Dado que la alta disponibilidad es primordial en la realidad empresarial actual, uno de los escenarios más comunes que enfrentan los usuarios es cómo garantizar que la base de datos siempre estará disponible para la aplicación.
Cada proveedor de servicios viene con un riesgo heredado de interrupción del servicio, por lo tanto, uno de los pasos que se pueden tomar es confiar en múltiples proveedores para aliviar el riesgo y la redundancia adicional.
Los proveedores de servicios en la nube no son diferentes:pueden fallar y debe planificar esto con anticipación. ¿Qué opciones están disponibles para MariaDB Cluster? Echémosle un vistazo en esta publicación de blog.
Clustering de base de datos MariaDB en entornos de varias nubes
Si el SLA propuesto por un proveedor de servicios en la nube no es suficiente, siempre existe la opción de crear un sitio de recuperación ante desastres fuera de ese proveedor. Gracias a esto, cada vez que uno de los proveedores de la nube experimenta alguna degradación del servicio, siempre puede cambiar a otro proveedor y mantener su base de datos disponible.
Uno de los problemas típicos de las configuraciones de múltiples nubes es la latencia de la red que es inevitable si hablamos de distancias más grandes o, en general, de múltiples ubicaciones separadas geográficamente. La velocidad de la luz es bastante alta pero es finita, cada salto, cada enrutador también agrega algo de latencia a la infraestructura de la red.
MariaDB Cluster funciona muy bien en redes de baja latencia. Es un clúster basado en quórum donde se requiere una comunicación rápida entre todos los nodos para mantener las operaciones sin problemas. El aumento de la latencia de la red afectará las operaciones del clúster, especialmente el rendimiento de las escrituras. Hay varias maneras de abordar este problema.
Primero, tenemos una opción para usar clústeres separados conectados mediante enlaces de replicación asincrónica. Esto nos permite casi olvidarnos de la latencia porque la replicación asíncrona es significativamente más adecuada para trabajar en entornos de alta latencia.
Otra opción es que, dadas las redes de baja latencia entre los centros de datos, aún puede ejecutar perfectamente un clúster de MariaDB que abarque varios centros de datos. Después de todo, múltiples centros de datos no siempre significan grandes distancias desde el punto de vista geográfico; también puede usar múltiples proveedores ubicados dentro de la misma área metropolitana, conectados con redes rápidas y de baja latencia. Entonces estaremos hablando de un aumento de la latencia a decenas de milisegundos como máximo, definitivamente no a cientos. Todo depende de la aplicación, pero tal aumento puede ser aceptable.
Replicación asíncrona entre clústeres de MariaDB
Echemos un vistazo rápido al enfoque asíncrono. La idea es simple:dos clústeres conectados entre sí mediante replicación asíncrona.
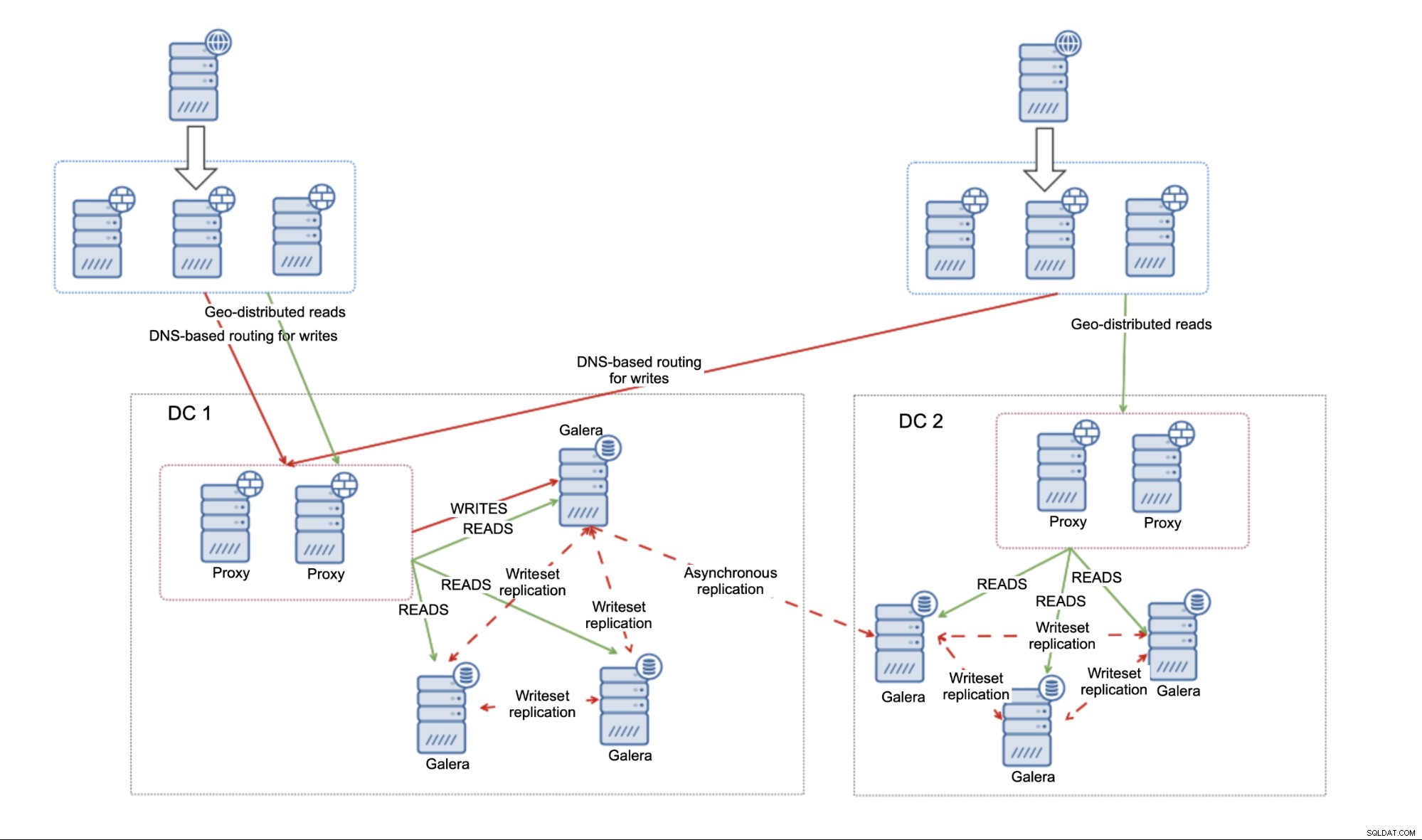
Esto viene con varias limitaciones. Para empezar, debe decidir si desea utilizar multimaestro o enviaría todo el tráfico a un solo centro de datos. Recomendamos evitar escribir en ambos centros de datos y usar la replicación maestro - maestro. Esto puede ocasionar problemas graves si no tiene cuidado.
