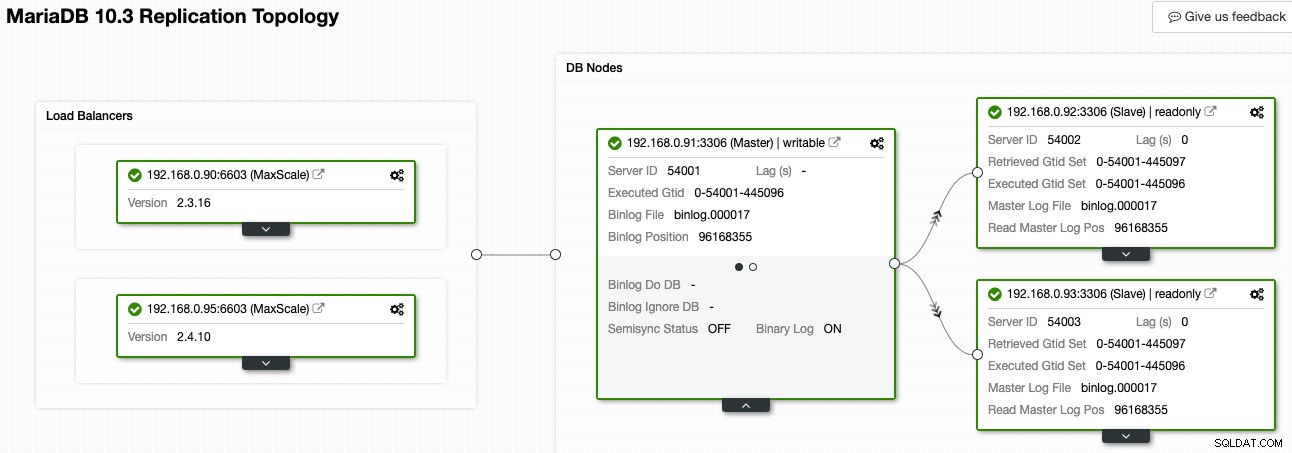
ClusterControl comprende la replicación de MariaDB y puede visualizar la topología con el flujo de datos de replicación correcto, como lo representan las flechas que apuntan a los nodos esclavos. Podemos distinguir fácilmente qué nodo es el maestro, los esclavos y los equilibradores de carga (MaxScale) en nuestra configuración de replicación. El cuadro verde indica que todos los servicios importantes se ejecutan según lo previsto con la función asignada.
Considere la siguiente captura de pantalla donde varios de nuestros nodos tienen problemas:
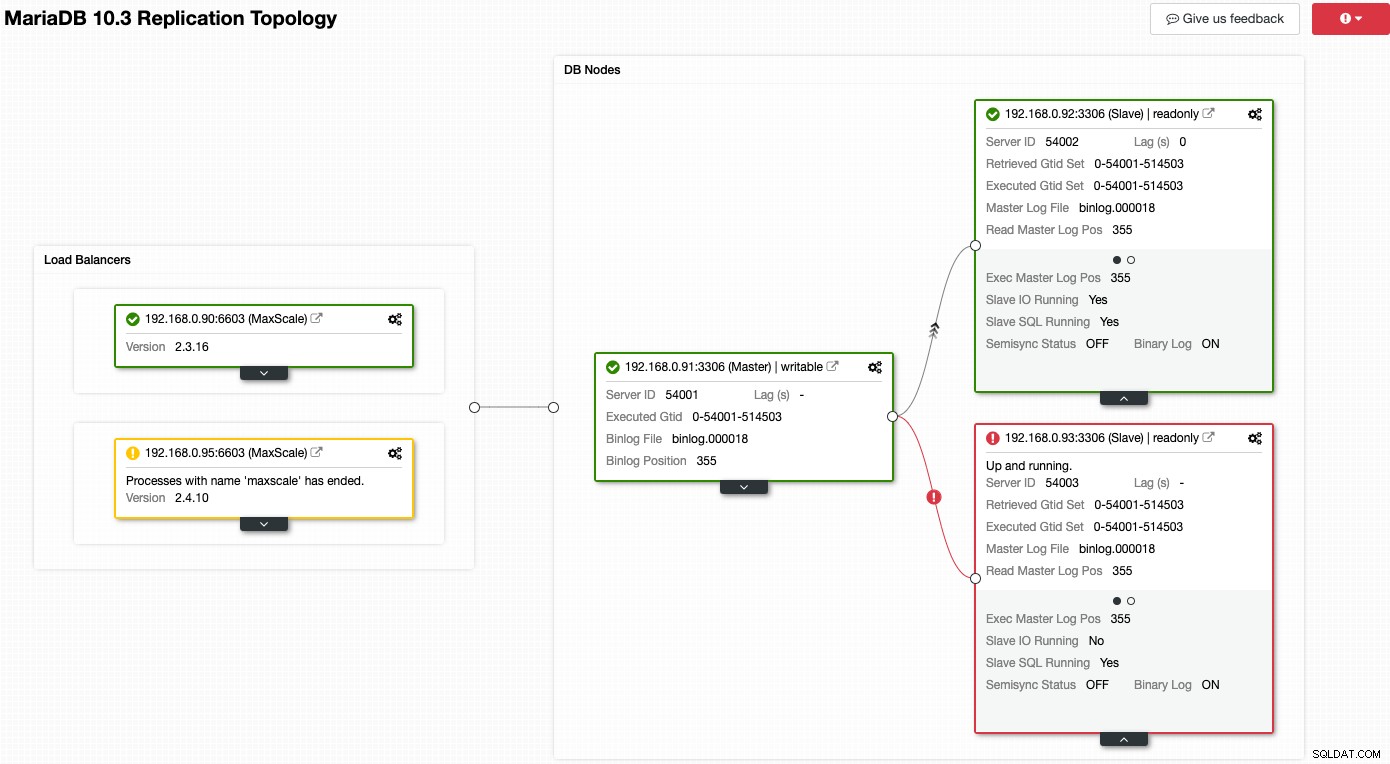
ClusterControl le dirá de inmediato cuál es el problema con la topología actual. Uno de los esclavos (cuadro rojo) muestra "E/S esclava en ejecución" como No, para indicar algún problema de conectividad para replicar desde el maestro. Mientras que el cuadro amarillo muestra que nuestro servicio MaxScale no se está ejecutando. También podemos decir que las versiones de MaxScale no son idénticas para ambos nodos. También puede realizar tareas de administración haciendo clic en el ícono de ajustes (arriba a la derecha en cada cuadro) directamente, lo que reduce los riesgos de seleccionar un nodo incorrecto.
