La alta disponibilidad es un alto porcentaje de tiempo que el sistema está funcionando y respondiendo de acuerdo con las necesidades del negocio. Para los sistemas de bases de datos de producción, la máxima prioridad suele ser mantenerla cerca del 100 %. Creamos clústeres de bases de datos para eliminar todos los puntos únicos de falla. Si una instancia deja de estar disponible, otro nodo debería poder asumir la carga de trabajo y continuar desde allí. En un mundo perfecto, un clúster de base de datos resolvería todos los problemas de disponibilidad de nuestro sistema. Desafortunadamente, si bien todo puede verse bien en el papel, la realidad suele ser diferente. Entonces, ¿dónde puede salir mal?
Los sistemas de bases de datos transaccionales vienen con sofisticados motores de almacenamiento. Mantener la coherencia de los datos en varios nodos hace que esta tarea sea mucho más difícil. La agrupación en clústeres introduce una serie de nuevas variables que dependen en gran medida de la red y la infraestructura subyacente. No es raro que una instancia de base de datos independiente que funcionaba bien en un solo nodo de repente funcione mal en un entorno de clúster.
Entre la cantidad de cosas que pueden afectar la disponibilidad del clúster, los problemas de latencia juegan un papel crucial. Sin embargo, ¿cuál es la latencia? ¿Está solo relacionado con la red?
El término "latencia" en realidad se refiere a varios tipos de retrasos en los que se incurre en el procesamiento de datos. Es el tiempo que tarda una pieza de información en pasar de un escenario a otro.
En esta publicación de blog, veremos las dos principales soluciones de alta disponibilidad para MySQL y MariaDB, y cómo cada una puede verse afectada por problemas de latencia.
Al final del artículo, echamos un vistazo a los balanceadores de carga modernos y analizamos cómo pueden ayudarlo a abordar algunos tipos de problemas de latencia.
En un artículo anterior, mi colega Krzysztof Książek escribió sobre "Tratar con redes poco confiables al crear una solución HA para MySQL o MariaDB". Encontrará sugerencias que pueden ayudarlo a diseñar su arquitectura HA lista para la producción y evitar algunos de los problemas que se describen aquí.
Replicación maestro-esclavo para alta disponibilidad.
La replicación maestro-esclavo de MySQL es probablemente el tipo de clúster de base de datos más popular del planeta. Una de las cosas principales que desea monitorear mientras ejecuta su clúster de replicación maestro-esclavo es el retraso del esclavo. Según los requisitos de su aplicación y la forma en que utiliza su base de datos, la latencia de replicación (retraso del esclavo) puede determinar si los datos se pueden leer desde el nodo esclavo o no. Los datos confirmados en el maestro pero aún no disponibles en un esclavo asíncrono significan que el esclavo tiene un estado más antiguo. Cuando no está bien leer de un esclavo, debe ir al maestro y eso puede afectar el rendimiento de la aplicación. En el peor de los casos, su sistema no podrá manejar toda la carga de trabajo en un maestro.
Retraso esclavo y datos obsoletos
Para verificar el estado de la replicación maestro-esclavo, debe comenzar con el siguiente comando:
SHOW SLAVE STATUS\G
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.3.100
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000021
Read_Master_Log_Pos: 5101
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 809
Relay_Master_Log_File: binlog.000021
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 5101
Relay_Log_Space: 1101
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3-1179
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
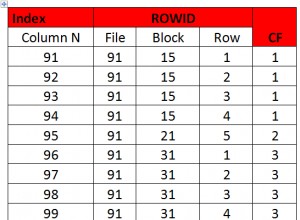
1 row in set (0.01 sec)Con la información anterior, puede determinar qué tan buena es la latencia de replicación general. Cuanto menor sea el valor que vea en "Seconds_Behind_Master", mejor será la velocidad de transferencia de datos para la replicación.
 Otra forma de monitorear el retraso del esclavo es usar el monitoreo de replicación de ClusterControl. En esta captura de pantalla podemos ver el estado de replicación del clúster maestro-esclavo (2x) asíncrono con ProxySQL.
Otra forma de monitorear el retraso del esclavo es usar el monitoreo de replicación de ClusterControl. En esta captura de pantalla podemos ver el estado de replicación del clúster maestro-esclavo (2x) asíncrono con ProxySQL. Hay una serie de cosas que pueden afectar el tiempo de replicación. El más obvio es el rendimiento de la red y la cantidad de datos que puede transferir. MySQL viene con múltiples opciones de configuración para optimizar el proceso de replicación. Los parámetros esenciales relacionados con la replicación son:
- Aplicación paralela
- Algoritmo de reloj lógico
- Compresión
- Replicación selectiva maestro-esclavo
- Modo de replicación
Aplicación paralela
No es raro comenzar a ajustar la replicación con la habilitación de la aplicación de procesos paralelos. El motivo es que, de forma predeterminada, MySQL se aplica con el registro binario secuencial y un servidor de base de datos típico viene con varias CPU para usar.