Si decide utilizar la configuración activa - pasiva, probablemente querrá implementar algún tipo de enrutamiento basado en DNS para escrituras, para asegurarse de que sus servidores de aplicaciones siempre se conectarán a un conjunto de proxies ubicados en el centro de datos activo. Esto podría lograrse literalmente mediante una entrada de DNS que se cambiaría cuando se requiera la conmutación por error o mediante algún tipo de solución de detección de servicios como Consul o etcd.
La principal desventaja del entorno creado con la replicación asincrónica es la falta de capacidad para manejar divisiones de red entre centros de datos. Esto se hereda de la replicación:independientemente de lo que desee vincular con la replicación (nodos únicos, clústeres de MariaDB), no hay forma de evitar el hecho de que la replicación no tiene en cuenta el quórum. No existe un mecanismo para rastrear el estado de los nodos y comprender la imagen de alto nivel de toda la topología. Como resultado, cada vez que falla el enlace entre dos centros de datos, termina con dos clústeres de MariaDB separados que no están conectados y que están listos para aceptar tráfico. Corresponderá al usuario definir qué hacer en tal caso. Es posible implementar herramientas adicionales que monitorearían el estado de las bases de datos desde el exterior (es decir, desde el tercer centro de datos) y luego realizar acciones (o no realizar acciones) en función de esa información. También es posible ubicar herramientas que compartirían la infraestructura con las bases de datos pero que serían conscientes de los clústeres y podrían rastrear el estado de la conectividad del centro de datos y usarse como la fuente de la verdad para los scripts que administrarían el entorno. Por ejemplo, ClusterControl se puede implementar en un clúster de tres nodos, nodo por centro de datos, que utiliza el protocolo RAFT para garantizar el quórum. Si un nodo pierde la conectividad con el resto del clúster, se puede suponer que el centro de datos experimentó una partición de la red.
Clústeres MariaDB de DC múltiples
Una alternativa a la replicación asincrónica podría ser una solución de clúster de MariaDB que abarque varios centros de datos.
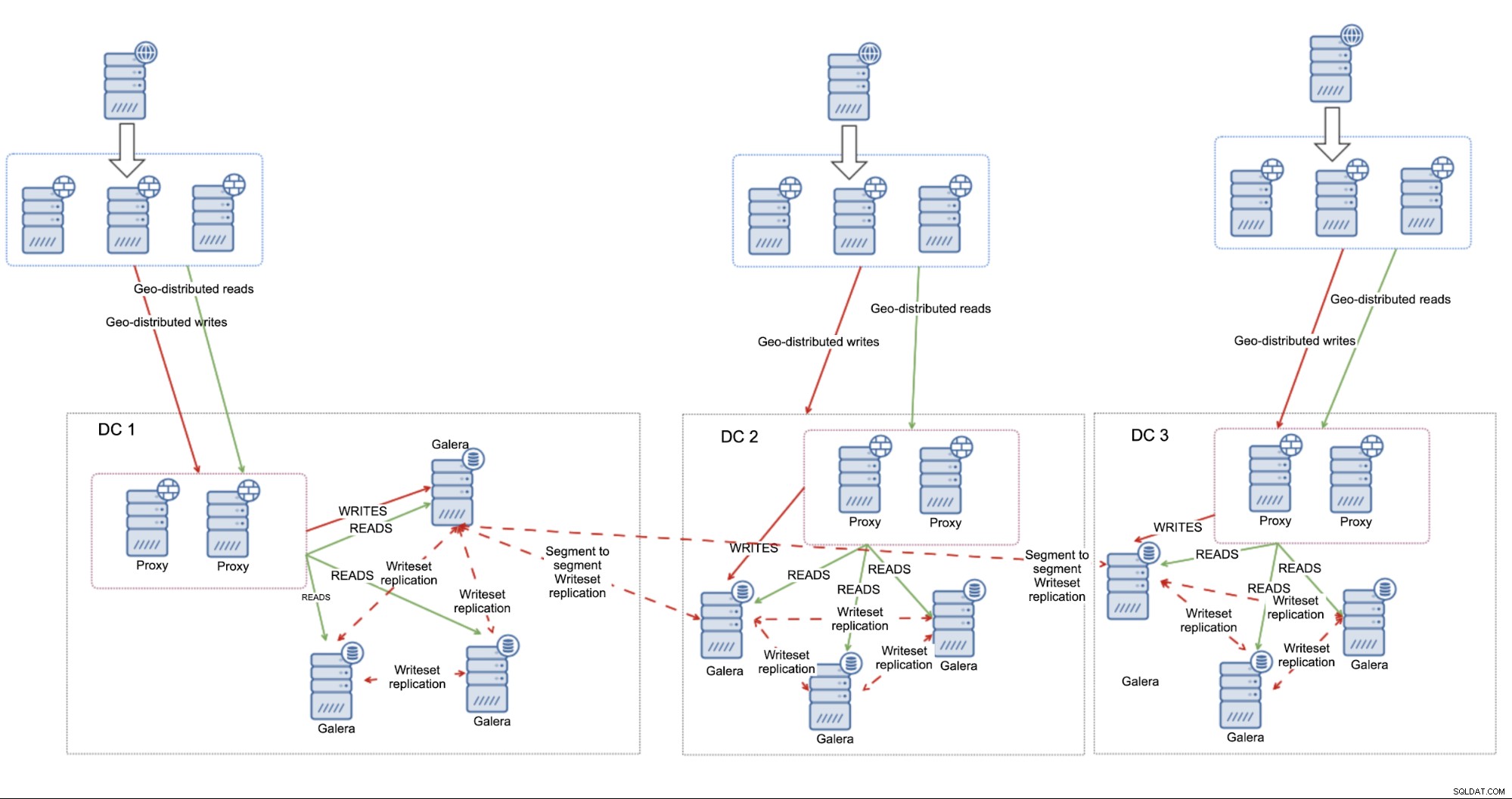
Como se indicó al comienzo de este blog, MariaDB Cluster, como todos El clúster basado en Galera se verá afectado por la alta latencia. Habiendo dicho eso, es perfectamente aceptable ejecutarlo en entornos de latencia "no tan alta" y esperar que se comporte correctamente, brindando un rendimiento aceptable. Todo depende del rendimiento y el diseño de la red, la distancia entre los centros de datos y los requisitos de la aplicación. Tal enfoque funcionará muy bien, especialmente si usamos segmentos para diferenciar centros de datos separados. Permite que MariaDB Cluster optimice su conectividad dentro del clúster y reduzca al mínimo el tráfico cruzado de CC.
La principal ventaja de esta configuración es que se basa en MariaDB Cluster para manejar las fallas. Si usa tres centros de datos, está prácticamente cubierto contra la situación del cerebro dividido:mientras haya una mayoría, seguirá funcionando. No es necesario tener un nodo completo en el tercer centro de datos; también puede usar Galera Arbitrator, un demonio que actúa como parte del clúster pero no tiene que manejar ninguna operación de base de datos. Se conecta a los nodos, participa en el cálculo del quórum y puede utilizarse para retransmitir el tráfico en caso de que no funcione la conexión directa entre los dos centros de datos.
