La configuración de un clúster de replicación maestro/esclavo es un caso de uso común en la mayoría de las organizaciones. El uso de MySQL Replication permite que sus datos se repliquen en diferentes entornos y garantiza que la información se copie. Es asíncrono y de subproceso único (por defecto), pero la replicación también le permite configurarlo para que sea síncrono (o en realidad "semi-síncrono") y puede ejecutar subprocesos esclavos en múltiples subprocesos o en paralelo.
Esta idea es muy común y generalmente llega con una configuración simple, haciendo que su esclavo sirva como recuperación o para soluciones de respaldo. Sin embargo, esto siempre tiene un precio, especialmente cuando se replican consultas incorrectas (como la falta de claves principales o únicas) o algún problema con el hardware (como problemas de E/S de disco o de red). Cuando ocurren estos problemas, el problema más común que se enfrenta es el retraso de la replicación.
Un retraso de replicación es el costo del retraso de las transacciones u operaciones calculado por la diferencia de tiempo de ejecución entre el nodo principal/maestro y el nodo en espera/esclavo. Los casos más ciertos en MySQL se basan en consultas incorrectas que se replican, como la falta de claves primarias o índices incorrectos, un hardware de red deficiente o una tarjeta de red que funciona mal, una ubicación distante entre diferentes regiones o zonas, o algunos procesos como la ejecución de copias de seguridad físicas pueden causar su base de datos MySQL para retrasar la aplicación de la transacción replicada actual. Este es un caso muy común cuando se diagnostican estos problemas. En este blog, veremos cómo lidiar con estos casos y qué buscar si experimenta un retraso en la replicación de MySQL.
El "MOSTRAR ESTADO DE ESCLAVO":El mantra de MySQL DBA
En algunos casos, esta es la panacea cuando se trata de retrasos en la replicación y revela principalmente todas las causas de un problema en su base de datos MySQL. Simplemente ejecute esta declaración SQL en su nodo esclavo que se sospecha que está experimentando un retraso en la replicación.
Los campos iniciales que son comunes para rastrear problemas son,
- Slave_IO_State - Te dice lo que está haciendo el hilo. Este campo le proporcionará una buena perspectiva si el estado de la replicación se ejecuta con normalidad, si enfrenta problemas de red, como volver a conectarse a un maestro, o tomar demasiado tiempo para enviar datos, lo que puede indicar problemas en el disco al sincronizar datos con el disco. También puede determinar este valor de estado al ejecutar SHOW PROCESSLIST.
- Archivo_de_registro_maestro - Nombre del archivo binlog del maestro donde se obtiene actualmente el subproceso de E/S.
- Read_Master_Log_Pos - posición del archivo binlog desde el maestro donde el subproceso de E/S de replicación ya ha leído.
- Relay_Log_File - el nombre del archivo de registro de retransmisión para el que el subproceso SQL está ejecutando actualmente los eventos
- Relay_Log_Pos - posición binlog del archivo especificado en Relay_Log_File para el cual ya se ejecutó el subproceso SQL.
- Relay_Master_Log_File - El archivo binlog del maestro que el subproceso SQL ya ejecutó y es congruente con el valor Read_Master_Log_Pos.
- Seconds_Behind_Master - este campo muestra una aproximación de la diferencia entre la marca de tiempo actual en el esclavo y la marca de tiempo en el maestro para el evento que se está procesando actualmente en el esclavo. Sin embargo, es posible que este campo no pueda indicarle el retraso exacto si la red es lenta porque la diferencia en segundos se toma entre el subproceso SQL esclavo y el subproceso E/S esclavo. Por lo tanto, puede haber casos en los que puede quedar atrapado con un subproceso de E/S esclavo de lectura lenta, pero lo domino ya es diferente.
- Slave_SQL_Running_State - estado del subproceso SQL y el valor es idéntico al valor de estado que se muestra en SHOW PROCESSLIST.
