La replicación maestro-esclavo de MySQL es bastante fácil y sencilla de configurar. Esta es la razón principal por la que las personas eligen esta tecnología como primer paso para lograr una mejor disponibilidad de la base de datos. Sin embargo, tiene el precio de la complejidad en la gestión y el mantenimiento; depende del administrador mantener la integridad de los datos, especialmente durante la conmutación por error, la conmutación por recuperación, el mantenimiento, la actualización, etc.
Hay muchos artículos que describen cómo realizar una operación de conmutación por error para la configuración de la replicación. También hemos tratado este tema en esta publicación de blog, Introducción a la conmutación por error para la replicación de MySQL:el blog 101. En esta publicación de blog, cubriremos las tareas posteriores al desastre al restaurar a la topología original:realizar la operación de conmutación por recuperación.
¿Por qué necesitamos recuperación?
El líder de replicación (maestro) es el nodo más crítico en una configuración de replicación. Requiere buenas especificaciones de hardware para garantizar que pueda procesar escrituras, generar eventos de replicación, procesar lecturas críticas, etc. de manera estable. Cuando se requiere conmutación por error durante la recuperación ante desastres o el mantenimiento, puede que no sea raro encontrarnos promoviendo a un nuevo líder con un hardware inferior. Esta situación puede estar bien temporalmente, sin embargo, a largo plazo, el maestro designado debe volver a liderar la replicación después de que se considere que está en buen estado.
A diferencia de la conmutación por error, la operación de conmutación por recuperación generalmente ocurre en un entorno controlado a través de la conmutación, rara vez ocurre en modo pánico. Esto le da al equipo de operaciones algo de tiempo para planificar cuidadosamente y ensayar el ejercicio para una transición sin problemas. El objetivo principal es simplemente devolver el maestro antiguo al estado más reciente y restaurar la configuración de replicación a su topología original. Sin embargo, hay algunos casos en los que la conmutación por recuperación es crítica, por ejemplo, cuando el maestro recién promovido no funcionó como se esperaba y afectó el servicio de base de datos en general.
¿Cómo realizar la conmutación por recuperación de forma segura?
Después de que ocurriera la conmutación por error, el antiguo maestro quedaría fuera de la cadena de replicación para mantenimiento o recuperación. Para realizar la conmutación, se debe hacer lo siguiente:
- Proporcione el antiguo maestro al estado correcto, convirtiéndolo en el esclavo más actualizado.
- Detenga la aplicación.
- Verifique que todos los esclavos estén al día.
- Asciende al antiguo maestro como nuevo líder.
- Vuelva a señalar todos los esclavos al nuevo maestro.
- Inicie la aplicación escribiendo al nuevo maestro.
Considere la siguiente configuración de replicación:
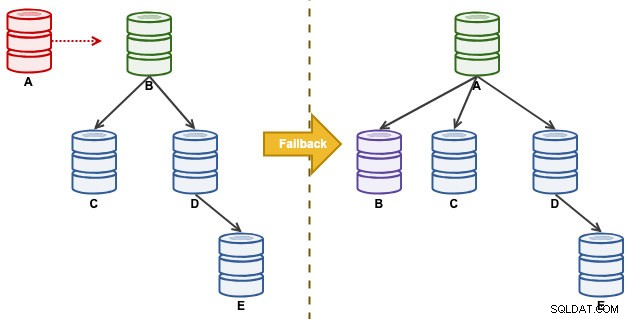
"A" era un maestro hasta que un evento de disco lleno causó estragos en la cadena de replicación. Después de un evento de conmutación por error, nuestra topología de replicación fue dirigida por B y se replica en C hasta E. El ejercicio de conmutación por recuperación recuperará a A como líder y restaurará la topología original antes del desastre. Tenga en cuenta que todos los nodos se ejecutan en MySQL 8.0.15 con GTID habilitado. Diferentes versiones principales pueden usar diferentes comandos y pasos.