Retraso de replicación
Esto es lo más importante si confía en la consistencia de la replicación de datos. El retraso en la replicación ocurre cuando los esclavos no pueden mantenerse al día con las actualizaciones que ocurren en el maestro. Los cambios no aplicados se acumulan en los registros de retransmisión de los esclavos y la versión de la base de datos de los esclavos se vuelve cada vez más diferente a la del maestro.
En ClusterControl, puede encontrar el histograma de retraso de replicación en Descripción general -> Retraso de replicación, donde ClusterControl muestrea constantemente el valor Seconds_Behind_Master de la salida "MOSTRAR ESTADO DE ESCLAVO":
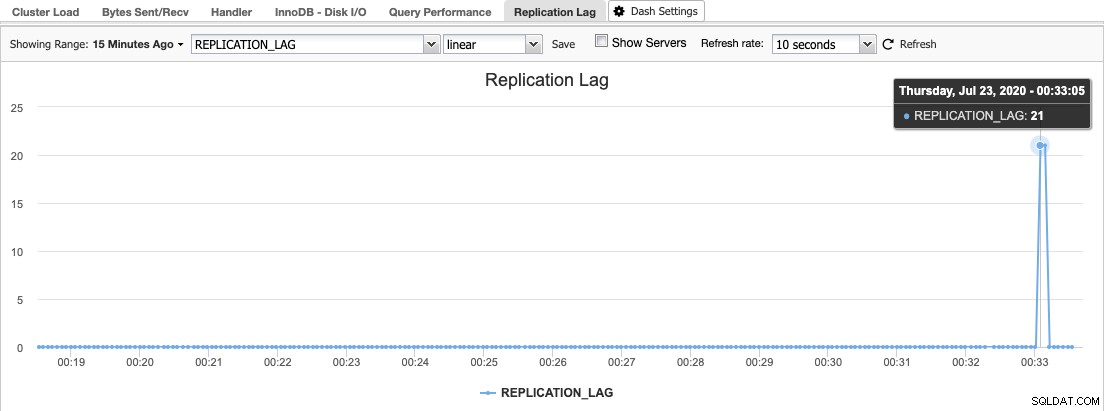
El retraso de la replicación ocurre cuando el subproceso de E/S o el subproceso SQL no pueden hacer frente a las demandas que se le imponen. Si el subproceso de E/S está sufriendo, esto significa que la conexión de red entre el maestro y sus esclavos es lenta o tiene problemas. Es posible que desee considerar habilitar el Slave_compressed_protocol para comprimir el tráfico de red o informar a su administrador de red.