- Conjunto_Gtid_Recuperado - Disponible cuando se utiliza la replicación GTID. Este es el conjunto de GTID correspondientes a todas las transacciones recibidas por este esclavo.
- Conjunto_Gtid_ejecutado - Disponible cuando se utiliza la replicación GTID. Es el conjunto de GTID escritos en el registro binario.
Por ejemplo, tomemos el siguiente ejemplo que usa una replicación de GTID y está experimentando un retraso en la replicación:
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.10.70
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000038
Read_Master_Log_Pos: 826608419
Relay_Log_File: relay-bin.000004
Relay_Log_Pos: 468413927
Relay_Master_Log_File: binlog.000038
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 826608206
Relay_Log_Space: 826607743
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 251
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 45003
Master_UUID: 36272880-a7b0-11e9-9ca6-525400cae48b
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: copy to tmp table
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 36272880-a7b0-11e9-9ca6-525400cae48b:7631-9192
Executed_Gtid_Set: 36272880-a7b0-11e9-9ca6-525400cae48b:1-9191,
864dd532-a7af-11e9-85f2-525400cae48b:1-173,
df68c807-a7af-11e9-9b56-525400cae48b:1-4
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Al diagnosticar problemas como este, mysqlbinlog también puede ser su herramienta para identificar qué consulta se ha estado ejecutando en una posición binlog x e y específica. Para determinar esto, tomemos Retrieved_Gtid_Set, Relay_Log_Pos y Relay_Log_File. Vea el comando a continuación:
[[email protected] mysql]# mysqlbinlog --base64-output=DECODE-ROWS --include-gtids="36272880-a7b0-11e9-9ca6-525400cae48b:9192" --start-position=468413927 -vvv relay-bin.000004
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @[email protected]@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 468413927
#200206 4:36:14 server id 45003 end_log_pos 826608271 CRC32 0xc702eb4c GTID last_committed=1562 sequence_number=1563 rbr_only=no
SET @@SESSION.GTID_NEXT= '36272880-a7b0-11e9-9ca6-525400cae48b:9192'/*!*/;
# at 468413992
#200206 4:36:14 server id 45003 end_log_pos 826608419 CRC32 0xe041ec2c Query thread_id=24 exec_time=31 error_code=0
use `jbmrcd_date`/*!*/;
SET TIMESTAMP=1580963774/*!*/;
SET @@session.pseudo_thread_id=24/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
ALTER TABLE NewAddressCode ADD INDEX PostalCode(PostalCode)
/*!*/;
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
# End of log file
/*!50003 SET [email protected]_COMPLETION_TYPE*/;
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;Nos dice que estaba tratando de replicar y ejecutar una declaración DML que intenta ser la fuente del retraso. Esta tabla es una tabla enorme que contiene 13 millones de filas.
Marque MOSTRAR LISTA DE PROCESOS, MOSTRAR ESTADO INNODB DEL MOTOR, con la combinación de comandos ps, top, iostat
En algunos casos, SHOW SLAVE STATUS no es suficiente para decirnos quién es el culpable. Es posible que las declaraciones replicadas se vean afectadas por procesos internos que se ejecutan en el esclavo de la base de datos MySQL. Ejecutar las declaraciones SHOW [FULL] PROCESSLIST y SHOW ENGINE INNODB STATUS también proporciona datos informativos que le brindan información sobre el origen del problema.
Por ejemplo, supongamos que se está ejecutando una herramienta de evaluación comparativa que satura la E/S del disco y la CPU. Puede verificar ejecutando ambas declaraciones SQL. Combínalo con los comandos ps y top.