En ese caso, todo el proceso de conmutación por error se puede describir como:definir todos los nodos en los balanceadores de carga (todos si los centros de datos están cerca uno del otro, en otro caso, es posible que desee agregar alguna prioridad para el nodos ubicados más cerca del balanceador de carga) y eso es todo. Se podrá acceder a los nodos de MariaDB Cluster que forman la mayoría a través de cualquier proxy.
Implementación de un clúster MariaDB de varias nubes mediante ClusterControl
Echemos un vistazo a dos opciones que puede usar para implementar clústeres de MariaDB en varias nubes mediante ClusterControl. Tenga en cuenta que ClusterControl requiere conectividad SSH para todos los nodos que administrará, por lo que depende de usted garantizar la conectividad de red en múltiples centros de datos o proveedores de nube. Siempre que haya conectividad, podemos proceder con dos métodos.
Implementación de clústeres de MariaDB mediante replicación asincrónica
ClusterControl puede ayudarlo a implementar dos clústeres conectados mediante replicación asincrónica. Cuando tiene implementado un solo clúster de MariaDB, desea asegurarse de que uno de los nodos tenga habilitados los registros binarios. Esto le permitirá usar ese nodo como maestro para el segundo clúster que crearemos en breve.
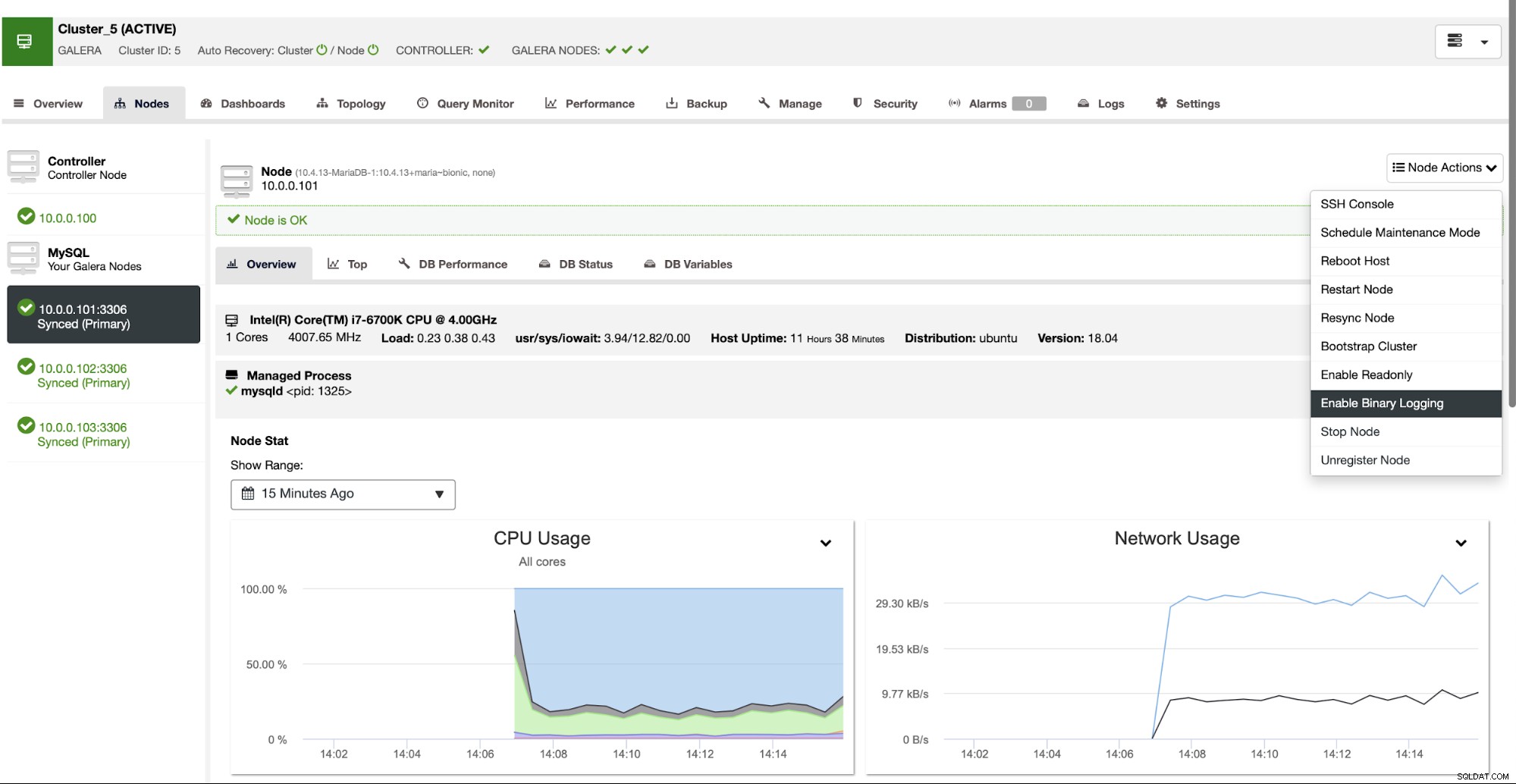
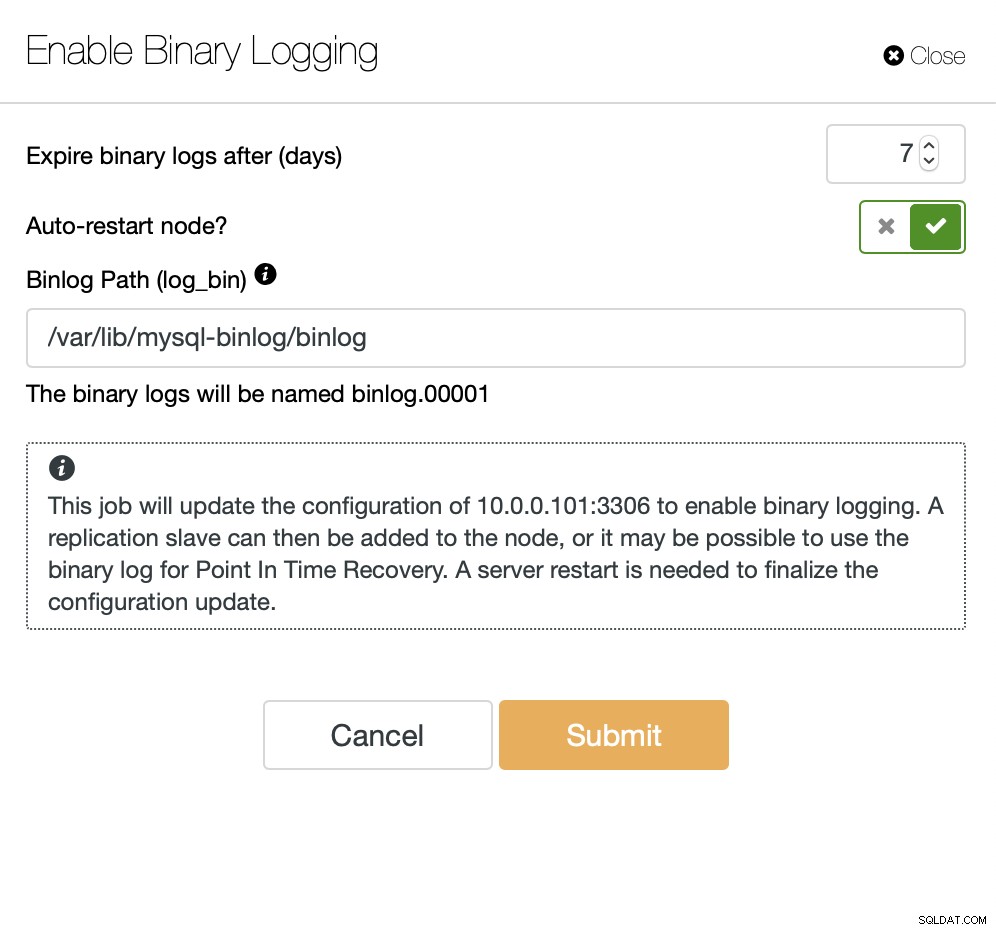
Una vez que se ha habilitado el registro binario, podemos usar el trabajo Crear clúster esclavo para iniciar el asistente de implementación.