Si es el subproceso SQL, entonces el problema probablemente se deba a consultas mal optimizadas que están tardando demasiado en aplicar al esclavo. Puede haber transacciones de ejecución prolongada o demasiada actividad de E/S. No tener una clave principal en las tablas esclavas cuando se usa el formato de replicación ROW o MIXED también es una causa común de retraso en este subproceso. Verifique que las versiones maestra y esclava de las tablas tengan una clave principal.
En esta publicación de blog se tratan algunos consejos y trucos más, Cómo reducir el retraso de la replicación en implementaciones de varias nubes.
Tamaño de registro binario/de retransmisión
Es importante monitorear el tamaño del disco de registros binarios y de retransmisión porque podría consumir una cantidad considerable de almacenamiento en cada nodo en un clúster de replicación. Por lo general, se establecería la variable de sistema expire_logs_days para que caduquen los archivos de registro binarios automáticamente después de un número determinado de días, por ejemplo, expire_logs_days=7. El tamaño de los registros binarios depende totalmente de la cantidad de eventos binarios creados (escrituras entrantes) y poco sabemos cuánto espacio en disco consumiría antes de que MariaDB caduque los registros. Tenga en cuenta que si habilita log_slave_updates en los esclavos, el tamaño de los registros casi se duplicará debido a la existencia de registros binarios y de retransmisión en el mismo servidor.
Para ClusterControl, podemos establecer un umbral de utilización del espacio en disco en ClusterControl -> Configuración -> Umbrales para recibir una advertencia y notificaciones críticas como se muestra a continuación:
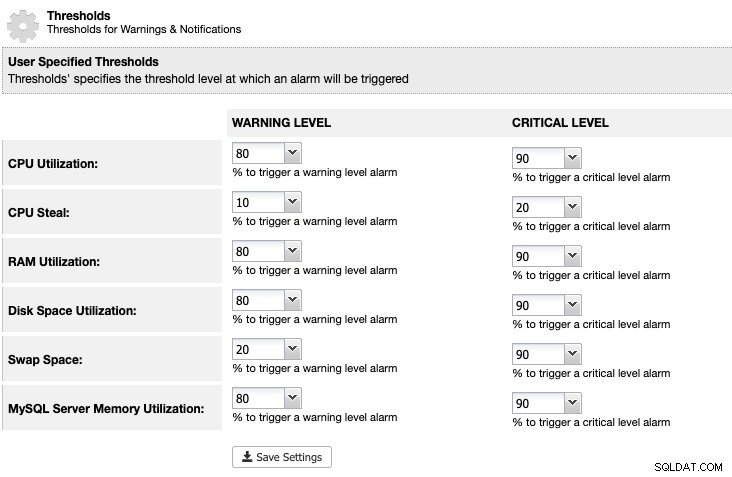
ClusterControl supervisa todo el espacio en disco relacionado con los servicios de MariaDB, como la ubicación de los datos de MariaDB directorio, el directorio de registros binarios y también la partición raíz. Si ha alcanzado el umbral, considere purgar los registros binarios manualmente mediante el comando PURGE BINARY LOGS, como se explica y analiza en este artículo.