También puede determinar cuellos de botella en el almacenamiento de su disco ejecutando iostat, que proporciona estadísticas del volumen actual que está tratando de diagnosticar. Ejecutar iostat puede mostrar qué tan ocupado o cargado está su servidor. Por ejemplo, tomado por un esclavo que se está retrasando pero que también experimenta una alta utilización de E/S al mismo tiempo,
[[email protected] ~]# iostat -d -x 10 10
Linux 3.10.0-693.5.2.el7.x86_64 (testnode5) 02/06/2020 _x86_64_ (2 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.42 3.71 60.65 218.92 568.39 24.47 0.15 2.31 13.79 1.61 0.12 0.76
dm-0 0.00 0.00 3.70 60.48 218.73 568.33 24.53 0.15 2.36 13.85 1.66 0.12 0.76
dm-1 0.00 0.00 0.00 0.00 0.04 0.01 21.92 0.00 63.29 2.37 96.59 22.64 0.01
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.20 392.30 7983.60 2135.60 49801.55 12.40 36.70 3.84 13.01 3.39 0.08 69.02
dm-0 0.00 0.00 392.30 7950.20 2135.60 50655.15 12.66 36.93 3.87 13.05 3.42 0.08 69.34
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.06 183.67 0.00 183.67 61.67 1.85
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.40 370.93 6775.42 2557.04 46184.22 13.64 43.43 6.12 11.60 5.82 0.10 73.25
dm-0 0.00 0.00 370.93 6738.76 2557.04 47029.62 13.95 43.77 6.20 11.64 5.90 0.10 73.41
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.03 107.00 0.00 107.00 35.67 1.07
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 299.80 7253.35 1916.88 52766.38 14.48 30.44 4.59 15.62 4.14 0.10 72.09
dm-0 0.00 0.00 299.80 7198.60 1916.88 51064.24 14.13 30.68 4.66 15.70 4.20 0.10 72.57
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.10 215.50 8939.60 1027.60 67497.10 14.97 59.65 6.52 27.98 6.00 0.08 72.50
dm-0 0.00 0.00 215.50 8889.20 1027.60 67495.90 15.05 60.07 6.60 28.09 6.08 0.08 72.75
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.01 32.33 0.00 32.33 30.33 0.91
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.90 140.40 8922.10 625.20 54709.80 12.21 11.29 1.25 9.88 1.11 0.08 68.60
dm-0 0.00 0.00 140.40 8871.50 625.20 54708.60 12.28 11.39 1.26 9.92 1.13 0.08 68.83
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.01 27.33 0.00 27.33 9.33 0.28
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.70 284.50 8621.30 24228.40 51535.75 17.01 34.14 3.27 8.19 3.11 0.08 72.78
dm-0 0.00 0.00 290.90 8587.10 25047.60 53434.95 17.68 34.28 3.29 8.02 3.13 0.08 73.47
dm-1 0.00 0.00 0.00 2.00 0.00 8.00 8.00 0.83 416.45 0.00 416.45 63.60 12.72
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.30 851.60 11018.80 17723.60 85165.90 17.34 142.59 12.44 7.61 12.81 0.08 99.75
dm-0 0.00 0.00 845.20 10938.90 16904.40 83258.70 17.00 143.44 12.61 7.67 12.99 0.08 99.75
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.10 24.60 12965.40 420.80 51114.45 7.93 39.44 3.04 0.33 3.04 0.07 93.39
dm-0 0.00 0.00 24.60 12890.20 420.80 51114.45 7.98 40.23 3.12 0.33 3.12 0.07 93.35
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 3.60 13420.70 57.60 51942.00 7.75 0.95 0.07 0.33 0.07 0.07 92.11
dm-0 0.00 0.00 3.60 13341.10 57.60 51942.00 7.79 0.95 0.07 0.33 0.07 0.07 92.08
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00El resultado anterior muestra la alta utilización de E/S y las escrituras altas. También revela que el tamaño promedio de la cola y el tamaño promedio de la solicitud se están moviendo, lo que significa que es una indicación de una gran carga de trabajo. En estos casos, debe determinar si hay procesos externos que provocan que MySQL obstruya los subprocesos de replicación.
¿Cómo puede ayudar ClusterControl?
