Las consultas deben almacenarse en caché en cada base de datos muy cargada, simplemente no hay forma de que una base de datos maneje todo el tráfico con un rendimiento razonable. Hay varios mecanismos en los que se puede implementar una caché de consultas. Comenzando desde el caché de consultas de MySQL, que solía funcionar bien para cargas de trabajo de baja simultaneidad en su mayoría de solo lectura y que no tiene cabida en cargas de trabajo de alta simultaneidad (en la medida en que Oracle lo eliminó en MySQL 8.0), hasta almacenes externos de clave-valor como Redis, memcached o CouchBase.
El principal problema con el uso de un almacén de datos dedicado externo (ya que no recomendaríamos usar el caché de consultas de MySQL a nadie) es que este es otro almacén de datos para administrar. Es otro entorno más para mantener, problemas de escala para manejar, errores para depurar, etc.
Entonces, ¿por qué no matar dos pájaros de un tiro aprovechando su proxy? La suposición aquí es que está utilizando un proxy en su entorno de producción, ya que ayuda a equilibrar la carga de consultas entre instancias y enmascara la topología de la base de datos subyacente al proporcionar un punto final simple para las aplicaciones. ProxySQL es una gran herramienta para el trabajo, ya que además puede funcionar como una capa de almacenamiento en caché. En esta publicación de blog, le mostraremos cómo almacenar consultas en caché en ProxySQL usando ClusterControl.
¿Cómo funciona la caché de consultas en ProxySQL?
En primer lugar, un poco de antecedentes. ProxySQL administra el tráfico a través de reglas de consulta y puede realizar el almacenamiento en caché de consultas utilizando el mismo mecanismo. ProxySQL almacena consultas en caché en una estructura de memoria. Los datos almacenados en caché se desalojan mediante la configuración de tiempo de vida (TTL). El TTL se puede definir para cada regla de consulta individualmente, por lo que depende del usuario decidir si se deben definir reglas de consulta para cada consulta individual, con un TTL distinto o si solo necesita crear un par de reglas que coincidan con la mayoría de las consultas. el tráfico.
Hay dos opciones de configuración que definen cómo se debe usar una caché de consultas. Primero, mysql-query_cache_size_MB que define un límite suave en el tamaño de la caché de consultas. No es un límite estricto, por lo que ProxySQL puede usar un poco más de memoria que eso, pero es suficiente para mantener la utilización de la memoria bajo control. La segunda configuración que puede modificar es mysql-query_cache_stores_empty_result . Define si un conjunto de resultados vacío se almacena en caché o no.
La memoria caché de consultas de ProxySQL está diseñada como un almacén de clave-valor. El valor es el conjunto de resultados de una consulta y la clave se compone de valores concatenados como:usuario, esquema y texto de consulta. Luego se crea un hash a partir de esa cadena y ese hash se usa como clave.
Configuración de ProxySQL como caché de consultas mediante ClusterControl
Como configuración inicial, tenemos un clúster de replicación de un maestro y un esclavo. También tenemos un único ProxySQL.
