Desde que se lanzó ClusterControl 1.2.11 en 2015, se admite MariaDB MaxScale como equilibrador de carga de base de datos. A lo largo de los años, MaxScale ha crecido y madurado, agregando varias características ricas. Recientemente se lanzó MariaDB MaxScale 2.2 e introduce varias funciones nuevas, incluida la administración de conmutación por error del clúster de replicación.
MariaDB MaxScale permite implementaciones maestro/esclavo con alta disponibilidad, conmutación por error automática, conmutación manual y reincorporación automática. Si el maestro falla, MariaDB MaxScale puede promover automáticamente el esclavo más actualizado a maestro. Si se recupera el maestro fallido, MariaDB MaxScale puede reconfigurarlo automáticamente como esclavo del nuevo maestro. Además, los administradores pueden realizar un cambio manual para cambiar el maestro a pedido.
En nuestros blogs anteriores, discutimos cómo implementar MaxScale usando ClusterControl y cómo implementar MariaDB MaxScale en Docker. Para aquellos que aún no están familiarizados con MariaDB MaxScale, es un proxy de base de datos avanzado y complementario para servidores de bases de datos MariaDB. Maxscale se encuentra entre las aplicaciones de los clientes y los servidores de bases de datos, enrutando las consultas de los clientes y las respuestas de los servidores. También supervisa los servidores y detecta rápidamente cualquier cambio en el estado del servidor o en la topología de replicación.
Aunque Maxscale comparte algunas de las características de otras tecnologías de balanceo de carga como ProxySQL, esta nueva función de conmutación por error (que es parte de su mecanismo de monitoreo y detección automática) se destaca. En este blog vamos a discutir esta nueva y emocionante función de Maxscale.
Descripción general del mecanismo de conmutación por error MariaDB MaxScale
Detección maestra
Ahora es menos probable que el monitor cambie repentinamente el servidor maestro, incluso si otro servidor tiene más esclavos que el maestro actual. El DBA puede forzar una reselección de maestro configurando el maestro actual como de solo lectura o eliminando todos sus esclavos si el maestro está inactivo.
Solo un servidor puede tener el indicador de estado Maestro a la vez, incluso en una configuración multimaestro. Otros servidores en el grupo multimaestro reciben los indicadores de estado Relay Master y Slave.
Selección automática de cambio de nuevo maestro
El comando de conmutación ahora se puede llamar con solo el nombre de la instancia del monitor como parámetro. En este caso, el monitor seleccionará automáticamente un servidor para la promoción.
Detección de retraso en la replicación
La medición del retraso de replicación ahora simplemente lee el Seconds_Behind_Master -campo de la salida de estado de esclavos de los esclavos. El esclavo calcula este valor comparando la marca de tiempo en el evento binlog que el esclavo está procesando actualmente con el propio reloj del esclavo. Si un esclavo tiene varias conexiones de esclavo, se utiliza el retraso más pequeño.
Conmutación automática después de la detección de poco espacio en disco
Con las versiones recientes del servidor MariaDB, el monitor ahora puede verificar el espacio en disco en el backend y detectar si el servidor se está agotando. Cuando esto sucede, el monitor se puede configurar para cambiar automáticamente desde un maestro con poco espacio en disco. Los esclavos también se pueden configurar en modo de mantenimiento. El espacio en disco también es un factor que se tiene en cuenta al seleccionar qué nuevo maestro promocionar.
Consulte switchover_on_low_disk_space y maintenance_on_low_disk_space para obtener más información.
Función de restablecimiento de replicación
El reinicio-replicación El comando monitor elimina todas las conexiones esclavas y los registros binarios y luego configura la replicación. Útil cuando los datos están sincronizados pero los gtid no.
Manejo de eventos programados en conmutación por error/conmutación/reunión
Los eventos del servidor iniciados por el subproceso del programador de eventos ahora se manejan durante las operaciones de modificación del clúster. Consulte handle_server_events para obtener más información.
Soporte maestro externo
El monitor puede detectar si un servidor en el clúster se está replicando desde un maestro externo (un servidor que no está siendo monitoreado por el monitor MaxScale). Si el servidor de replicación es el servidor maestro del clúster, se considera que el propio clúster tiene un maestro externo.