Con ClusterControl, lidiar con el retraso del esclavo y determinar al culpable es muy fácil y eficiente. Te lo dice directamente en la interfaz de usuario web, consulta a continuación:
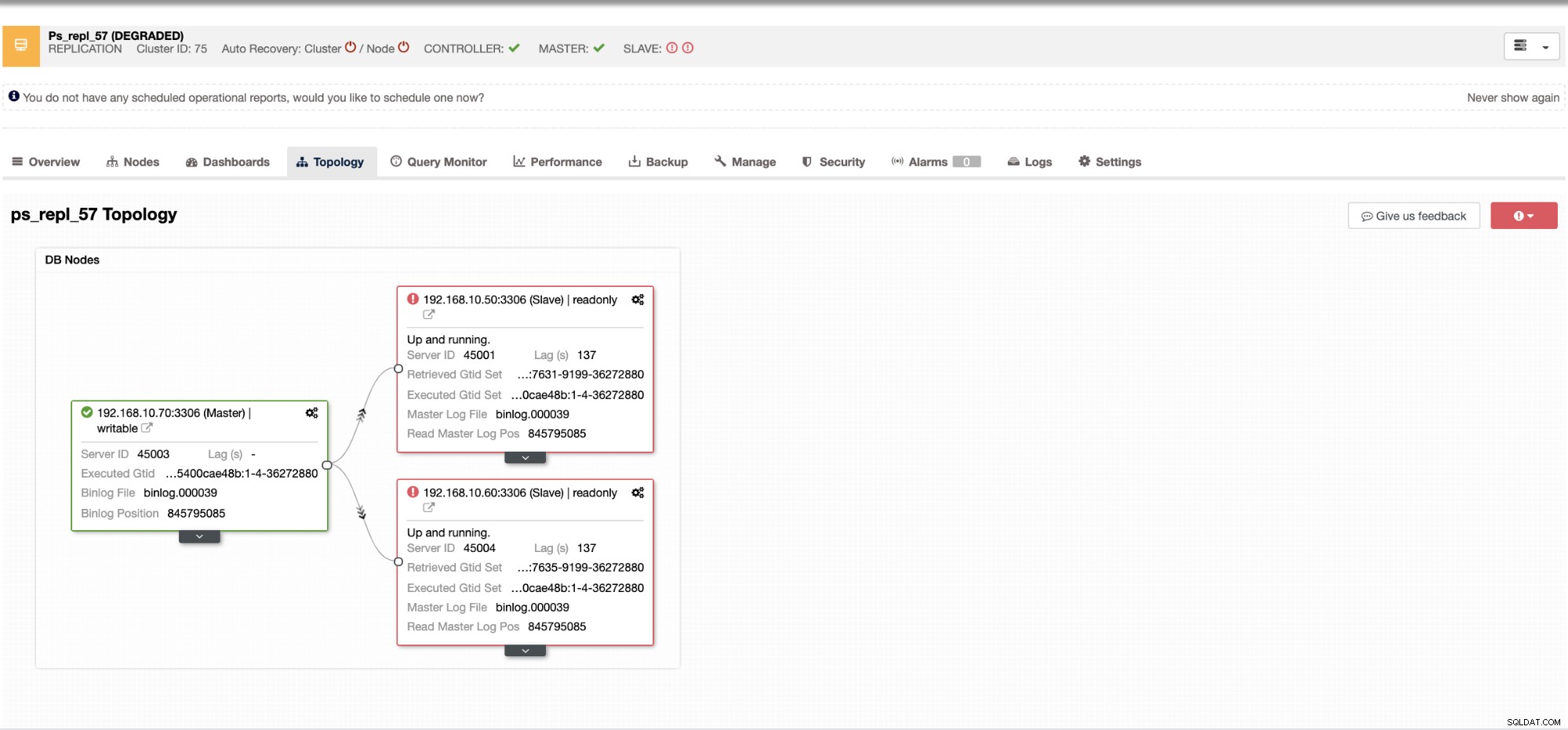
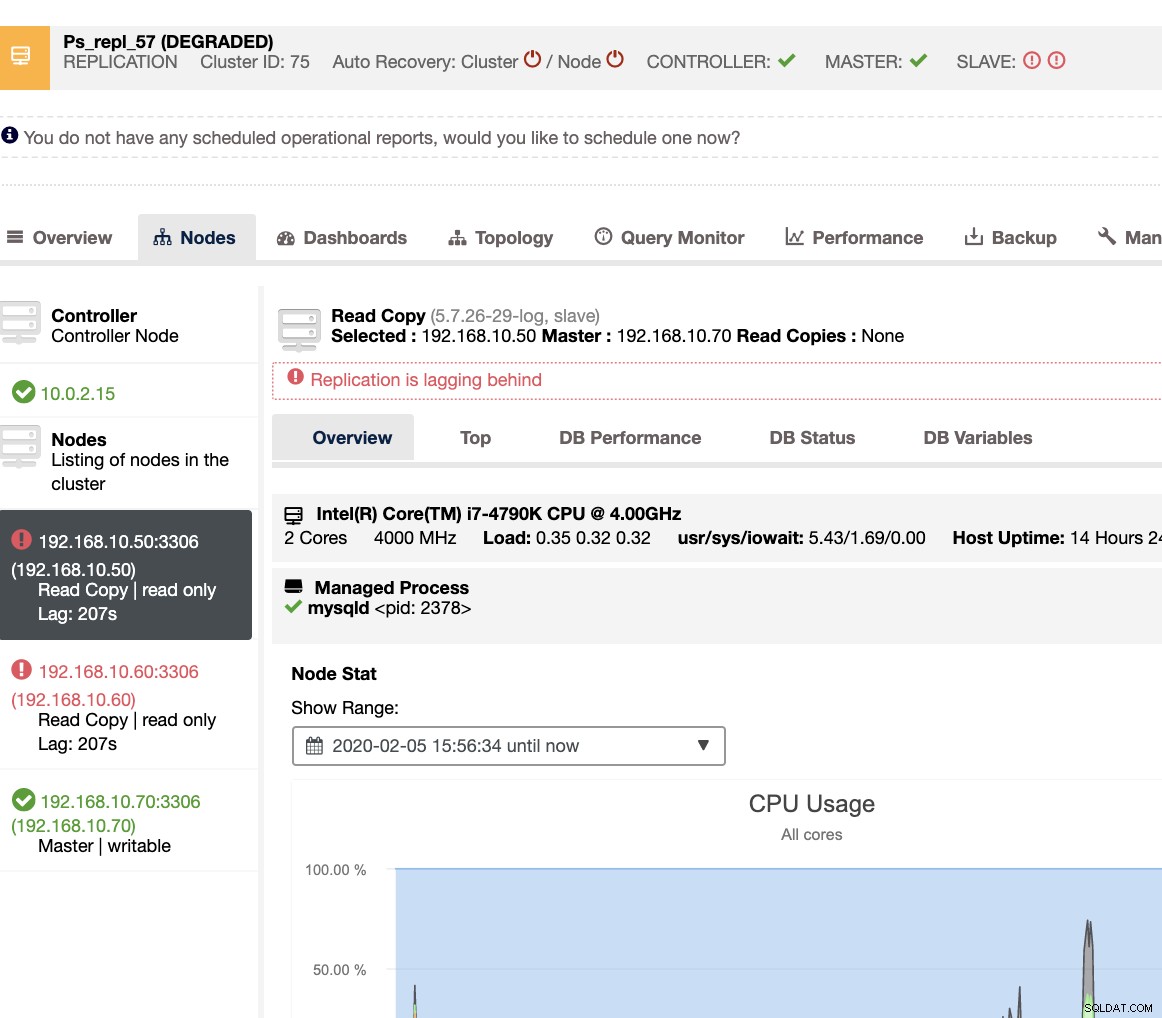
Le revela el retraso esclavo actual que experimentan sus nodos esclavos. No solo