Presto es un motor SQL de código abierto y distribución paralela para el procesamiento de big data. Fue desarrollado desde cero por Facebook. El primer lanzamiento interno tuvo lugar en 2013 y fue una solución bastante revolucionaria para sus problemas de big data.
Con los cientos de servidores geolocalizados y los petabytes de datos, Facebook comenzó a buscar una plataforma alternativa para sus clústeres de Hadoop. Su equipo de infraestructura quería reducir el tiempo necesario para ejecutar trabajos por lotes de análisis y simplificar el desarrollo de canalizaciones mediante el uso de un lenguaje de programación ampliamente conocido en la organización:SQL.
Según la fundación Presto, “Facebook usa Presto para consultas interactivas en varios almacenes de datos internos, incluido su almacén de datos de 300 PB. Más de 1000 empleados de Facebook usan Presto a diario para ejecutar más de 30 000 consultas que, en total, analizan más de un petabyte por día”.
Si bien Facebook tiene un entorno de almacenamiento de datos excepcional, los mismos desafíos están presentes en muchas organizaciones que manejan grandes datos.
En este blog, veremos cómo configurar un entorno presto básico utilizando un servidor Docker desde el archivo tar. Como fuente de datos, nos centraremos en la fuente de datos MySQL, pero podría ser cualquier otro RDBMS popular.
Ejecución de Presto en un entorno de Big Data
Antes de comenzar, echemos un vistazo rápido a sus principales principios de arquitectura. Presto es una alternativa a las herramientas que consultan HDFS mediante canalizaciones de trabajos de MapReduce, como Hive. A diferencia de Hive Presto, no usa MapReduce. Presto se ejecuta con un motor de ejecución de consultas de propósito especial con operadores de alto nivel y procesamiento en memoria.
A diferencia de Hive, Presto puede transmitir datos a través de todas las etapas a la vez ejecutando fragmentos de datos al mismo tiempo. Está diseñado para ejecutar consultas analíticas ad-hoc en fuentes de datos heterogéneas únicas o distribuidas. Puede llegar desde una plataforma Hadoop para consultar bases de datos relacionales u otros almacenes de datos como archivos planos.
Presto utiliza ANSI SQL estándar que incluye agregaciones, uniones o funciones de ventana analítica. SQL es bien conocido y mucho más fácil de usar en comparación con MapReduce escrito en Java.
Implementación de Presto en Docker
La configuración básica de Presto se puede implementar con una imagen de Docker preconfigurada o un tarball del servidor de Presto.
El servidor docker y los contenedores Presto CLI se pueden implementar fácilmente con:
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliPuede elegir entre dos versiones del servidor Presto. Versión comunitaria y versión Enterprise de Starburst. Dado que vamos a ejecutarlo en un entorno de espacio aislado que no sea de producción, utilizaremos la versión de Apache en este artículo.
Requisitos previos
Presto se implementa completamente en Java y requiere que JVM esté instalado en su sistema. Se ejecuta tanto en OpenJDK como en Oracle Java. La versión mínima es Java 8u151 o Java 11.
Para descargar JAVA JDK, visite https://openjdk.java.net/ o https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Puedes comprobar tu versión de Java con
$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)Instalación de Presto
Para instalar Presto, vamos a descargar el archivo tar del servidor y el ejecutable jar CLI de Presto.
El tarball contendrá un único directorio de nivel superior, presto-server-0.223, al que llamaremos directorio de instalación.
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoAdemás, Presto necesita un directorio de datos para almacenar registros, etc.
Se recomienda crear un directorio de datos fuera del directorio de instalación.
$ mkdir -p ~/data/presto/Esta ubicación es el lugar donde comenzamos nuestra solución de problemas.
Configuración de Presto
Antes de comenzar nuestra primera instancia, necesitamos crear un montón de archivos de configuración. Comience con la creación de un directorio etc/ dentro del directorio de instalación. Esta ubicación contendrá los siguientes archivos de configuración:
etc/
- Propiedades del nodo:configuración ambiental del nodo
- Configuración de JVM (jvm.config):configuración de la máquina virtual de Java
- Config Properties(config.properties) -configuración para el servidor Presto
- Propiedades del catálogo:configuración para conectores (fuentes de datos)
- Propiedades de registro:configuración de registradores
A continuación puede encontrar algunas configuraciones básicas para ejecutar Presto sandbox. Para más detalles visite la documentación.
vi etc/config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = http://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc/nodo.propiedades
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoLa estructura básica etc/ puede tener el siguiente aspecto:

El siguiente paso es configurar el conector MySQL.