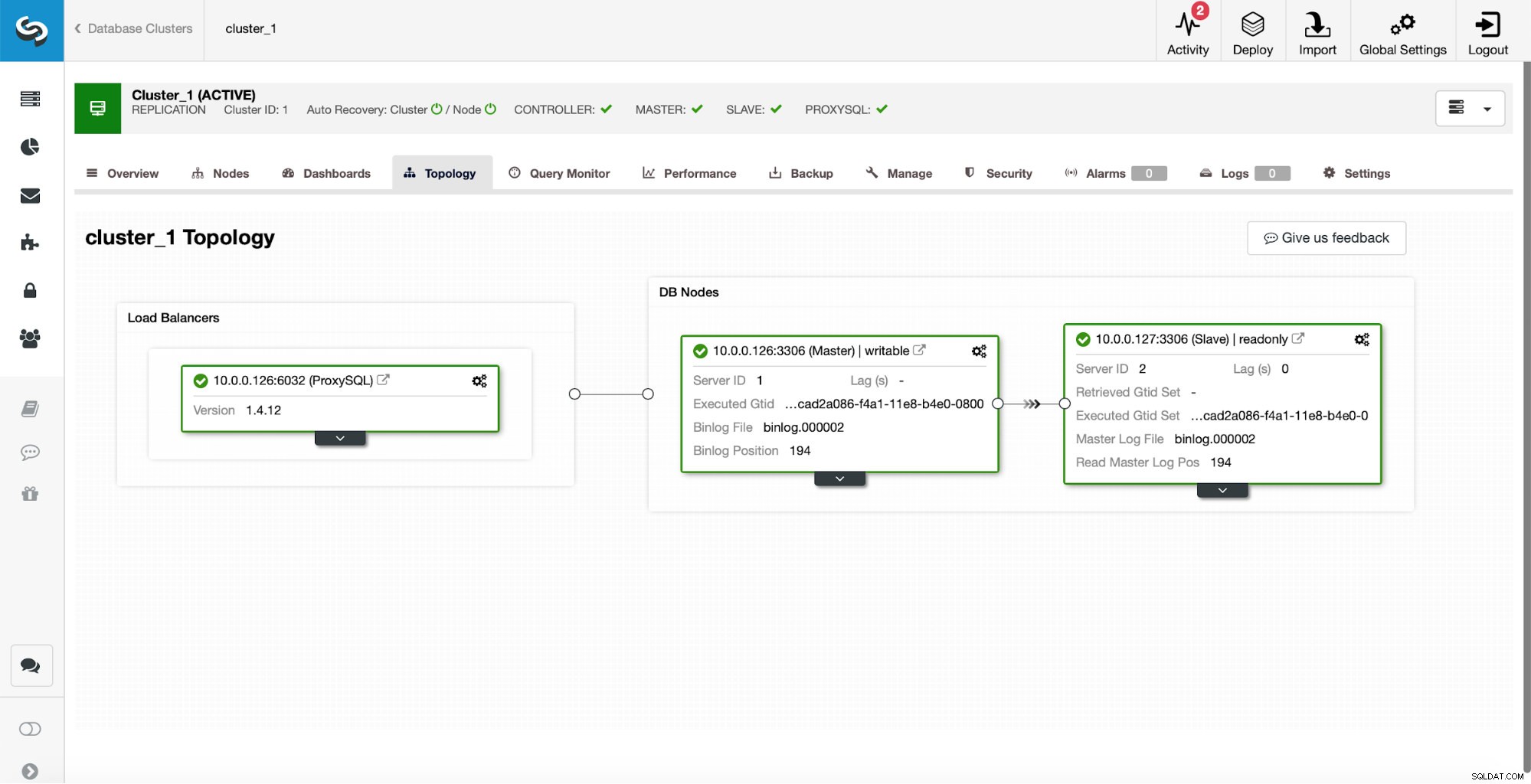
Esto no es de ninguna manera una configuración de nivel de producción, ya que tendríamos que implementar algún tipo de alta disponibilidad para la capa de proxy (por ejemplo, implementando más de una instancia de ProxySQL y luego manteniéndolos activos para IP virtual flotante), pero será más que suficiente para nuestras pruebas.
Primero, vamos a verificar la configuración de ProxySQL para asegurarnos de que la configuración de caché de consultas sea la que queremos que sea.