eso, con los tableros de SCUMM, si están habilitados, le brindan más información sobre el estado de su nodo esclavo o incluso de todo el clúster:
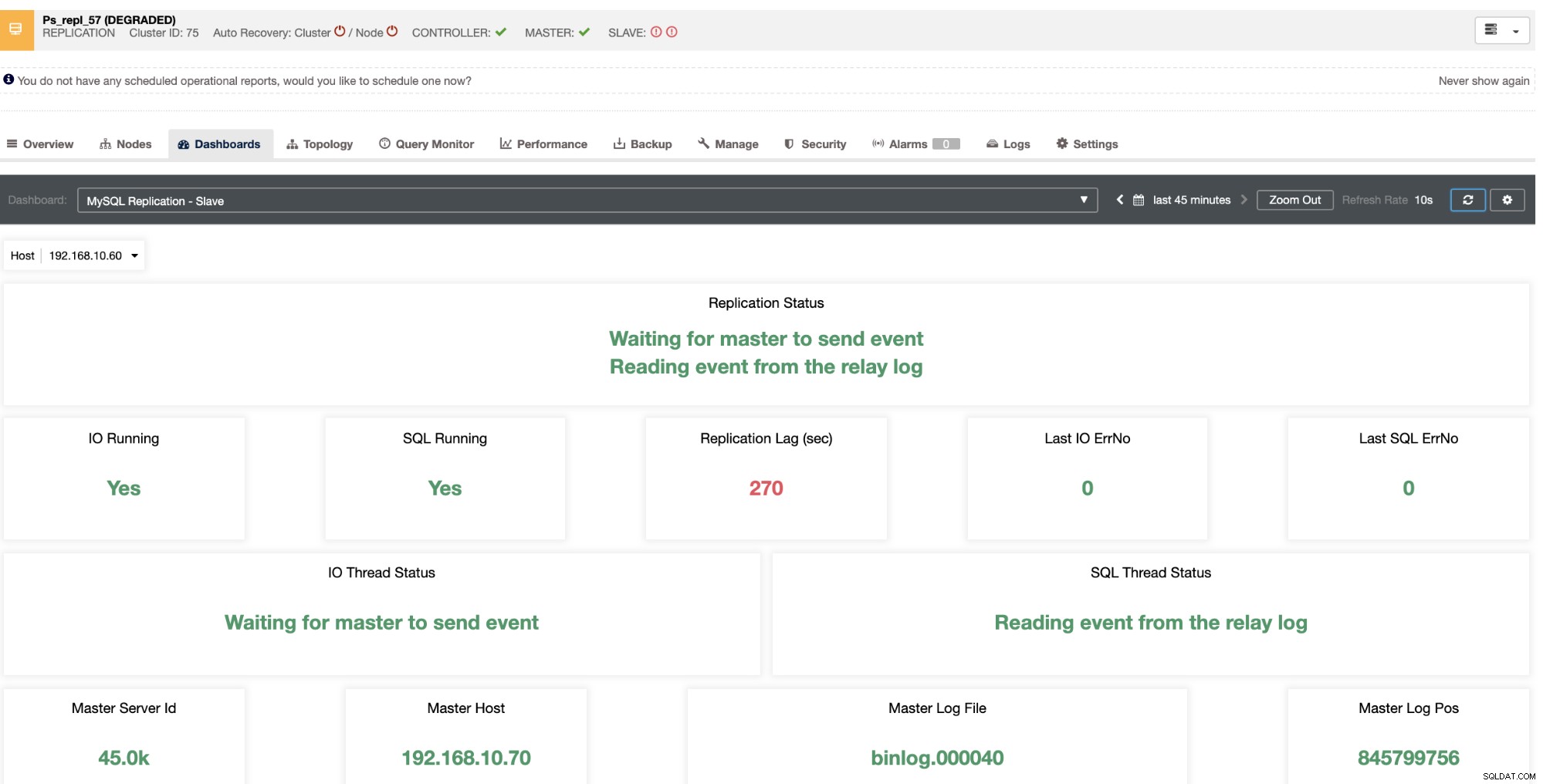


Estos elementos no solo están disponibles en ClusterControl, sino que también le proporcionan la capacidad de evitar que se produzcan consultas incorrectas con estas funciones, como se ve a continuación,