Habilitar paneles de supervisión
ClusterControl proporciona dos opciones de monitoreo para muestrear los nodos de la base de datos:sin agente o con agente. El valor predeterminado es sin agente donde el muestreo ocurre a través de SSH en un mecanismo de solo extracción. La supervisión basada en agentes requiere la ejecución de un servidor Prometheus y la configuración de todos los nodos supervisados con al menos tres exportadores:
- Exportador de procesos (puerto 9011)
- Exportador de métricas de nodo/sistema (puerto 9100)
- Exportador MySQL/MariaDB (puerto 9104)
Para habilitar el panel de monitoreo basado en agentes, uno tiene que ir a ClusterControl -> Paneles -> Habilitar monitoreo basado en agentes. Una vez habilitado, verá un conjunto de paneles configurados para nuestra replicación de MariaDB, lo que nos brinda una visión mucho mejor de nuestra configuración de replicación. La siguiente captura de pantalla muestra lo que vería para el nodo principal:
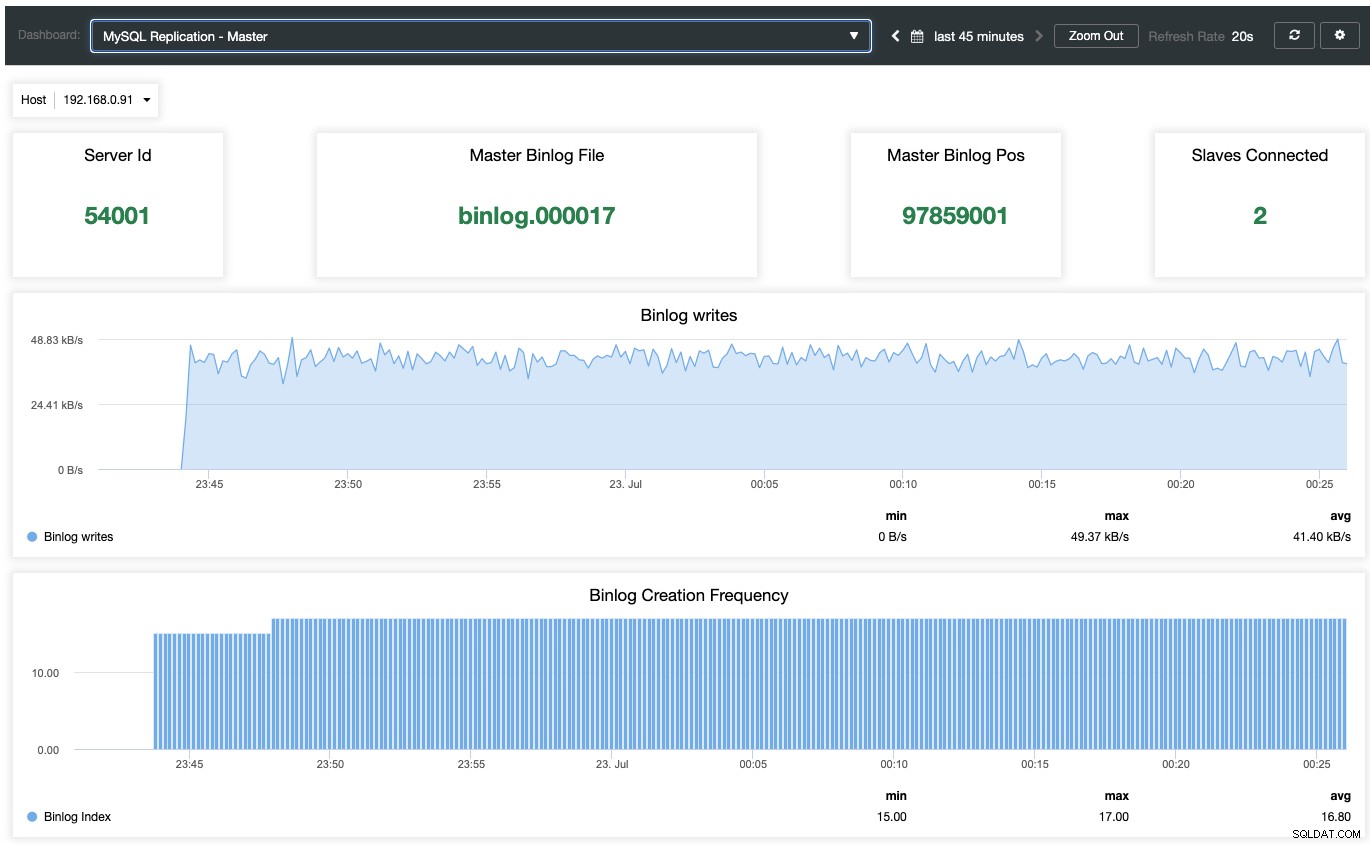
Además de los paneles de monitoreo estándar de MariaDB como general, cachés y métricas de InnoDB, usted se le presentará un tablero de replicación. Para el nodo maestro, podemos obtener mucha información útil sobre el estado del maestro, el rendimiento de escritura y la frecuencia de creación de binlog.