Vamos a conectarnos a uno de los 3 nodos de MariaDB Cluster.
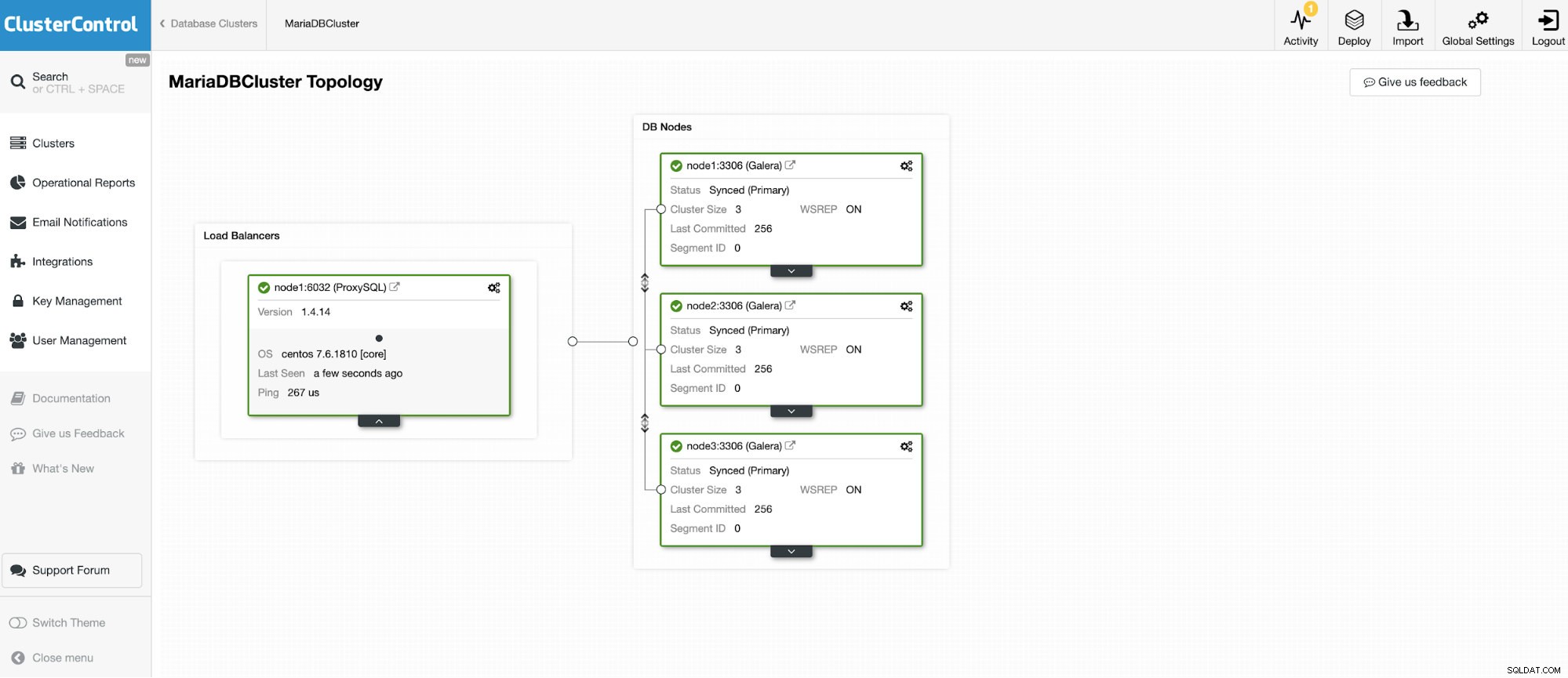
Y otra instancia independiente que ejecuta Oracle MySQL 5.7.
