Si está administrando una base de datos de producción, es muy probable que haya tenido que clonar su base de datos en un servidor diferente al servidor de producción. El método básico para crear un clon es restaurar una base de datos a partir de una copia de seguridad reciente en otro servidor de base de datos. Otro método consiste en replicar desde una base de datos de origen mientras aún se está ejecutando, en cuyo caso es importante que la base de datos original no se vea afectada por ningún procedimiento de clonación.
¿Por qué necesitaría clonar una base de datos?
Un clúster de base de datos clonado es útil en varios escenarios:
- Solucione los problemas de su clúster de producción clonado en la seguridad de su entorno de prueba mientras realiza operaciones destructivas en la base de datos.
- Prueba de parche/actualización de una base de datos clonada para validar el proceso de actualización antes de aplicarlo al clúster de producción.
- Valide la copia de seguridad y la recuperación de un clúster de producción mediante un clúster clonado.
- Valide o pruebe nuevas aplicaciones en un clúster de producción clonado antes de implementarlo en el clúster de producción en vivo.
- Clone rápidamente la base de datos para requisitos de auditoría o cumplimiento de la información, por ejemplo, al final del trimestre o del año, cuando el contenido de la base de datos no debe cambiarse.
- Se puede crear una base de datos de informes a intervalos para evitar cambios de datos durante la generación de informes.
- Migrar una base de datos a nuevos servidores, nuevo entorno de implementación o un nuevo centro de datos.
Al ejecutar su infraestructura de base de datos en la nube, el costo de poseer un host (máquina virtual compartida o dedicada) es significativamente menor en comparación con la forma tradicional de alquilar espacio en un centro de datos o poseer un servidor físico. Además, la mayor parte de la implementación en la nube se puede automatizar fácilmente a través de las API del proveedor, el software del cliente y las secuencias de comandos. Por lo tanto, la clonación de un clúster puede ser una forma común de duplicar su entorno de implementación, por ejemplo, desde el desarrollo hasta la etapa de producción o viceversa.
No hemos visto que nadie en el mercado ofrezca esta función, por lo tanto, es nuestro privilegio mostrar cómo funciona con ClusterControl.
Clonación de un clúster MySQL Galera
Una de las características interesantes de ClusterControl es que le permite clonar rápidamente un MySQL Galera Cluster existente para que tenga una copia exacta del conjunto de datos en el otro clúster. ClusterControl realiza la operación de clonación en línea, sin bloqueos ni tiempos de inactividad en el clúster existente. Es como una operación de escalamiento horizontal del clúster, excepto que ambos clústeres son independientes entre sí una vez que se completa la sincronización. No es necesario que el clúster clonado tenga el mismo tamaño de clúster que el existente. Podríamos comenzar con un clúster de un nodo y ampliarlo con más nodos de base de datos en una etapa posterior.
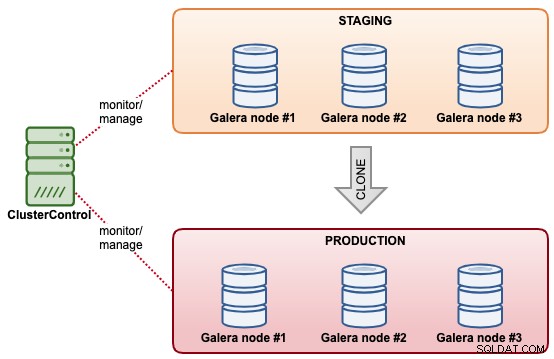
En este ejemplo, tenemos un clúster llamado "Puesta en escena" que nos gustaría clonar como otro clúster llamado "Producción". La premisa es que el clúster de ensayo ya almacenó los datos necesarios que pronto estarán en producción. El clúster de producción consta de otros 3 nodos, con especificaciones de producción.
El siguiente diagrama resume la arquitectura final de lo que queremos lograr:
Lo primero que debe hacer es configurar un SSH sin contraseña desde el servidor ClusterControl a los servidores de producción. En el servidor de ClusterControl, ejecute lo siguiente:
$ whoami
root
$ ssh-copy-id [email protected]
$ ssh-copy-id [email protected]
$ ssh-copy-id [email protected]Ingrese la contraseña raíz del servidor de destino si se le solicita.