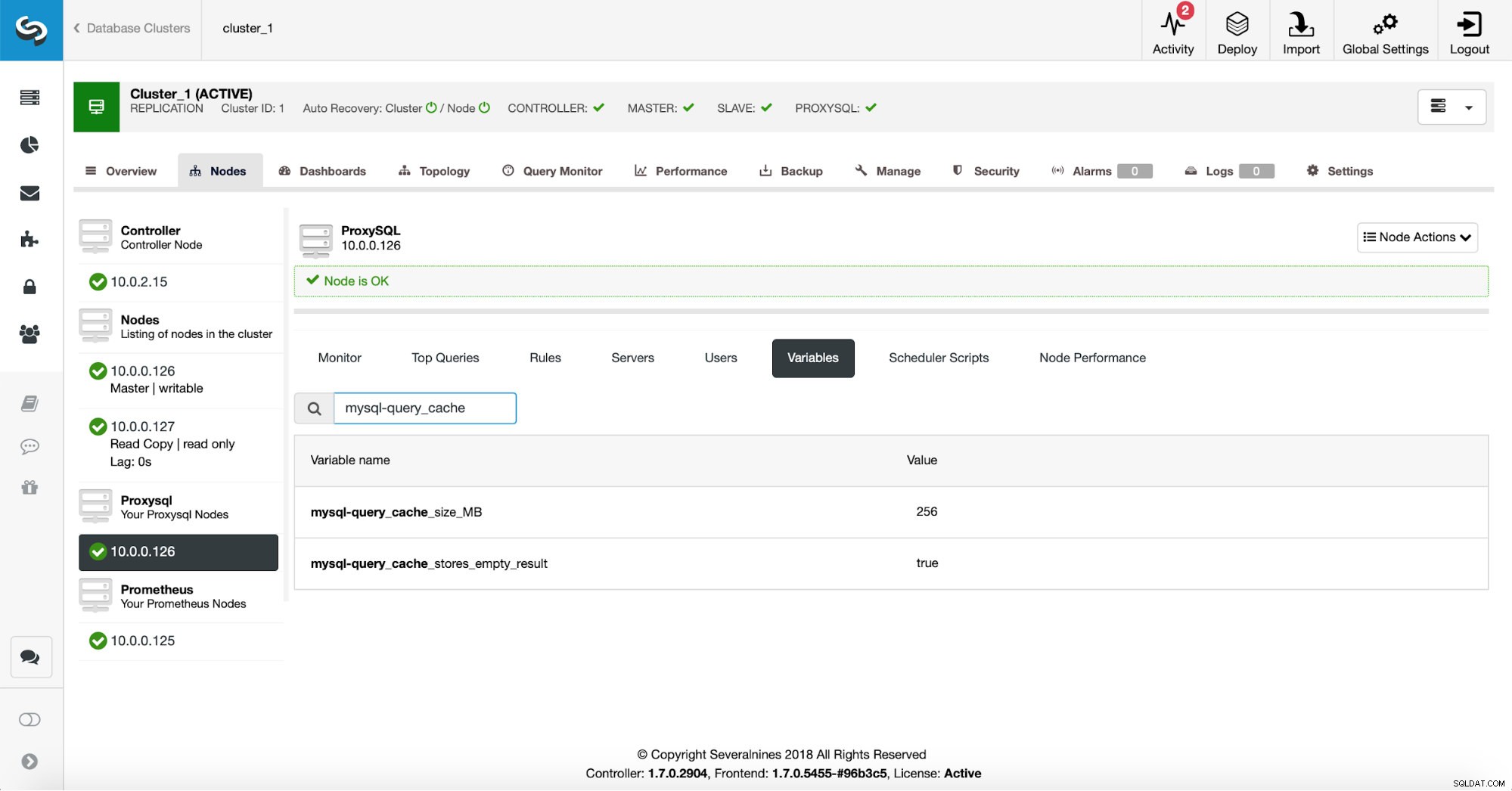
256 MB de caché de consultas deberían ser correctos y queremos almacenar en caché también los conjuntos de resultados vacíos; a veces, una consulta que no devuelve datos todavía tiene que hacer mucho trabajo para verificar que no hay nada que devolver.
El siguiente paso es crear reglas de consulta que coincidan con las consultas que desea almacenar en caché. Hay dos formas de hacerlo en ClusterControl.