Para sortear la aplicación de registro secuencial, tanto MariaDB como MySQL ofrecen replicación paralela. La implementación puede diferir según el proveedor y la versión. P.ej. MySQL 5.6 ofrece replicación paralela siempre que un esquema separe las consultas, mientras que MariaDB (a partir de la versión 10.0) y MySQL 5.7 pueden manejar la replicación paralela entre esquemas. Los diferentes proveedores y versiones vienen con sus limitaciones y funciones, así que siempre consulte la documentación.
La ejecución de consultas a través de subprocesos esclavos paralelos puede acelerar su flujo de replicación si escribe mucho. Sin embargo, si no es así, lo mejor sería ceñirse a la replicación tradicional de un solo subproceso. Para habilitar el procesamiento paralelo, cambie slave_parallel_workers a la cantidad de subprocesos de CPU que desea involucrar en el proceso. Se recomienda mantener el valor por debajo del número de subprocesos de CPU disponibles.
La replicación en paralelo funciona mejor con las confirmaciones de grupo. Para verificar si tiene compromisos grupales, ejecute la siguiente consulta.
show global status like 'binlog_%commits';Cuanto mayor sea la relación entre estos dos valores, mejor.
Reloj lógico
Slave_parallel_type=LOGICAL_CLOCK es una implementación de un algoritmo de reloj de Lamport. Cuando se utiliza un esclavo multiproceso, esta variable especifica el método utilizado para decidir qué transacciones se pueden ejecutar en paralelo en el esclavo. La variable no tiene efecto en los esclavos para los que no está habilitado el subproceso múltiple, así que asegúrese de que slave_parallel_workers esté establecido en un valor superior a 0.
Los usuarios de MariaDB también deben verificar el modo optimista introducido en la versión 10.1.3, ya que también puede brindarle mejores resultados.
GTID
MariaDB viene con su propia implementación de GTID. La secuencia de MariaDB consta de un dominio, un servidor y una transacción. Los dominios permiten la replicación de múltiples fuentes con una identificación distinta. Se pueden usar diferentes ID de dominio para replicar la porción de datos fuera de orden (en paralelo). Mientras esté bien para su aplicación, esto puede reducir la latencia de replicación.
La técnica similar se aplica a MySQL 5.7, que también puede usar el maestro multifuente y los canales de replicación independientes.
Compresión
La potencia de la CPU es cada vez menos costosa con el tiempo, por lo que usarla para la compresión binlog podría ser una buena opción para muchos entornos de bases de datos. El parámetro slave_compressed_protocol le dice a MySQL que use compresión si tanto el maestro como el esclavo lo admiten. De forma predeterminada, este parámetro está deshabilitado.
A partir de MariaDB 10.2.3, los eventos seleccionados en el registro binario se pueden comprimir opcionalmente para guardar las transferencias de red.
Formatos de replicación
MySQL ofrece varios modos de replicación. Elegir el formato de replicación correcto ayuda a minimizar el tiempo para pasar datos entre los nodos del clúster.
Replicación multimaestro para alta disponibilidad
Algunas aplicaciones no pueden permitirse operar con datos desactualizados.
En tales casos, es posible que desee imponer la coherencia entre los nodos con la replicación síncrona. Mantener los datos sincronizados requiere un complemento adicional y, para algunos, la mejor solución en el mercado para eso es Galera Cluster.
El clúster de Galera viene con la API wsrep, que es responsable de transmitir transacciones a todos los nodos y ejecutarlas de acuerdo con un orden en todo el clúster. Esto bloqueará la ejecución de consultas posteriores hasta que el nodo haya aplicado todos los conjuntos de escritura de su cola de aplicación. Si bien es una buena solución para la coherencia, es posible que encuentre algunas limitaciones arquitectónicas. Los problemas comunes de latencia pueden estar relacionados con:
- El nodo más lento del clúster
- Escala horizontal y operaciones de escritura
- Clústeres geolocalizados
- Ping alto
- Tamaño de la transacción
El nodo más lento del clúster
Por diseño, el rendimiento de escritura del clúster no puede ser superior al rendimiento del nodo más lento del clúster. Inicie la revisión de su clúster comprobando los recursos de la máquina y verifique los archivos de configuración para asegurarse de que todos se ejecutan con la misma configuración de rendimiento.