Desde la lista de clústeres de la base de datos de ClusterControl, haga clic en el botón Acción del clúster y elija Clonar clúster. Aparecerá el siguiente asistente:
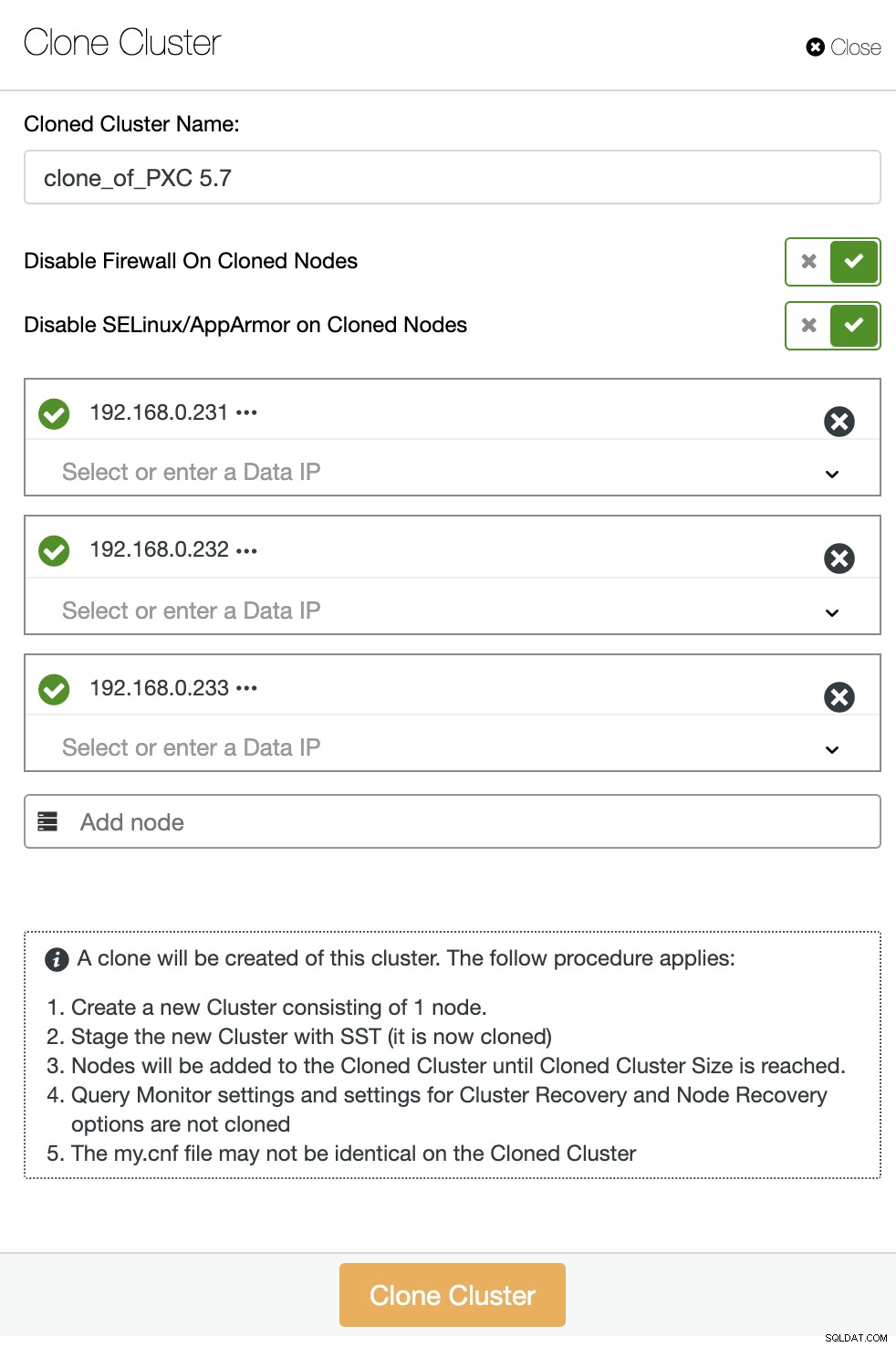
Especifique las direcciones IP o los nombres de host del nuevo clúster y asegúrese de obtener todo el icono de marca verde al lado del host especificado. El ícono verde significa que ClusterControl puede conectarse al host a través de SSH sin contraseña. Haga clic en el botón "Clonar clúster" para iniciar la implementación.