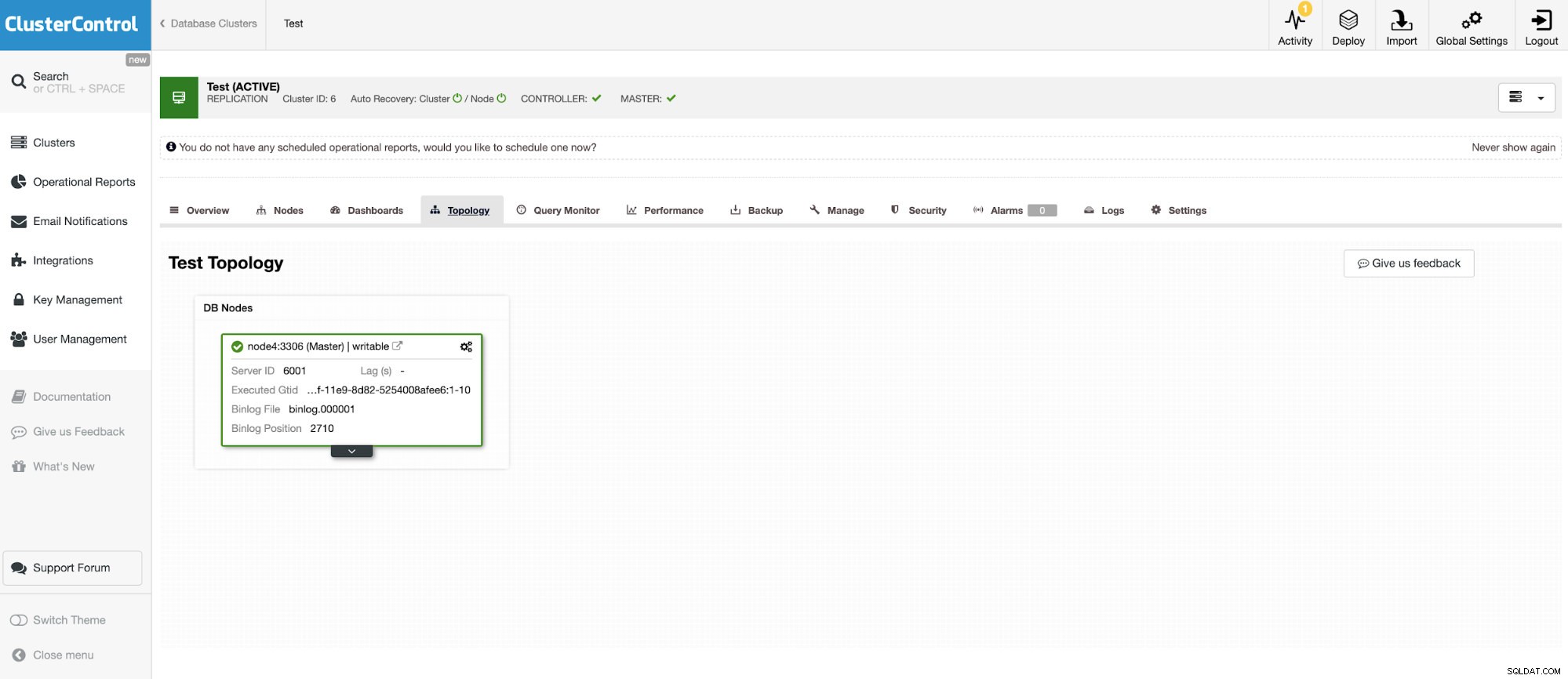
El conector MySQL permite consultar y crear tablas en una base de datos MySQL externa. Esto se puede usar para unir datos entre diferentes sistemas como MariaDB y MySQL de Oracle.
Presto utiliza conectores enchufables y la configuración es muy fácil. Para configurar el conector MySQL, cree un archivo de propiedades de catálogo en etc/catalog llamado, por ejemplo, mysql.properties, para montar el conector MySQL como catálogo mysql. Cada uno de los archivos que representan una conexión a otro servidor. En este caso, tenemos dos archivos:
vi etc/catalog/mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvietc/catalog/mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretEjecución de Presto
Cuando todo esté listo, es hora de iniciar la instancia de Presto. Para iniciar presto, vaya al directorio bin en la instalación de preso y ejecute lo siguiente:
$ bin/launcher start
Started as 18363Para detener la ejecución de Presto
$ bin/launcher stopAhora, cuando el servidor está en funcionamiento, podemos conectarnos a Presto con CLI y consultar la base de datos MySQL.
Para iniciar la ejecución de la consola de Presto:
./presto --server localhost:8080 --catalog mysql --schema employeesAhora podemos consultar nuestras bases de datos a través de CLI.