Si ocurre una conmutación por error/conmutación, el nuevo servidor maestro se configura para replicar desde el servidor maestro externo del clúster. El nombre de usuario y la contraseña para la replicación se definen en replication_user y replication_password. La dirección y el puerto utilizados son los que muestra MOSTRAR EL ESTADO DE TODOS LOS ESCLAVOS en el antiguo servidor maestro del clúster. En el caso de la conmutación, el antiguo maestro también deja de replicar desde el servidor externo para preservar la topología.
Después de la conmutación por error, el nuevo maestro se replica desde el maestro externo. Si el antiguo maestro fallido vuelve a estar en línea, también se está replicando desde el servidor externo. Para normalizar la situación, active auto_rejoin o ejecute manualmente un reinicio. Esto redirigirá el maestro antiguo al maestro del clúster actual.
¿Cómo es útil y aplicable la conmutación por error?
La conmutación por error lo ayuda a minimizar el tiempo de inactividad, realizar el mantenimiento diario o manejar el mantenimiento desastroso y no deseado que a veces puede ocurrir en momentos desafortunados. Con la capacidad de MaxScale para aislar las aplicaciones cliente de los servidores de bases de datos back-end, agrega una funcionalidad valiosa que ayuda a minimizar el tiempo de inactividad.
El complemento de monitoreo MaxScale monitorea continuamente el estado de los servidores de base de datos back-end. El complemento de enrutamiento de MaxScale luego usa esta información de estado para enrutar siempre las consultas a los servidores de base de datos back-end que están en servicio. Luego, puede enviar consultas a los clústeres de bases de datos back-end, incluso si algunos de los servidores de un clúster están en mantenimiento o fallan.
La alta capacidad de configuración de MaxScale permite que los cambios en la configuración del clúster permanezcan transparentes para las aplicaciones cliente. Por ejemplo, si es necesario agregar o eliminar administrativamente un nuevo servidor de un clúster maestro-esclavo, simplemente puede agregar la configuración de MaxScale a la lista de complementos de monitor y enrutador del servidor a través de la consola CLI de maxadmin. La aplicación cliente no se dará cuenta de este cambio y continuará enviando consultas de la base de datos al puerto de escucha de MaxScale.
Configurar un servidor de base de datos en mantenimiento es simple y fácil. Simplemente ejecute el siguiente comando usando maxctrl y MaxScale dejará de enviar consultas a este servidor. Por ejemplo,
maxctrl: set server DB_785 maintenance
OKLuego verificando el estado de los servidores de la siguiente manera,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘Una vez en modo de mantenimiento, MaxScale dejará de enrutar cualquier solicitud nueva al servidor. Para las solicitudes actuales, MaxScale no eliminará estas sesiones, sino que permitirá que complete su ejecución y no interrumpirá ninguna consulta en ejecución mientras esté en modo de mantenimiento. Además, tenga en cuenta que el modo de mantenimiento no es persistente. Si MaxScale se reinicia cuando un nodo está en modo de mantenimiento, una nueva instancia de MariaDB MaxScale no respetará este modo. Si se configuran varias instancias de MariaDB MaxScale para usar el nodo, se debe establecer el modo de mantenimiento dentro de cada instancia de MariaDB MaxScale. Sin embargo, si varios servicios dentro de una instancia de MariaDB MaxScale están usando el servidor, solo necesita configurar el modo de mantenimiento una vez en el servidor para que todos los servicios tomen nota del cambio de modo.
Una vez que haya terminado con su mantenimiento, simplemente borre el servidor con el siguiente comando. Por ejemplo,
maxctrl: clear server DB_785 maintenance
OKPara comprobar si se ha vuelto a la normalidad, simplemente ejecute el comando servidores de lista .