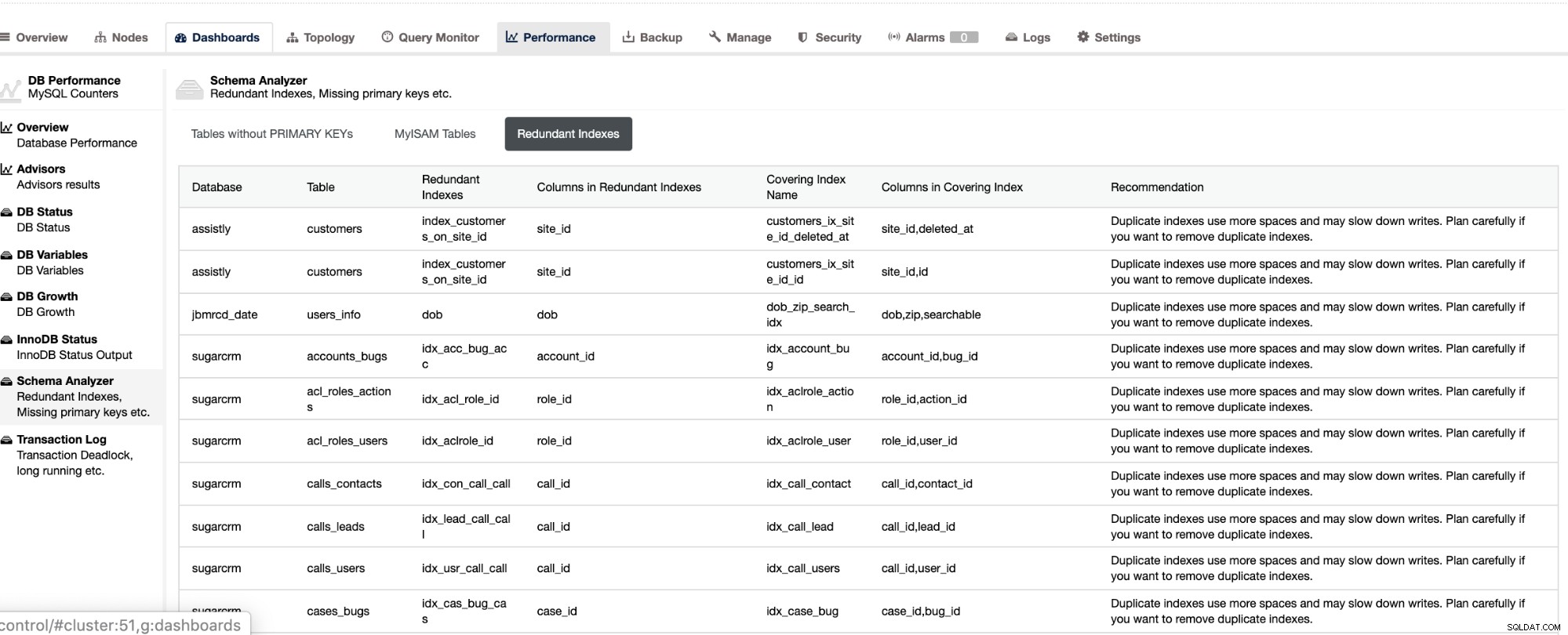
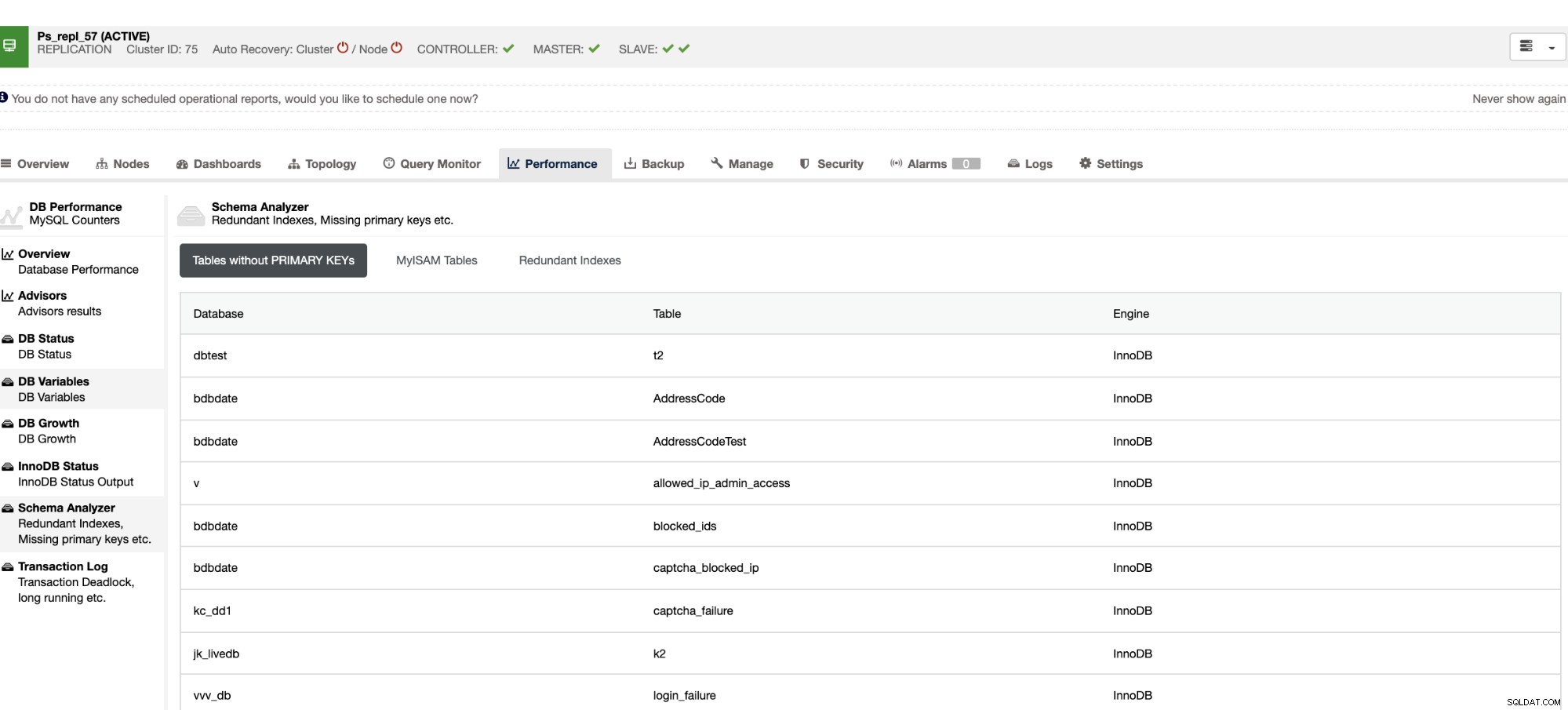
Los índices redundantes le permiten determinar que estos índices pueden causar problemas de rendimiento para consultas entrantes que hacen referencia a los índices duplicados. También le indica las tablas que no tienen claves primarias, lo que suele ser un problema común de retraso del esclavo cuando se realiza una determinada consulta SQL o transacciones que hacen referencia a tablas grandes sin claves primarias o únicas cuando se replican en los esclavos.
Conclusión
Lidiar con el retraso de la replicación de MySQL es un problema frecuente en una configuración de replicación maestro-esclavo. Puede ser fácil de diagnosticar, pero difícil de resolver. Asegúrese de tener sus tablas con clave principal o clave única existente, y determine los pasos y las herramientas sobre cómo solucionar problemas y diagnosticar la causa del retraso esclavo. Sin embargo, la eficiencia siempre es la clave cuando se resuelven problemas.