Los pasos de implementación son:
- Crear un nuevo clúster consta de un nodo.
- Sincronice el nuevo clúster de un nodo a través de SST. El donante es uno de los servidores de origen.
- Los nodos nuevos restantes se unirán al clúster después de que el donante del clúster clonado se sincronice con el clúster.
Una vez hecho esto, aparecerá un nuevo MySQL Galera Cluster en el panel de control del clúster ClusterControl una vez que se complete el trabajo de implementación.
Tenga en cuenta que la clonación del clúster solo clona los servidores de la base de datos y no toda la pila del clúster. Esto significa que ClusterControl no clonará otros componentes de soporte relacionados con el clúster, como los balanceadores de carga, la dirección IP virtual, el árbitro de Galera o el esclavo asíncrono. Sin embargo, si desea clonar como una copia exacta de su infraestructura de base de datos existente, puede lograrlo con ClusterControl implementando esos componentes por separado después de que se complete la operación de clonación de la base de datos.
Creación de un clúster de base de datos a partir de una copia de seguridad
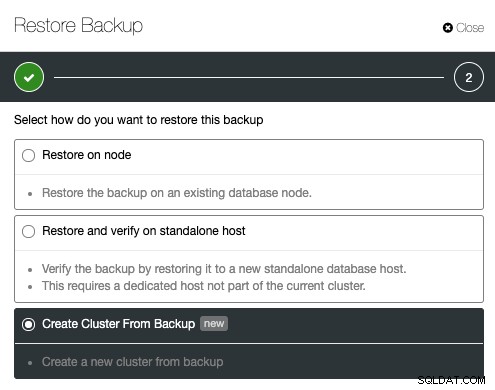
Otra función similar que ofrece ClusterControl es "Crear clúster desde la copia de seguridad". Esta función se introdujo en ClusterControl 1.7.1, específicamente para los clústeres de Galera Cluster y PostgreSQL, donde se puede crear un nuevo clúster a partir de la copia de seguridad existente. Contrario a la clonación de clústeres, esta operación no genera una carga adicional para el clúster de origen con el compromiso de que el clúster clonado no estará en el estado actual como el clúster de origen.
Para crear un clúster a partir de una copia de seguridad, debe crear una copia de seguridad que funcione. Para Galera Cluster, todos los métodos de copia de seguridad son compatibles, mientras que para PostgreSQL, solo pgbackrest no es compatible para la implementación de nuevos clústeres. Desde ClusterControl, se puede crear o programar una copia de seguridad fácilmente en ClusterControl -> Copias de seguridad -> Crear copia de seguridad. De la lista de la copia de seguridad creada, haga clic en Restaurar copia de seguridad, elija la copia de seguridad de la lista y seleccione "Crear clúster a partir de la copia de seguridad" en la opción de restauración:
En este ejemplo, vamos a implementar un nuevo clúster de replicación de transmisión de PostgreSQL para el entorno de ensayo, en función de la copia de seguridad existente que tenemos en el clúster de producción. El siguiente diagrama ilustra la arquitectura final:
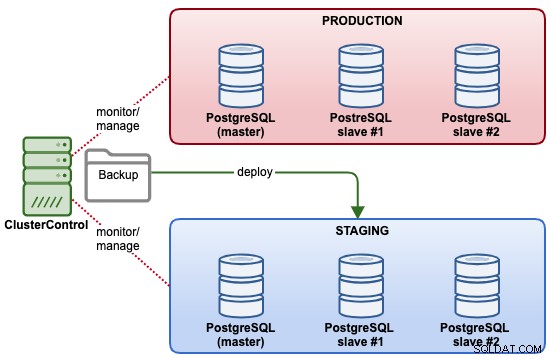
Lo primero que debe hacer es configurar un SSH sin contraseña desde el servidor ClusterControl a los servidores de producción. En el servidor de ClusterControl, ejecute lo siguiente:
$ whoami
root
$ ssh-copy-id [email protected]
$ ssh-copy-id [email protected]
$ ssh-copy-id [email protected]Cuando elija Crear clúster desde copia de seguridad, ClusterControl abrirá un cuadro de diálogo del asistente de implementación para ayudarlo a configurar el nuevo clúster:
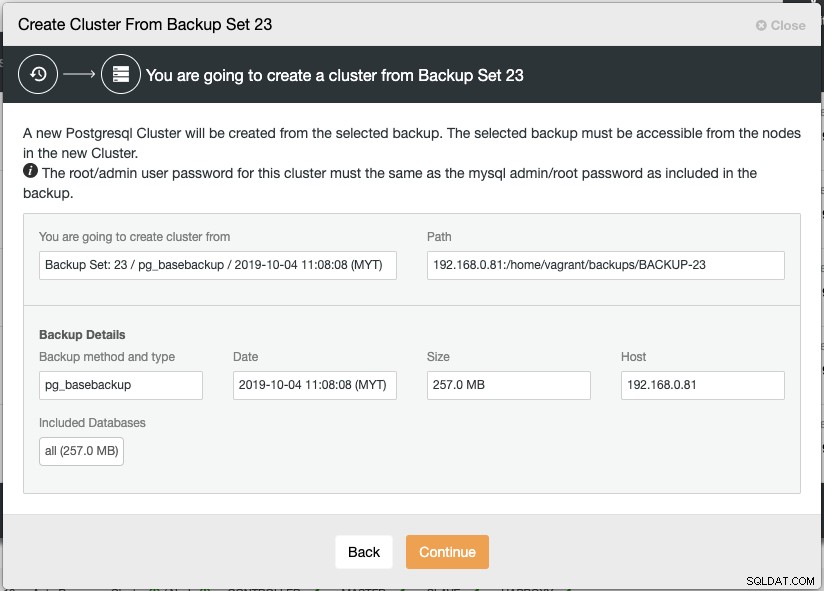
Se creará una nueva instancia de PostgreSQL Streaming Replication a partir de la copia de seguridad seleccionada, que se usará como el conjunto de datos base para el nuevo clúster. La copia de seguridad seleccionada debe ser accesible desde los nodos del nuevo clúster o almacenarse en el host de ClusterControl.
Al hacer clic en "Continuar" se abrirá el asistente de implementación de clúster de base de datos estándar:
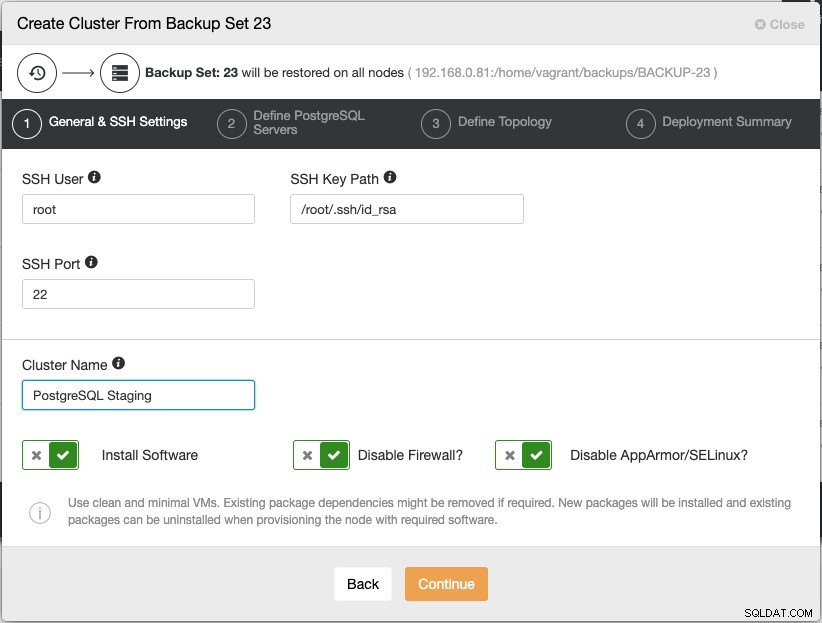
Tenga en cuenta que la contraseña de usuario root/admin para este clúster debe ser la misma que la contraseña de administrador/raíz de PostgreSQL como se incluye en la copia de seguridad. Siga el asistente de configuración correspondiente y ClusterControl luego realice la implementación en el siguiente orden:
- Instale los softwares y dependencias necesarios en todos los nodos de PostgreSQL.
- Inicie el primer nodo.
- Transmita y restaure la copia de seguridad en el primer nodo.
- Configure y agregue el resto de los nodos.
Una vez hecho esto, aparecerá un nuevo clúster de replicación de PostgreSQL en el panel del clúster de ClusterControl una vez que se complete el trabajo de implementación.