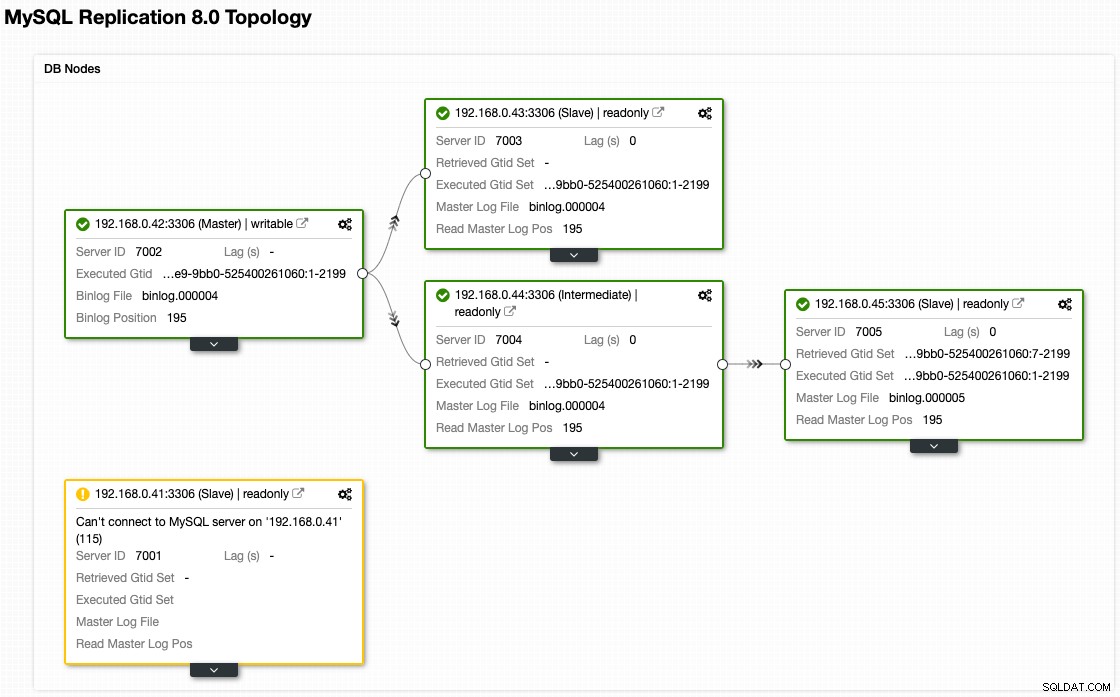
Si bien así es como se ve nuestra arquitectura ahora después de la conmutación por error (tomada de la vista Topología de ClusterControl):
Aprovisionamiento de nodos
Antes de que A pueda ser un maestro, debe actualizarse con el estado actual de la base de datos. La mejor manera de hacer esto es convertir a A en esclavo del maestro activo, B. Dado que todos los nodos están configurados con log_slave_updates=ON (significa que un esclavo también produce registros binarios), en realidad podemos elegir otros esclavos como C y D como la fuente de la verdad para la sincronización inicial. Sin embargo, cuanto más cerca del maestro activo, mejor. Tenga en cuenta la carga adicional que podría causar al realizar la copia de seguridad. Esta parte aprovecha al máximo las horas de conmutación por recuperación. Según el estado del nodo y el tamaño del conjunto de datos, la sincronización del maestro antiguo puede llevar algún tiempo (pueden ser horas y días).
Una vez que se resuelve el problema en "A" y está listo para unirse a la cadena de replicación, el mejor primer paso es intentar replicar desde "B" (192.168.0.42) con la instrucción CHANGE MASTER:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Si la replicación funciona, debería ver lo siguiente en el estado de la replicación:
Slave_IO_Running: Yes
Slave_SQL_Running: YesSi la replicación falla, mire Last_IO_Error o Last_SQL_Error de la salida de estado del esclavo. Por ejemplo, si ve el siguiente error:
Last_IO_Error: error connecting to master '[email protected]:3306' - retry-time: 60 retries: 2Luego, tenemos que crear el usuario de replicación en el maestro activo actual, B:
mysql> CREATE USER [email protected] IDENTIFIED BY 'p4ss';
mysql> GRANT REPLICATION SLAVE ON *.* TO [email protected];Luego, reinicie el esclavo en A para comenzar a replicar nuevamente:
mysql> STOP SLAVE;
mysql> START SLAVE;Otro error común que vería es esta línea:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ...Eso probablemente significa que el esclavo tiene problemas para leer el archivo de registro binario del maestro actual. En algunas ocasiones, el esclavo puede estar muy atrasado, por lo que los eventos binarios necesarios para iniciar la replicación no se encuentran en el maestro actual, o el binario en el maestro se ha purgado durante la conmutación por error, etc. En este caso, la mejor manera es realizar una sincronización completa al realizar una copia de seguridad completa en B y restaurarla en A. En B, puede usar mysqldump o Percona Xtrabackup para realizar una copia de seguridad completa:
$ mysqldump -uroot -p --all-databases --single-transaction --triggers --routines > dump.sql # for mysqldump
$ xtrabackup --defaults-file=/etc/my.cnf --backup --parallel 1 --stream=xbstream --no-timestamp | gzip -6 - > backup-full-2019-04-16_071649.xbstream.gz # for xtrabackupTransfiera el archivo de copia de seguridad a A, reinicie la instalación de MySQL existente para una limpieza adecuada y realice la restauración de la base de datos:
$ systemctl stop mysqld # if mysql is still running
$ rm -Rf /var/lib/mysql # wipe out old data
$ mysqld --initialize --user=mysql # initialize database
$ systemctl start mysqld # start mysql
$ grep -i 'temporary password' /var/log/mysql/mysqld.log # retrieve the temporary root password
$ mysql -uroot -p -e 'ALTER USER [email protected] IDENTIFIED BY "p455word"' # mandatory root password update
$ mysql -uroot -p < dump.sql # restore the backup using the new root passwordUna vez restaurado, configure el enlace de replicación al maestro B activo (192.168.0.42) y habilite solo lectura. En A, ejecute las siguientes instrucciones:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Para Percona Xtrabackup, consulte la página de documentación sobre cómo restaurar a A. Se trata de un paso de requisito previo para preparar la copia de seguridad primero antes de reemplazar el directorio de datos de MySQL.