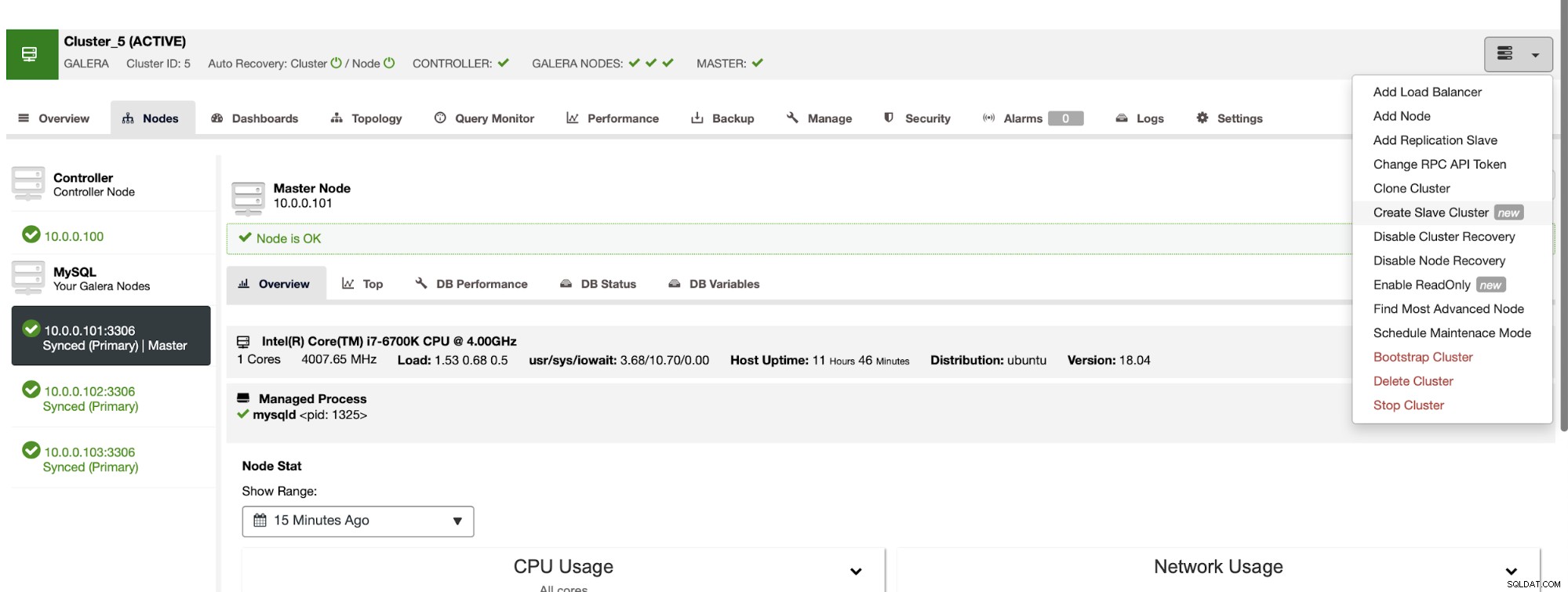
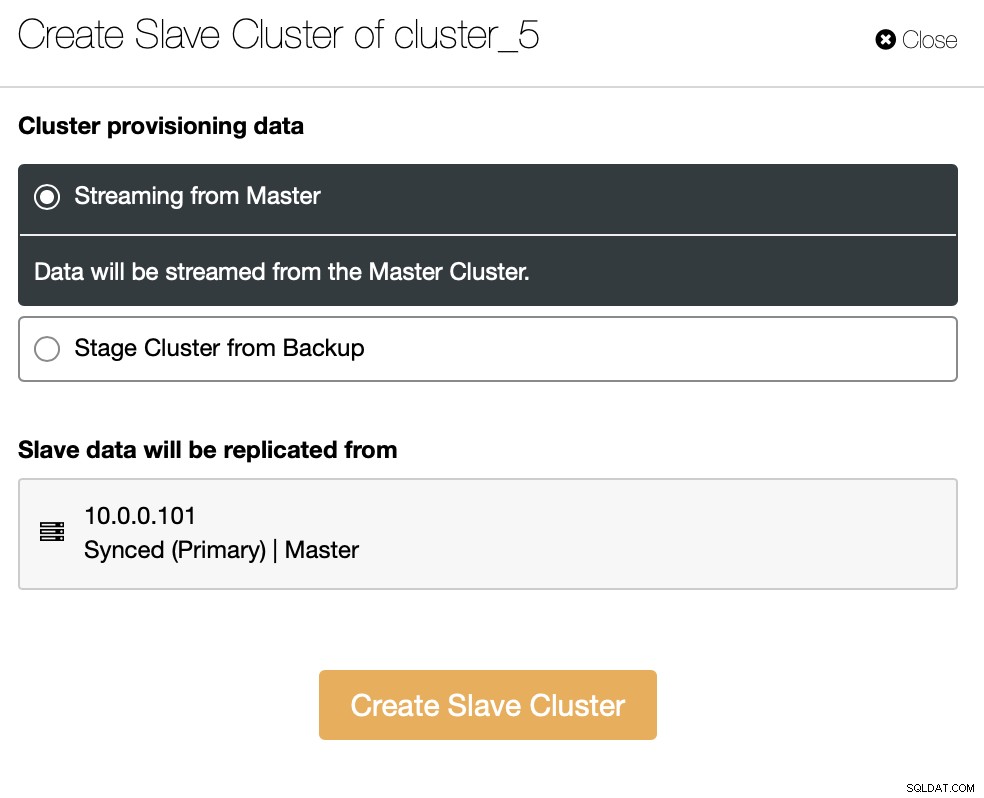
Podemos transmitir los datos directamente desde el maestro o puede usar uno de las copias de seguridad para aprovisionar los datos.