Paralelización
Los subprocesos paralelos no garantizan un mejor rendimiento, pero pueden acelerar la sincronización de nuevos nodos con el clúster. El estado wsrep_cert_deps_distance nos dice el posible grado de paralelización. Es el valor de la distancia promedio entre los valores de seqno más alto y más bajo que posiblemente se pueden aplicar en paralelo. Puede utilizar la variable de estado wsrep_cert_deps_distance para determinar el número máximo de subprocesos esclavos posibles.
Escala horizontal
Al agregar más nodos en el clúster, tenemos menos puntos que podrían fallar; sin embargo, la información debe pasar por instancias múltiples hasta que se confirme, lo que multiplica los tiempos de respuesta. Si necesita escrituras escalables, considere una arquitectura basada en fragmentación. Una buena solución puede ser un motor de almacenamiento Spider.
En algunos casos, para reducir la información compartida entre los nodos del clúster, puede considerar tener un escritor a la vez. Es relativamente fácil de implementar mientras se usa un balanceador de carga. Cuando haga esto manualmente, asegúrese de tener un procedimiento para cambiar el valor de DNS cuando su nodo de escritura se caiga.
Clústeres geolocalizados
Aunque Galera Cluster es síncrono, es posible implementar un Galera Cluster en los centros de datos. La replicación síncrona como MySQL Cluster (NDB) implementa una confirmación de dos fases, donde los mensajes se envían a todos los nodos en un clúster en una fase de 'preparación' y otro conjunto de mensajes se envían en una fase de 'confirmación'. Este enfoque generalmente no es adecuado para nodos geográficamente dispares debido a las latencias en el envío de mensajes entre nodos.
Ping alto
Galera Cluster con la configuración predeterminada no maneja bien la alta latencia de la red. Si tiene una red con un nodo que muestra un tiempo de ping alto, considere cambiar los parámetros evs.send_window y evs.user_send_window. Estas variables definen el número máximo de paquetes de datos en replicación a la vez. Para las configuraciones de WAN, la variable se puede establecer en un valor considerablemente más alto que el valor predeterminado de 2. Es común establecerlo en 512. Estos parámetros son parte de wsrep_provider_options.
--wsrep_provider_options="evs.send_window=512;evs.user_send_window=512"Tamaño de la transacción
Una de las cosas que debe tener en cuenta al ejecutar Galera Cluster es el tamaño de la transacción. Encontrar el equilibrio entre el tamaño de la transacción, el rendimiento y el proceso de certificación de Galera es algo que debe estimar en su solicitud. Puede encontrar más información al respecto en el artículo Cómo mejorar el rendimiento de Galera Cluster para MySQL o MariaDB de Ashraf Sharif.
Lecturas de coherencia causal del equilibrador de carga
Incluso con el riesgo mínimo de problemas de latencia de datos, la replicación asíncrona de MySQL estándar no puede garantizar la coherencia. Todavía es posible que los datos aún no se repliquen en el esclavo mientras su aplicación los lee desde allí. La replicación síncrona puede resolver este problema, pero tiene limitaciones de arquitectura y es posible que no se ajuste a los requisitos de su aplicación (por ejemplo, escrituras masivas intensivas). Entonces, ¿cómo superarlo?
El primer paso para evitar la lectura de datos obsoletos es hacer que la aplicación sea consciente del retraso en la replicación. Por lo general, se programa en el código de la aplicación. Afortunadamente, existen balanceadores de carga de bases de datos modernos que admiten el enrutamiento de consultas adaptable basado en el seguimiento de GTID. Los más populares son ProxySQL y Maxscale.
ProxySQL 2.0
ProxySQL Binlog Reader permite que ProxySQL sepa en tiempo real qué GTID se ha ejecutado en cada servidor MySQL, esclavos y maestro. Gracias a esto, cuando un cliente ejecuta una lectura que necesita proporcionar lecturas de coherencia causal, ProxySQL sabe de inmediato en qué servidor se puede ejecutar la consulta. Si por alguna razón las escrituras aún no se ejecutaron en ningún esclavo, ProxySQL sabrá que el escritor se ejecutó en el maestro y enviará la lectura allí.
Escala máxima 2.3
MariaDB introdujo lecturas casuales en Maxscale 2.3.0. La forma en que funciona es similar a ProxySQL 2.0. Básicamente, cuando las lecturas causales están habilitadas, cualquier lectura posterior realizada en servidores esclavos se realizará de una manera que evite que el retraso de la replicación afecte los resultados. Si el esclavo no se ha puesto al día con el maestro dentro del tiempo configurado, la consulta se volverá a intentar en el maestro.