Una vez que A haya comenzado a replicar correctamente, monitoree Seconds_Behind_Master en el estado de esclavo. Esto le dará una idea de qué tan lejos se ha quedado atrás el esclavo y cuánto tiempo debe esperar antes de que lo alcance. En este punto, nuestra arquitectura se ve así:
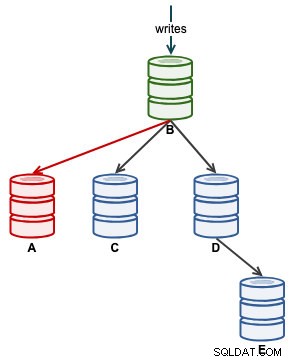
Una vez que Seconds_Behind_Master vuelve a 0, ese es el momento en que A se ha puesto al día como un esclavo actualizado.
Si usa ClusterControl, tiene la opción de resincronizar el nodo restaurando desde una copia de seguridad existente o crear y transmitir la copia de seguridad directamente desde el nodo principal activo:
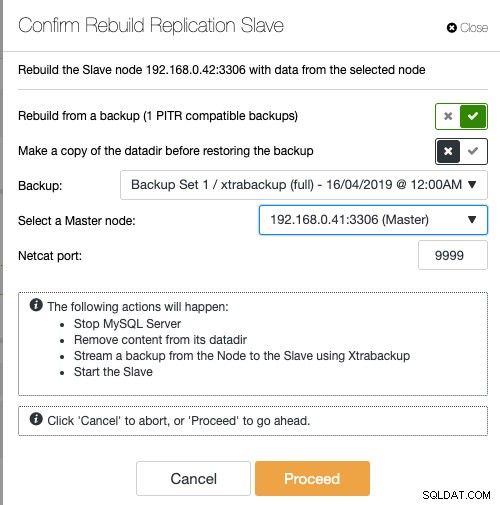
Preparar el esclavo con una copia de seguridad existente es la forma recomendada de hacerlo para construir el esclavo, ya que no tiene ningún impacto en el servidor maestro activo al preparar el nodo.
Promocionar al Viejo Maestro
Antes de promover a A como el nuevo maestro, la forma más segura es detener todas las operaciones de escritura en B. Si esto no es posible, simplemente obligue a B a operar en modo de solo lectura:
mysql> SET GLOBAL read_only = 'ON';
mysql> SET GLOBAL super_read_only = 'ON';Luego, en A, ejecute SHOW SLAVE STATUS y verifique el siguiente estado de replicación:
Read_Master_Log_Pos: 45889974
Exec_Master_Log_Pos: 45889974
Seconds_Behind_Master: 0
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updatesEl valor de Read_Master_Log_Pos y Exec_Master_Log_Pos debe ser idéntico, mientras que Seconds_Behind_Master es 0 y el estado debe ser 'Slave has read all relay log'. Asegúrese de que todos los esclavos hayan procesado las declaraciones en su registro de retransmisión; de lo contrario, correrá el riesgo de que las nuevas consultas afecten las transacciones del registro de retransmisión, provocando todo tipo de problemas (por ejemplo, una aplicación puede eliminar algunas filas a las que acceden las transacciones). del registro de retransmisión).
En A, detenga la replicación y use la declaración RESET SLAVE ALL para eliminar toda la configuración relacionada con la replicación y deshabilitar solo lectura:
mysql> STOP SLAVE;
mysql> RESET SLAVE ALL;
mysql> SET GLOBAL read_only = 'OFF';
mysql> SET GLOBAL super_read_only = 'OFF';En este punto, A está listo para aceptar escrituras (read_only=OFF), sin embargo, los esclavos no están conectados a él, como se ilustra a continuación:
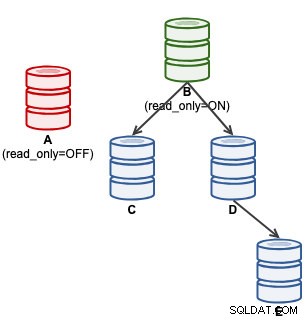
Para los usuarios de ClusterControl, la promoción de A se puede realizar mediante la función "Promocionar esclavo" en Acciones de nodo. ClusterControl degradará automáticamente al maestro activo B, promoverá al esclavo A como maestro y reorientará a C y D para replicar desde A. B se dejará de lado y el usuario tendrá que elegir explícitamente "Cambiar maestro de replicación" para volver a unirse a B replicando desde A en una etapa posterior .