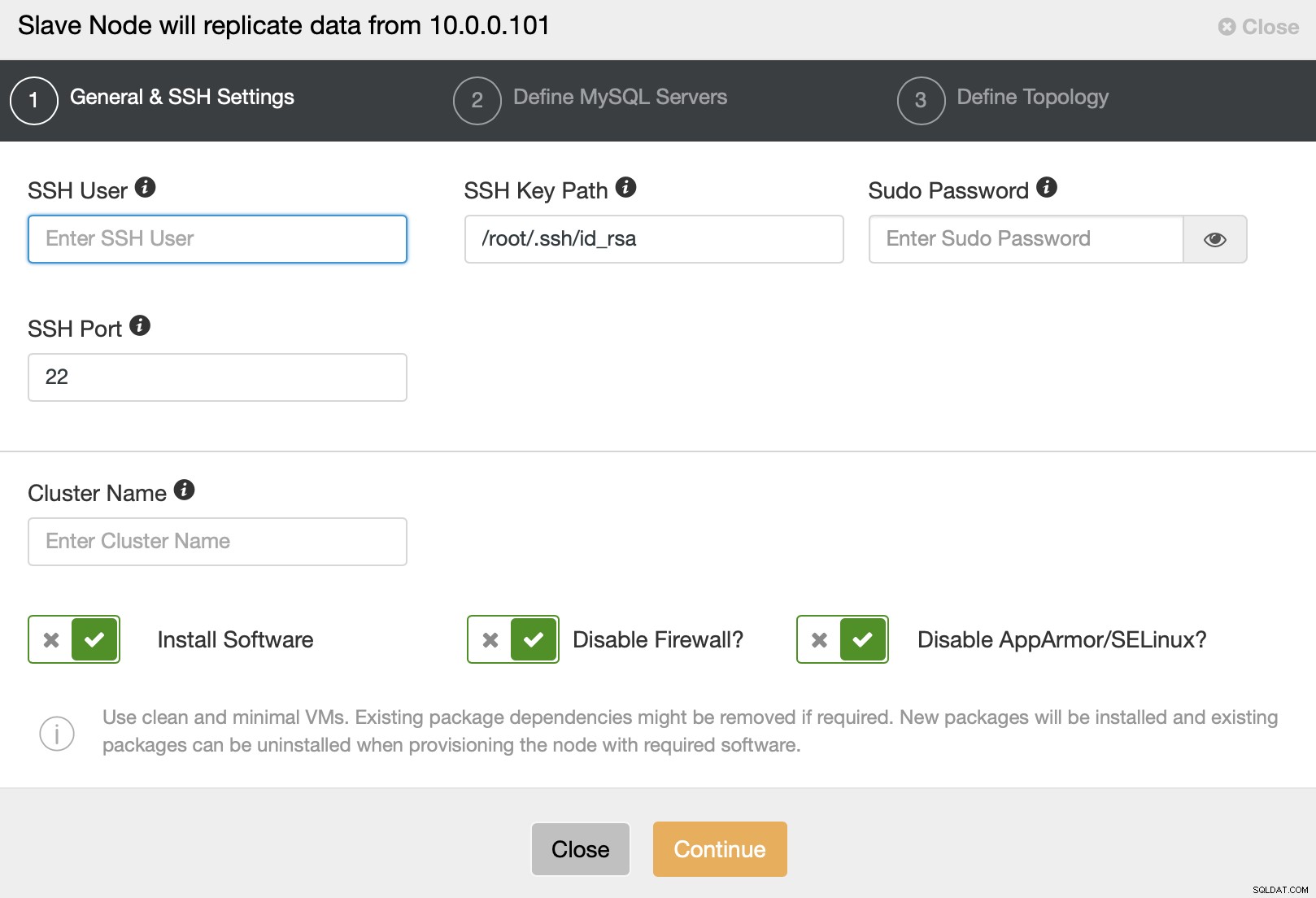
Luego se le presenta un asistente de implementación de clúster estándar donde debe pasar Detalles de conectividad SSH.
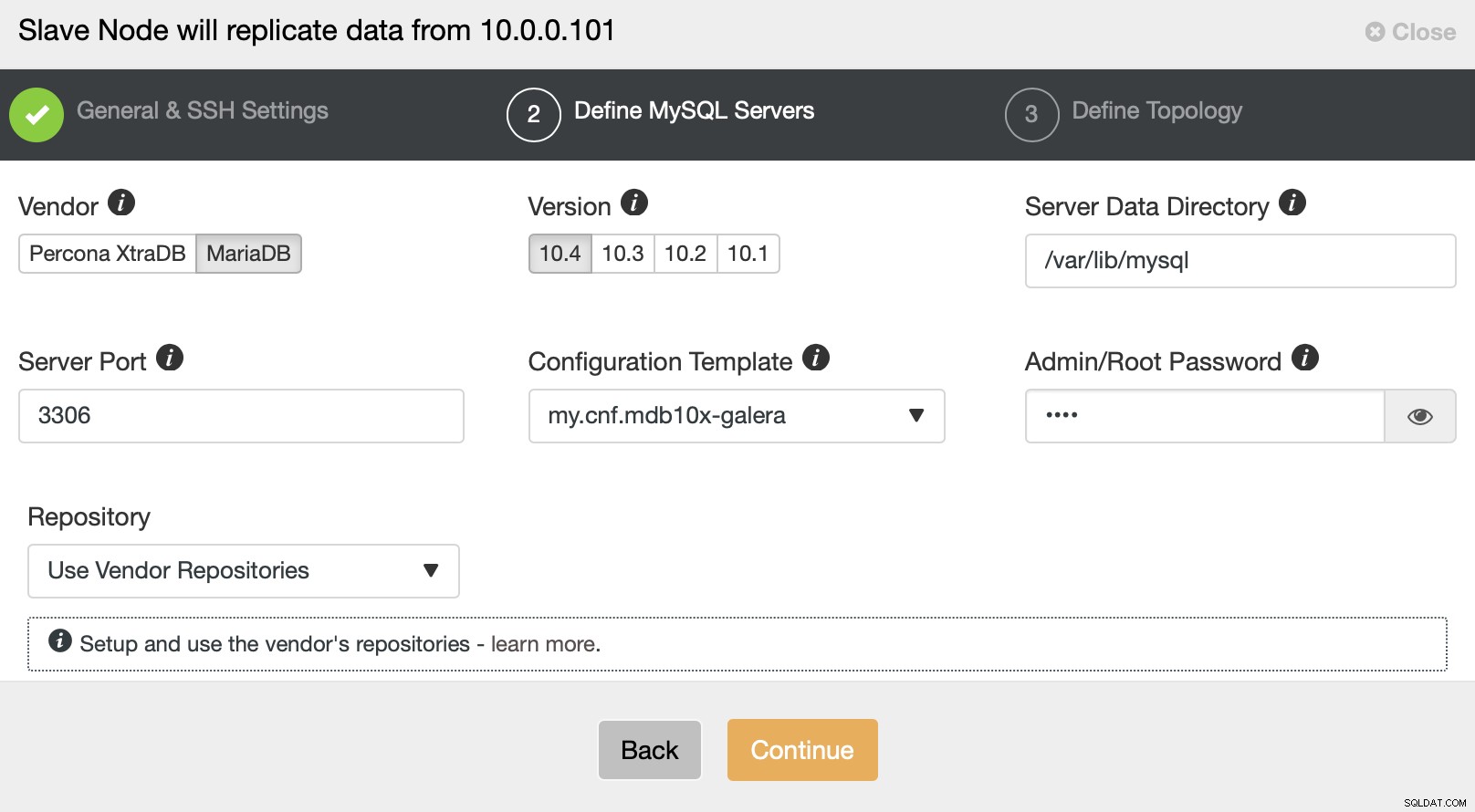
También se le pedirá que elija el proveedor y la versión de las bases de datos como se le solicitó la contraseña para el usuario root.