Adición manual de reglas de consulta
La primera forma requiere un poco más de acciones manuales. Con ClusterControl puede crear fácilmente cualquier regla de consulta que desee, incluidas las reglas de consulta que realizan el almacenamiento en caché. Primero, echemos un vistazo a la lista de reglas:
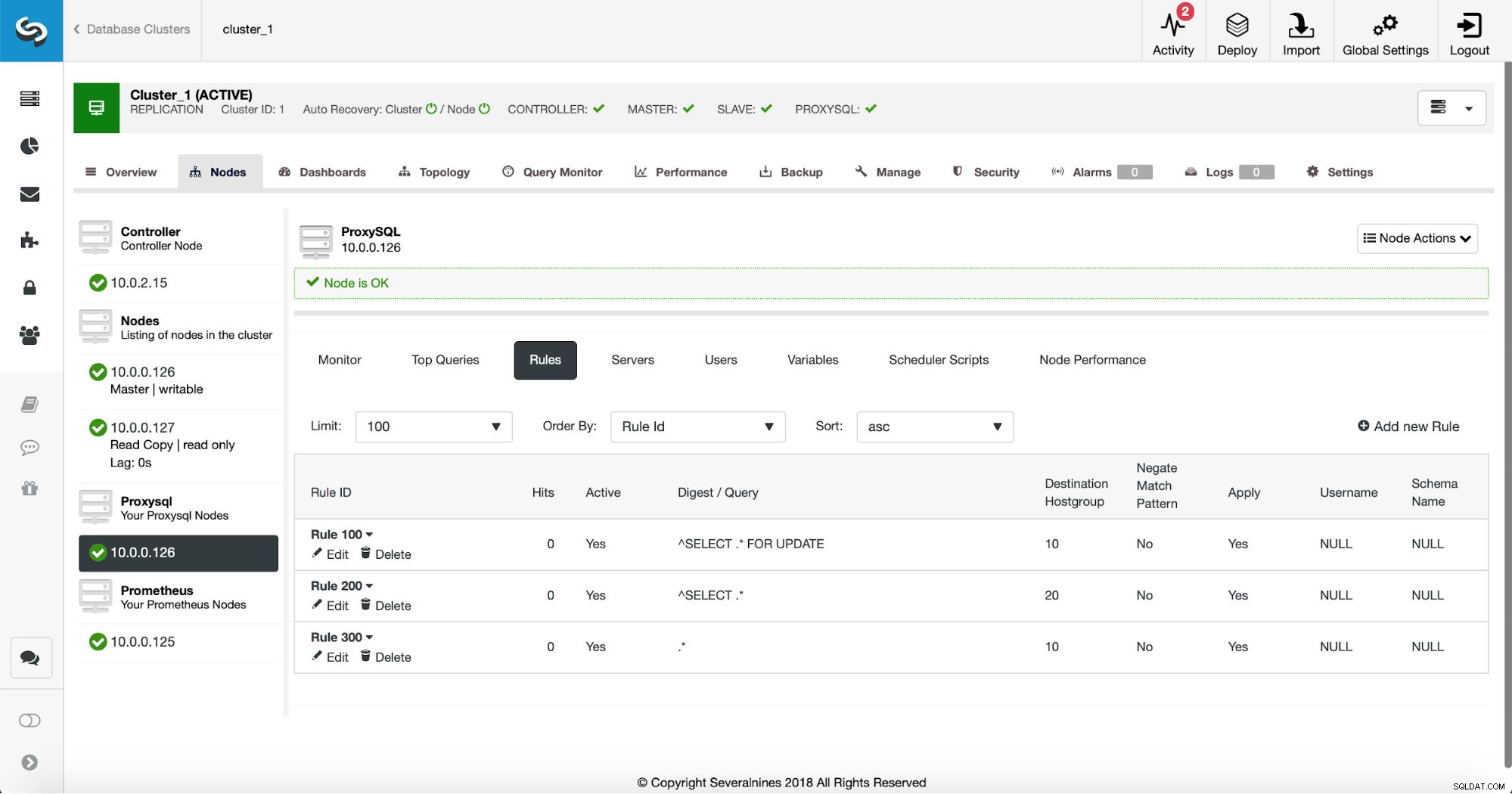
En este punto, tenemos un conjunto de reglas de consulta para realizar la división de lectura/escritura. La primera regla