También puede aplicar ciertas acciones administrativas a través de la interfaz de usuario de ClusterControl. Vea la captura de pantalla de ejemplo a continuación:
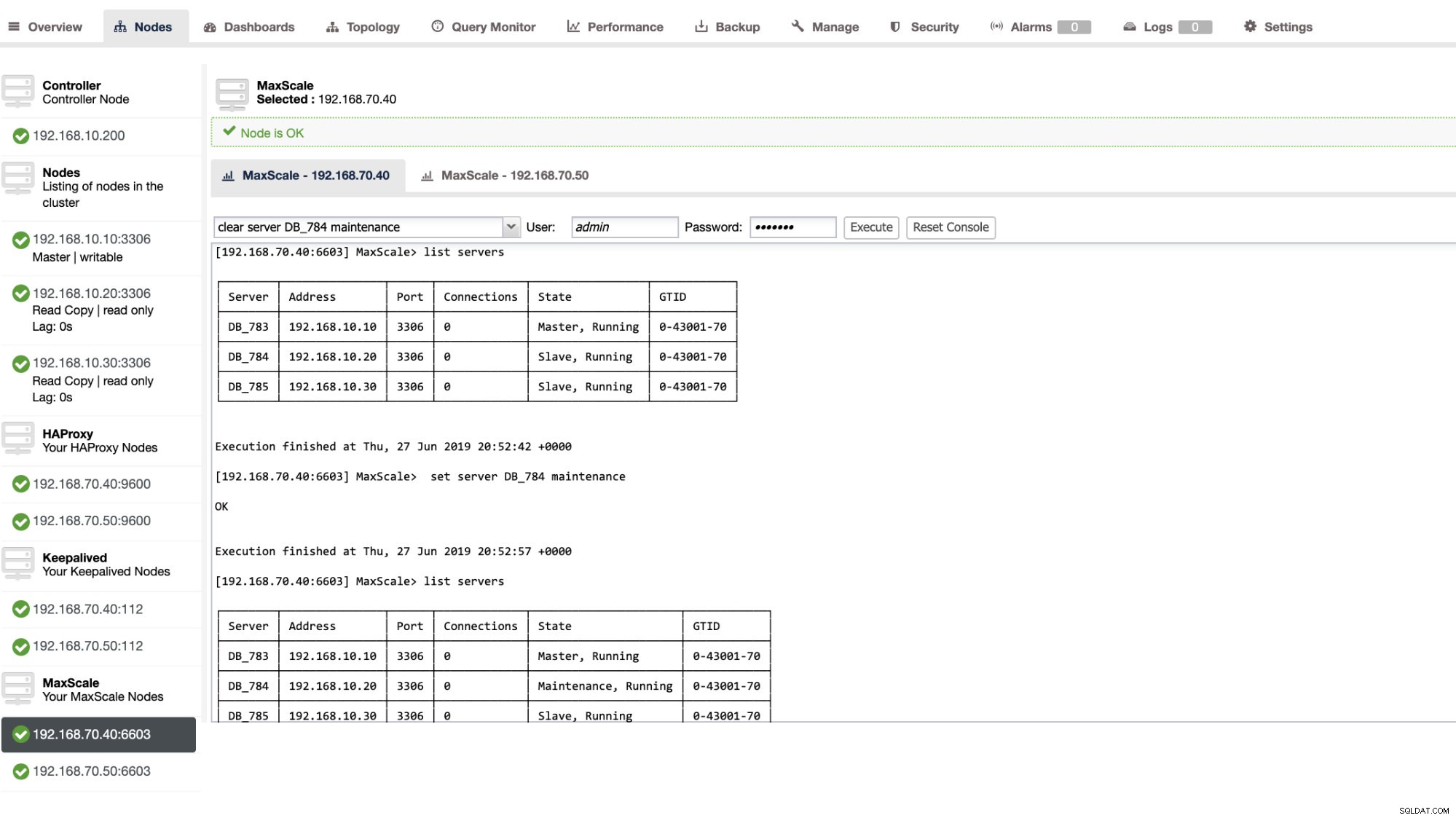
MaxScale Failover en acción
La conmutación por error automática
La conmutación por error MaxScale de MariaDB funciona de manera muy eficiente y reconfigura el esclavo según lo esperado. En esta prueba, tenemos el siguiente conjunto de archivos de configuración que fue creado y administrado por ClusterControl. Ver a continuación:
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonTenga en cuenta que, solo el auto_failover y auto_rejoin son las variables que he agregado ya que ClusterControl no agregará esto de manera predeterminada una vez que configure un balanceador de carga MaxScale (consulte este blog sobre cómo configurar MaxScale usando ClusterControl). No olvide que debe reiniciar MariaDB MaxScale una vez que haya aplicado los cambios en su archivo de configuración. Solo corre,
systemctl restart maxscaley estás listo para irte.
Antes de continuar con la prueba de conmutación por error, primero verifiquemos el estado del clúster:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘¡Se ve genial!
Eliminé al maestro con solo el comando asesino puro KILL -9 $(pidof mysqld) en mi nodo maestro y observé, sin sorpresa, que el monitor se dio cuenta rápidamente de esto y provocó la conmutación por error. Vea los registros de la siguiente manera:
2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]Ahora echemos un vistazo a la salud de su clúster,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘El nodo 192.168.10.10 que anteriormente era el maestro se ha caído. Intenté reiniciar y ver si se activaba la reincorporación automática, y como notó en el registro en el momento 2019-06-28 06:39:20.165, ha sido muy rápido para captar el estado del nodo y luego establece la configuración automáticamente sin problemas para que el DBA lo encienda.