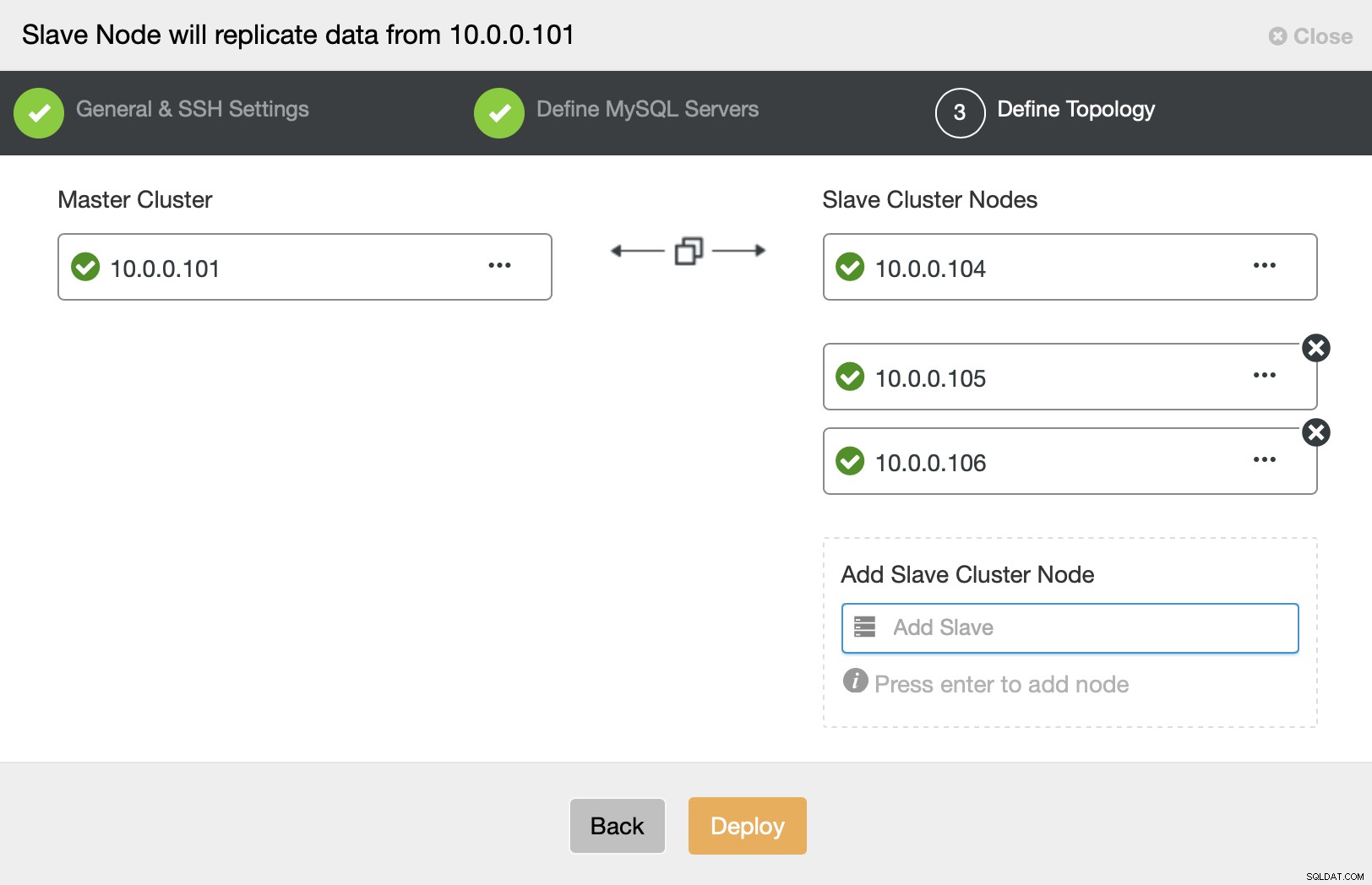
Finalmente, se le pide que defina los nodos que le gustaría agregar al clúster y ya está todo listo.
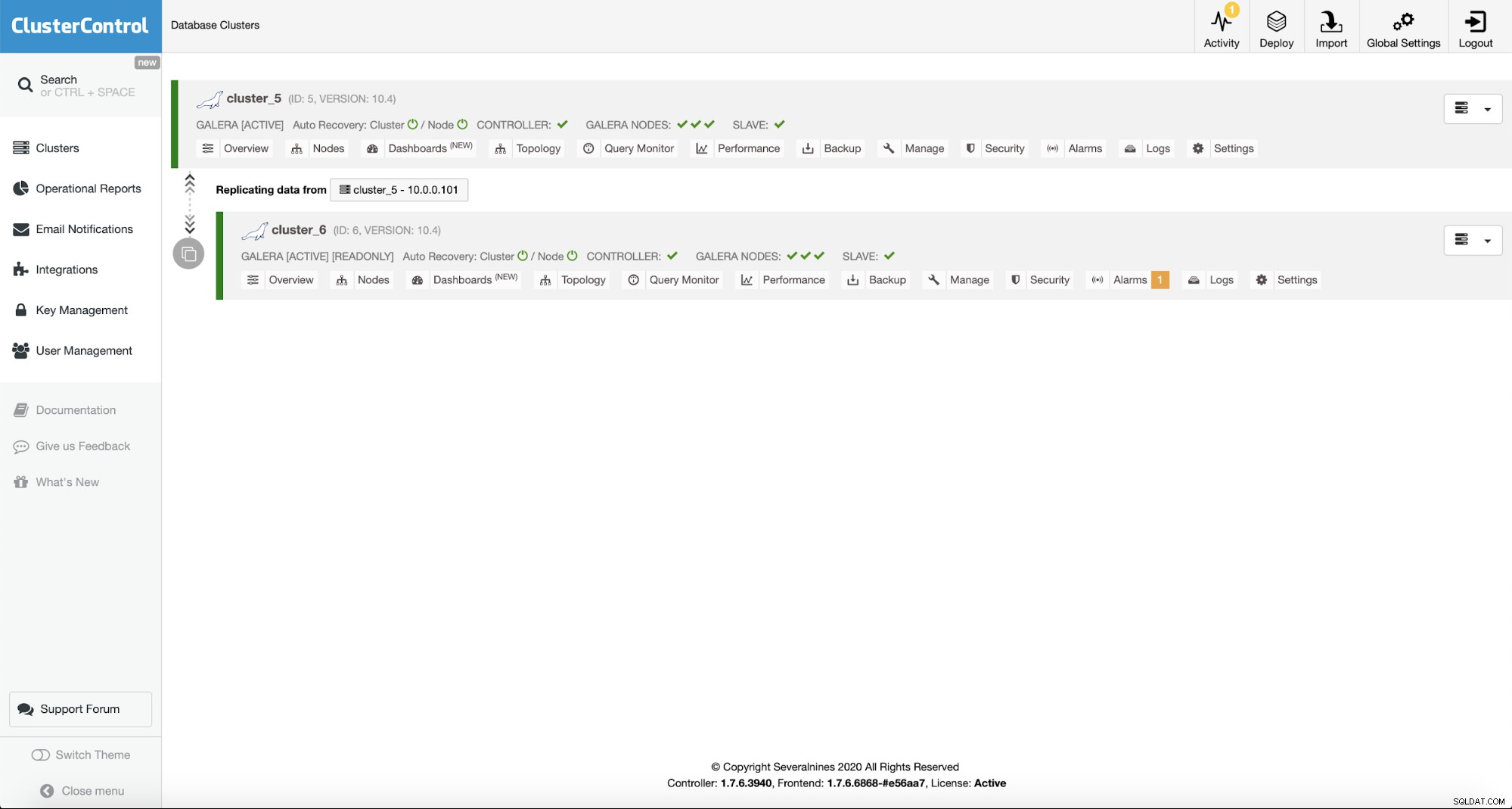
Cuando se implemente, lo verá en la lista de clústeres en el Interfaz de usuario de ClusterControl.