Mientras que para los esclavos, todos los estados importantes se muestran y resumen en la siguiente captura de pantalla. si todo es verde, estás en buenas manos:
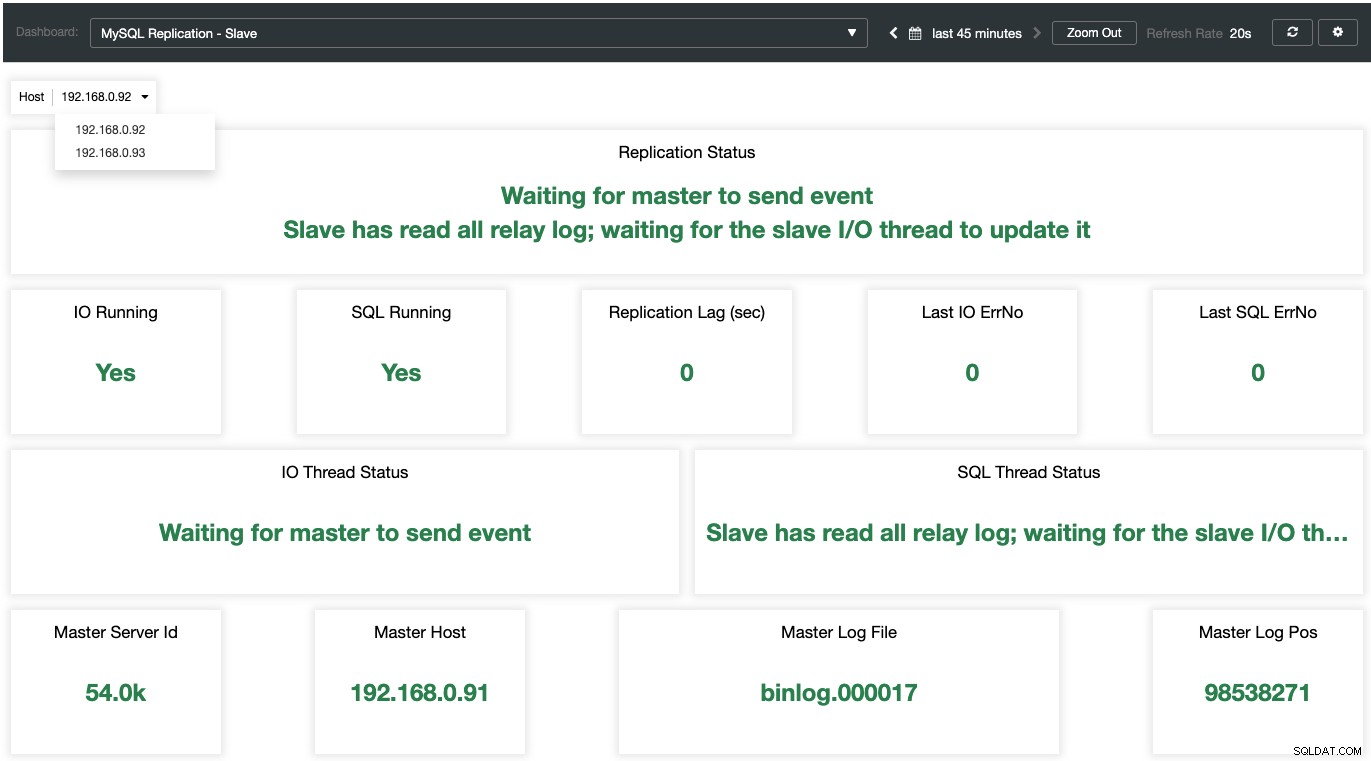
Comprender el registro de errores de MariaDB
MariaDB registra sus eventos importantes dentro del registro de errores, lo cual es útil para comprender qué estaba pasando con el servidor, especialmente antes, durante y después de un cambio de topología. ClusterControl proporciona una vista centralizada de los registros de errores en ClusterControl -> Registros -> Registros del sistema extrayéndolos de cada nodo de la base de datos. Hace clic en "Actualizar registros" para activar un trabajo para extraer los últimos registros del servidor.