Ahora, comprobando por último su estado, parece funcionar perfectamente como se esperaba. Ver a continuación:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Mi ex-maestro ha sido reparado y recuperado y quiero cambiar
Cambiar a su maestro anterior tampoco es una molestia. Puede operar esto con maxctrl (o maxadmin en versiones anteriores de MaxScale) o a través de la interfaz de usuario de ClusterControl (como se demostró anteriormente).
Vamos a referirnos al estado anterior de la salud del clúster de replicación anterior, y queríamos cambiar el 192.168.10.10 (actualmente esclavo), de vuelta a su estado maestro. Antes de continuar, es posible que deba identificar primero el monitor que va a utilizar. Puede verificar esto con el siguiente comando a continuación:
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘Una vez que lo tenga, puede hacer el siguiente comando a continuación para cambiar:
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OKLuego verifique nuevamente el estado del clúster,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘¡Se ve perfecto!
Los registros le mostrarán detalladamente cómo fue y su serie de acciones durante el cambio. Vea los detalles a continuación:
2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]En el caso de un cambio incorrecto, no procederá y, por lo tanto, generará un error como se muestra en el registro anterior. Así estarás a salvo y sin sorpresas aterradoras.
Hacer que su MaxScale sea altamente disponible
Si bien está un poco fuera de tema con respecto a la conmutación por error, quería agregar algunos puntos valiosos aquí con respecto a la alta disponibilidad y cómo se relaciona con la conmutación por error de MariaDB MaxScale.
Hacer que su MaxScale esté altamente disponible es una parte importante en caso de que su sistema se bloquee, experimente daños en el disco o daños en la máquina virtual. Estas situaciones son inevitables y pueden afectar el estado de su configuración de conmutación por error automatizada cuando ocurren estos ciclos de mantenimiento inesperados.
Para un entorno de tipo de clúster de replicación, esto es muy beneficioso y muy recomendable para una configuración específica de MaxScale. El propósito de esto es que solo se debe permitir que una instancia de MaxScale modifique el clúster en un momento dado. Si ha configurado con Keepalived, aquí es donde se encuentran las instancias con el estado de MAESTRO. MaxScale en sí no conoce su estado, pero con maxctrl (o maxadmin en versiones anteriores) puede establecer una instancia de MaxScale en modo pasivo. A partir de la versión 2.2.2, un MaxScale pasivo se comporta de manera similar a uno activo con la diferencia de que no realizará conmutación por error, conmutación ni reincorporación. Incluso las versiones manuales de estos comandos terminarán en error. Las diferencias de modo pasivo/activo pueden ampliarse en el futuro, así que esté atento a dichos cambios en MaxScale. Para hacer esto, simplemente haga lo siguiente:
maxctrl: alter maxscale passive true
OKPuede verificar esto después ejecutando el siguiente comando:
[[email protected] vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │Si desea ver cómo configurar la alta disponibilidad con Keepalived, consulte esta publicación de MariaDB.
Manejo VIP
Además, dado que MaxScale no tiene el manejo VIP incorporado, puede usar Keepalived para manejar eso por usted. Simplemente puede usar la virtual_ipaddress asignada al nodo de estado MASTER. Es probable que esto genere una administración de IP virtual tal como lo hace MHA con la variable master_failover_script. Como se mencionó anteriormente, consulte esta publicación de blog de configuración de Keepalived con MaxScale de MariaDB.
Conclusión
MariaDB MaxScale es rico en funciones y tiene mucha capacidad, no solo se limita a ser un proxy y un equilibrador de carga, sino que también ofrece el mecanismo de conmutación por error que buscan las grandes organizaciones. Es casi un software de talla única, pero por supuesto viene con las limitaciones que una determinada aplicación puede necesitar para contrastar otros balanceadores de carga como ProxySQL.
ClusterControl también ofrece un mecanismo de conmutación por error automático y detección automática maestra, además de recuperación de clústeres y nodos con la capacidad de implementar Maxscale y otras tecnologías de equilibrio de carga.
Cada una de estas herramientas tiene sus diversas características y funciones, pero MariaDB MaxScale es compatible con ClusterControl y se puede implementar de manera factible junto con Keepalived, HAProxy para ayudarlo a acelerar su tarea de rutina diaria.