Implementación de un clúster de MariaDB en varias nubes
Como mencionamos anteriormente, otra opción para implementar MariaDB Cluster sería usar segmentos separados al agregar nodos al clúster. En la interfaz de usuario de ClusterControl, encontrará una opción para "Agregar nodo":
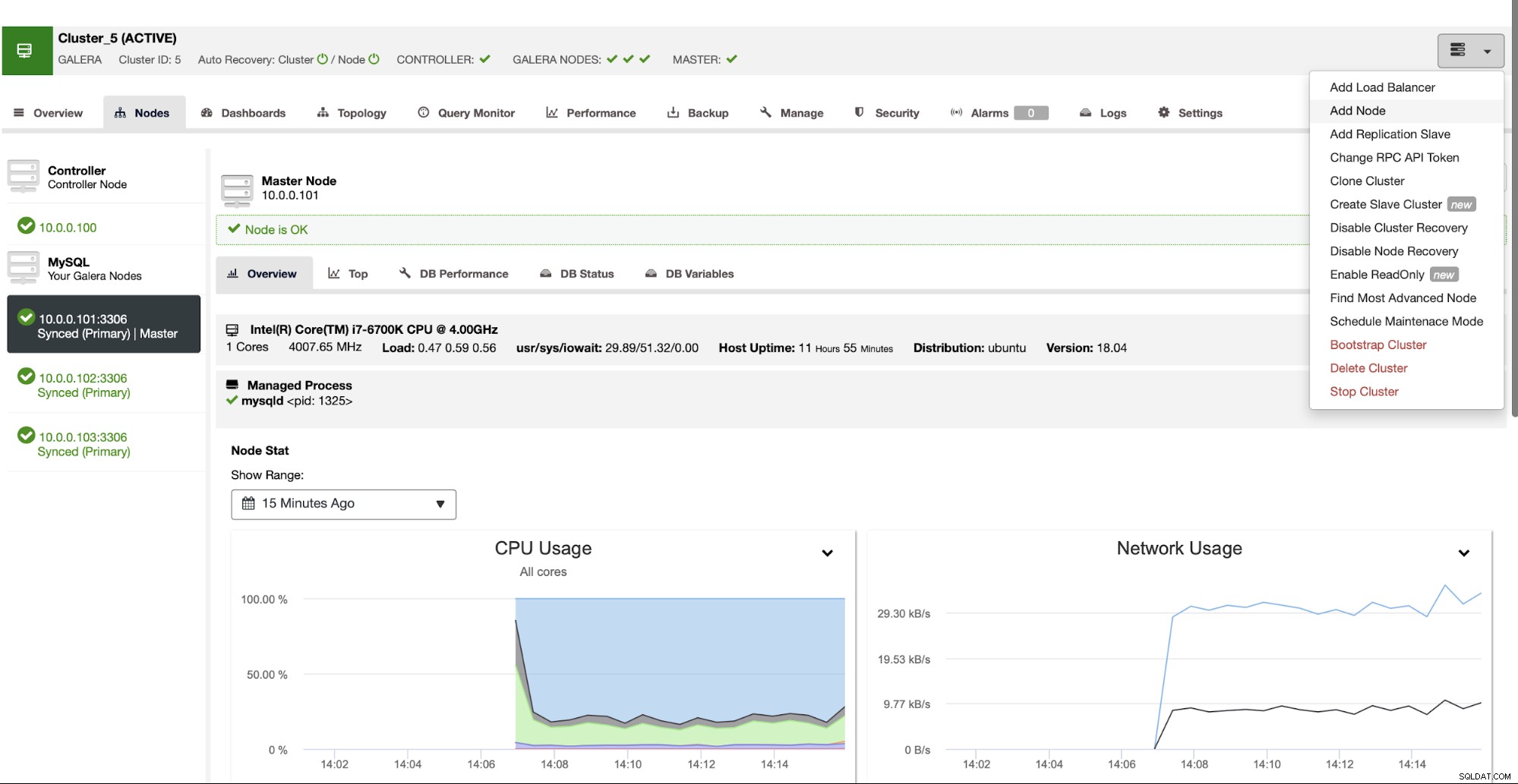
Cuando lo use, aparecerá la siguiente pantalla:
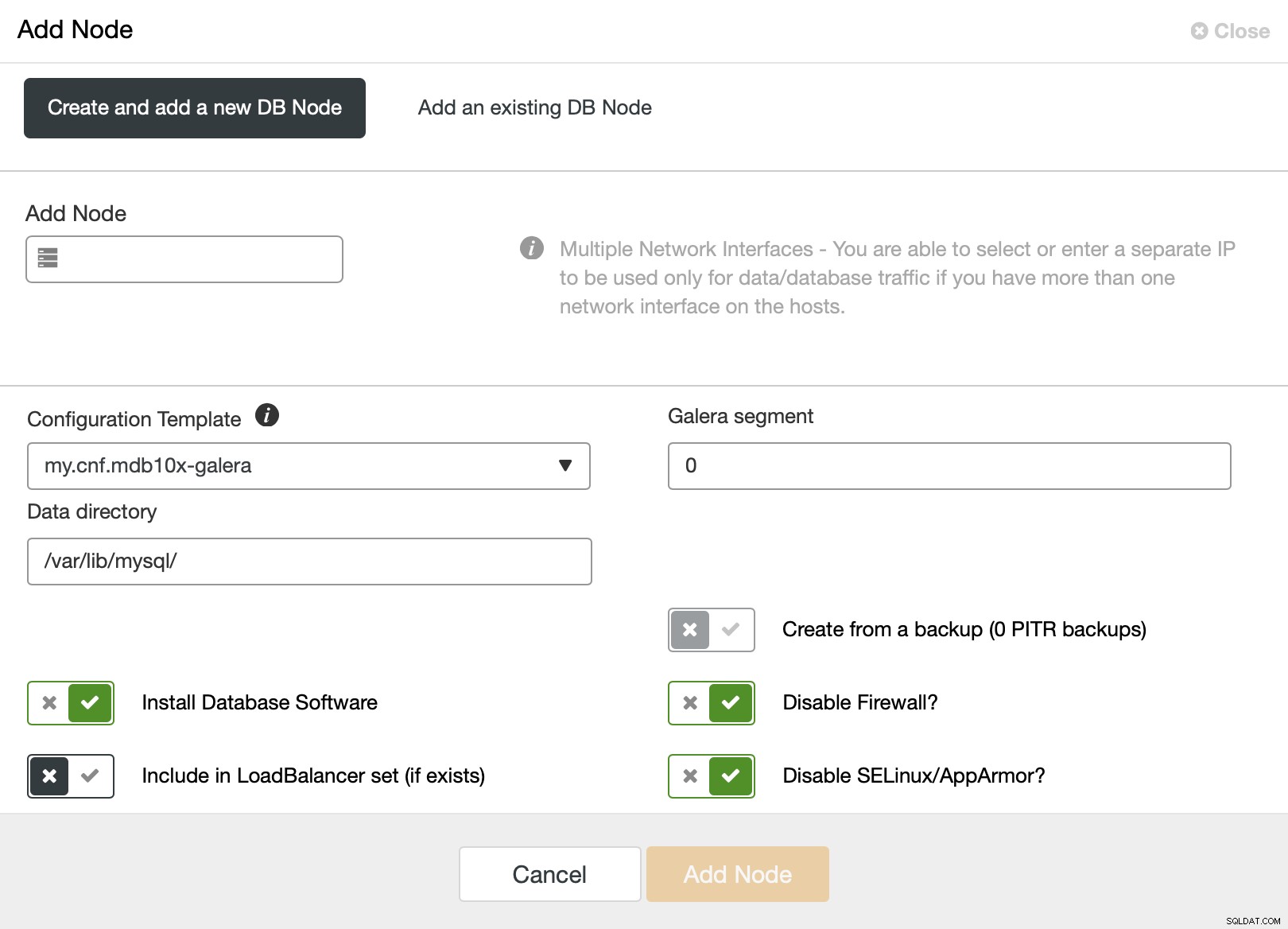
El segmento predeterminado es 0, por lo que desea cambiarlo a un valor diferente .