Los archivos recopilados se representan en una estructura de árbol de navegación y un área de texto con resaltado de sintaxis para una mejor legibilidad:
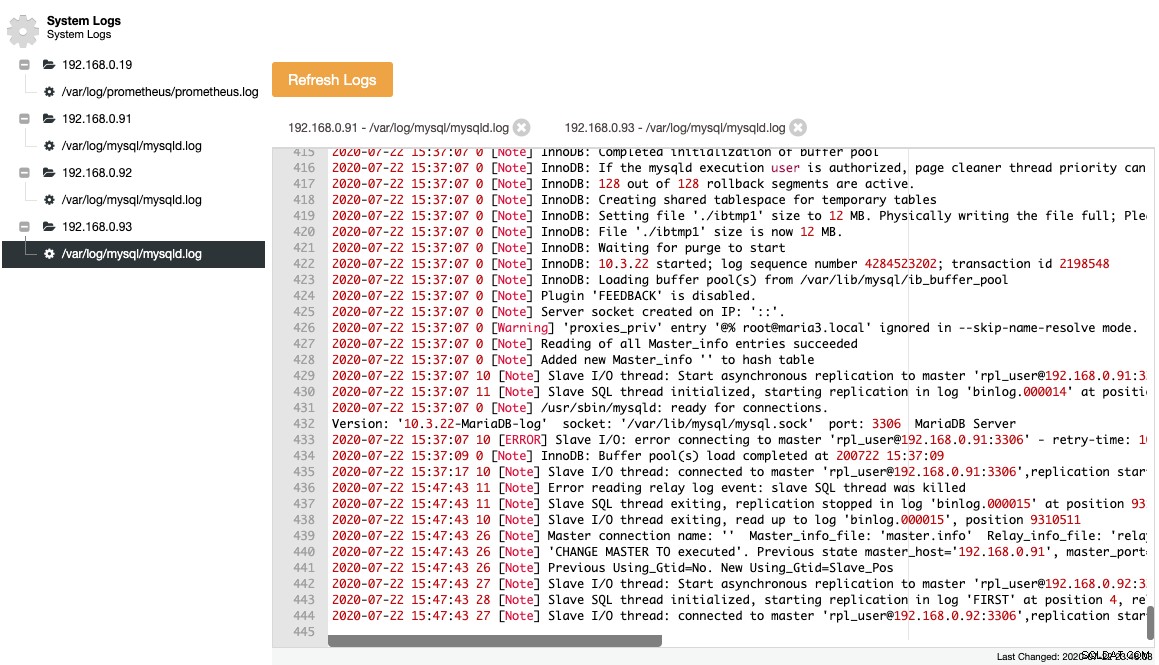
A partir de la captura de pantalla anterior, podemos comprender la secuencia de eventos y lo que le sucedió a este nodo durante un evento de cambio de topología. De las últimas 12 líneas del registro de errores anterior, el esclavo tuvo un error una vez que se conectó al maestro y el último archivo de registro binario y la posición se registraron en el registro antes de que se detuviera. Luego, se ejecutó un comando CHANGE MASTER más nuevo con información de GTID, como se muestra en la línea "Using_Gtid_anterior=No. New Using_Gtid=Slave_Pos" y luego la replicación se reanuda como queríamos.
Alertas y notificaciones de MariaDB
El monitoreo es incompleto sin alertas y notificaciones. Todos los eventos y alarmas generados por ClusterControl se pueden enviar al correo electrónico o a cualquier otra herramienta de terceros compatible. Para las notificaciones por correo electrónico, se puede configurar si el tipo de eventos se entregarán de inmediato, se ignorarán o se digerirán (un informe resumido diario):

Para todos los eventos de gravedad crítica, se recomienda configurar todo en "Entregar" para que reciba las notificaciones lo antes posible. Establezca "Resumen" en eventos de advertencia para que esté al tanto de la salud y el estado del clúster.
Puede integrar sus herramientas de comunicación y mensajería preferidas con ClusterControl utilizando la función de administración de notificaciones en ClusterControl -> Integraciones -> Notificaciones de terceros. ClusterControl puede enviar alarmas y eventos a PagerDuty, VictorOps, OpsGenie, Slack, Telegram, ServiceNow o cualquier webhook registrado por el usuario.
La siguiente captura de pantalla muestra que todos los eventos críticos se enviarán al canal de Telegram configurado para nuestro clúster de replicación de MariaDB 10.3:

ClusterControl también es compatible con la integración de chatbot, donde puede interactuar con el servicio del controlador a través del cliente s9s directamente desde su herramienta de mensajería, como se muestra en esta publicación de blog, Automatice su base de datos con CCBot:Integración de ClusterControl Hubot.
Conclusión
ClusterControl ofrece un conjunto completo de herramientas de monitoreo proactivo para sus clústeres de bases de datos. Utilice ClusterControl para monitorear su configuración de replicación de MariaDB porque la mayoría de las funciones de monitoreo están disponibles de forma gratuita en la edición comunitaria. ¡No te los pierdas!