Reubicación de esclavos
Ahora es seguro cambiar el maestro en los esclavos relacionados para replicar desde A (192.168.0.41). En todos los esclavos excepto E, configure lo siguiente:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.41', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Si es usuario de ClusterControl, puede omitir este paso, ya que la reorientación se realiza automáticamente cuando decidió promocionar A anteriormente.
Luego podemos iniciar nuestra aplicación para escribir en A. En este punto, nuestra arquitectura se ve así:
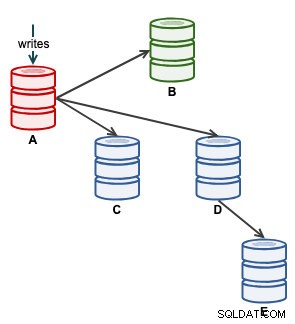
Desde la vista de topología de ClusterControl, hemos restaurado nuestro clúster de replicación a su arquitectura original, que se ve así:
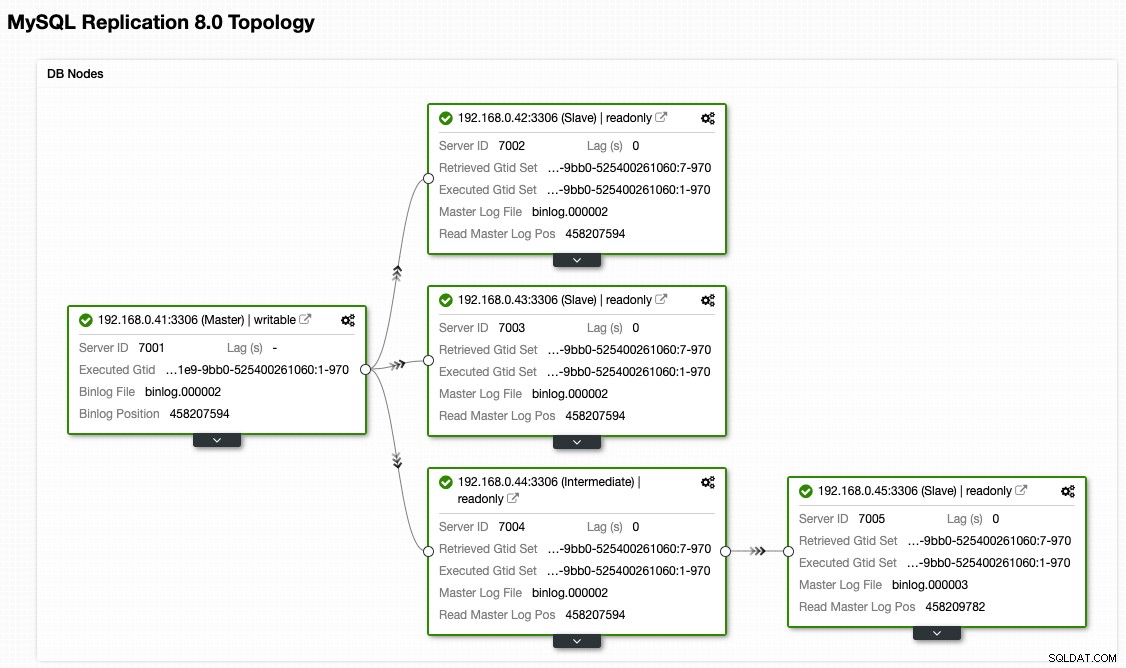
Tenga en cuenta que el ejercicio de conmutación por recuperación es mucho menos riesgoso en comparación con la conmutación por error. Es importante programar este ejercicio fuera de las horas pico para minimizar el impacto en su negocio.
Reflexiones finales
La operación de conmutación por error y conmutación por recuperación debe realizarse con cuidado. La operación es bastante simple si tiene una pequeña cantidad de nodos, pero para varios nodos con una cadena de replicación compleja, podría ser un ejercicio arriesgado y propenso a errores. También mostramos cómo se puede usar ClusterControl para simplificar operaciones complejas al realizarlas a través de la interfaz de usuario, además, la vista de topología se visualiza en tiempo real para que comprenda la topología de replicación que desea construir.