Después de agregar los nodos, puede verificar en qué segmento están ubicados mirando la pestaña Resumen:
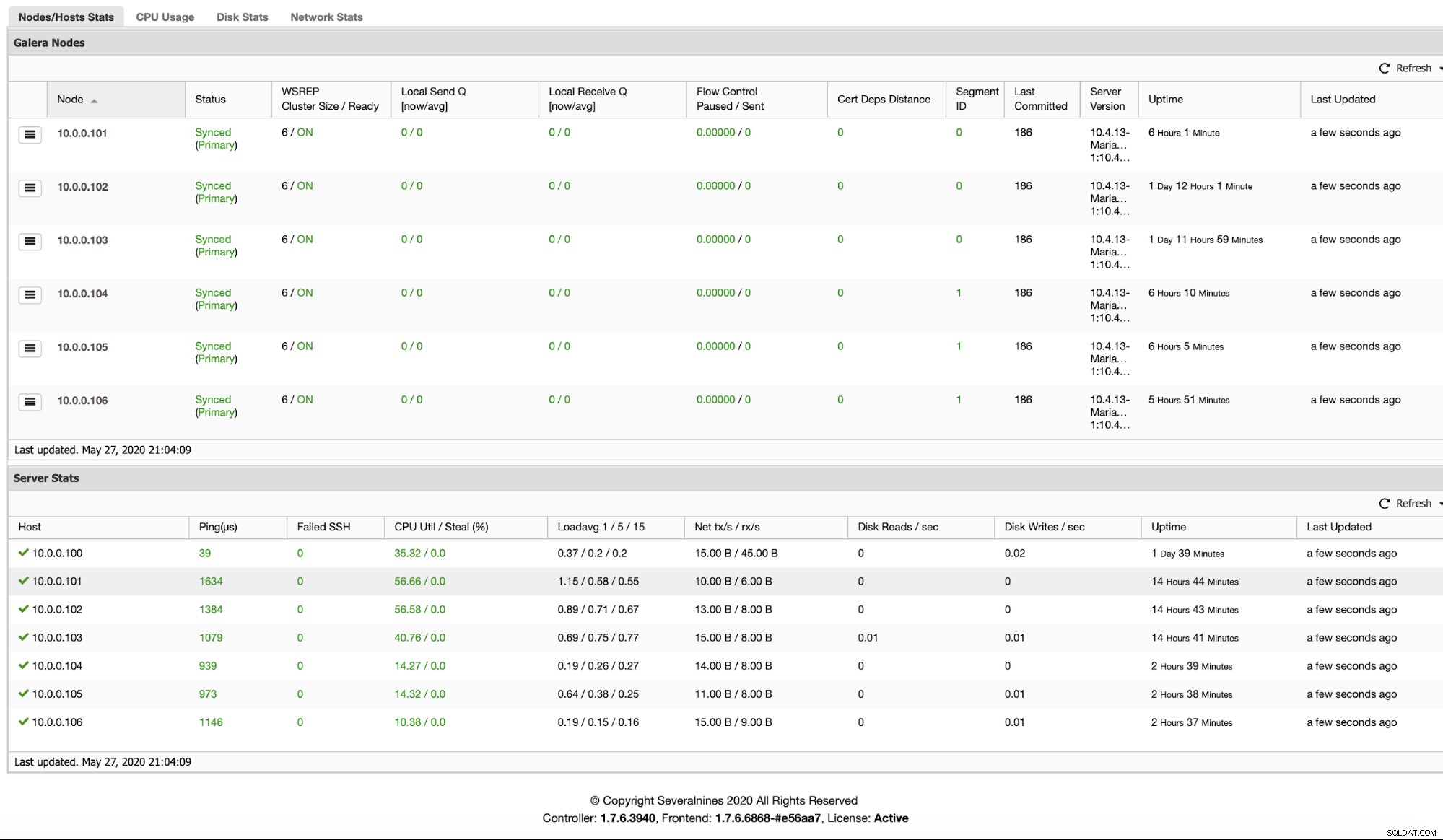
Conclusión
Esperamos que este breve blog le haya brindado una mejor comprensión de las opciones que tiene para las implementaciones de clústeres de MariaDB en múltiples nubes y cómo se pueden usar para garantizar una alta disponibilidad de su infraestructura de base de datos.