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]
Tanto el clúster de bases de datos MariaDB como MySQL se han alimentado con la base de datos de los empleados.
wget https://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlEl estado de la consulta también se puede ver en la consola web de Presto:http://localhost:8080/ui/#
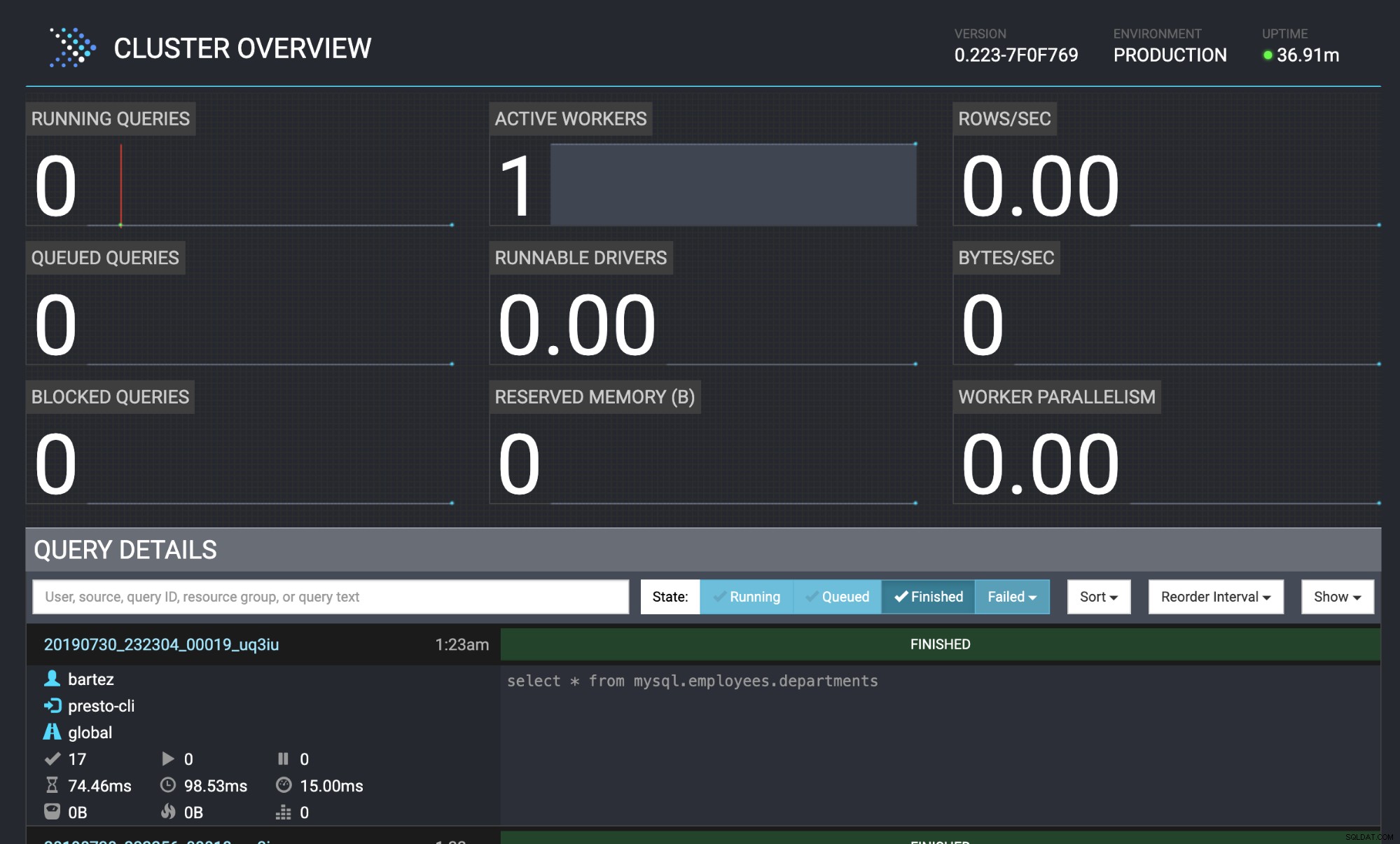 Descripción general del clúster de Presto
Descripción general del clúster de Presto Conclusión
Muchas empresas conocidas (como Airbnb, Netflix, Twitter) están adoptando Presto para un rendimiento de baja latencia. Sin duda, es un software muy interesante que puede eliminar la necesidad de ejecutar procesos pesados de almacenamiento de datos ETL. En este blog, solo analizamos brevemente el conector MySQL, pero puede usarlo para analizar datos de HDFS, almacenes de objetos, RDBMS (SQL Server, Oracle, PostgreSQL), Kafka, Cassandra, MongoDB y muchos otros.