tiene un ID de 100. Nuestra nueva regla de consulta debe procesarse antes que esa, por lo que usaremos un ID de regla más bajo. Vamos a crear una regla de consulta que hará el almacenamiento en caché de consultas similares a esta:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY c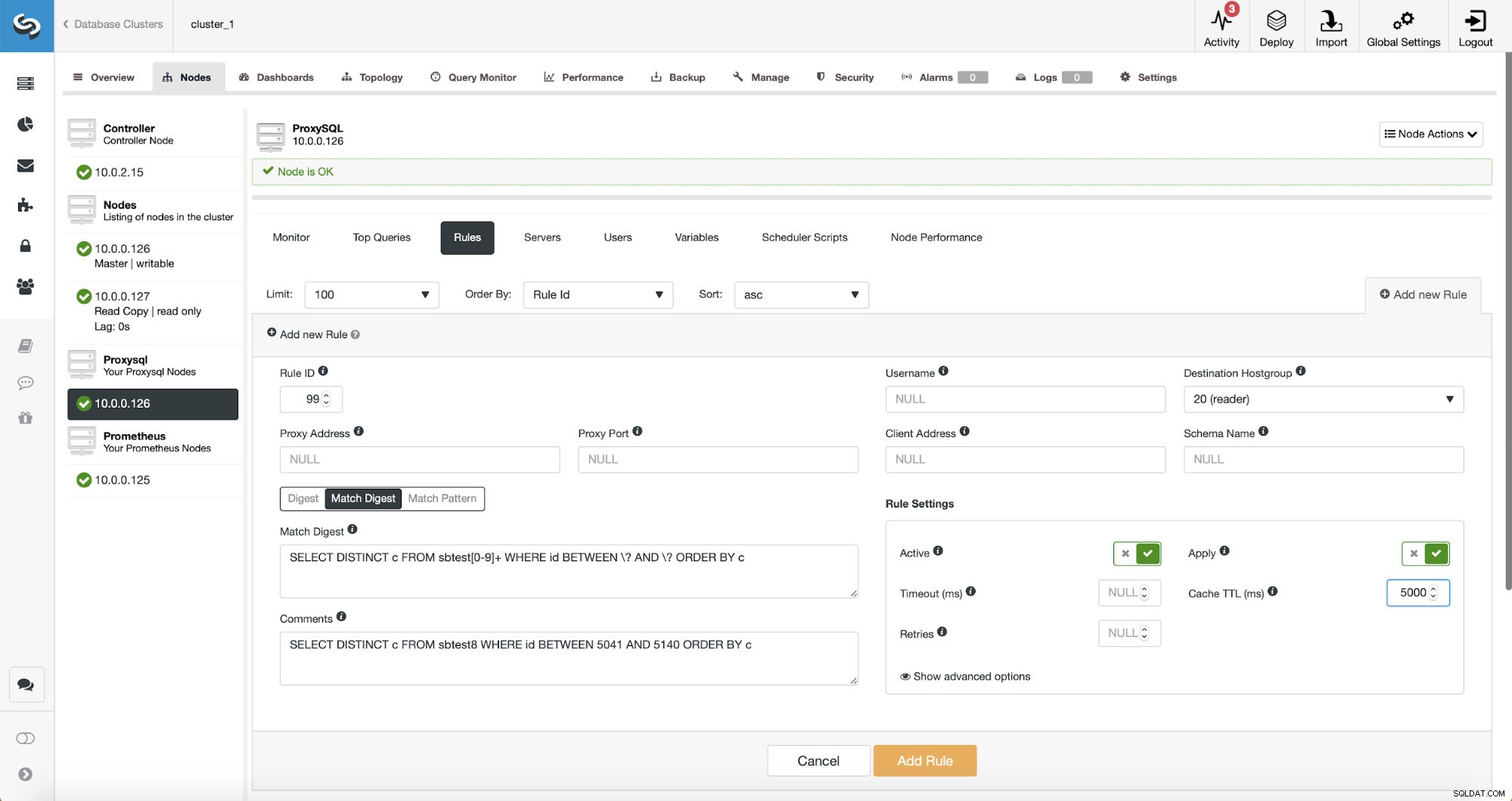
Hay tres formas de hacer coincidir la consulta:resumen, resumen de coincidencia y patrón de coincidencia. Hablemos un poco de ellos aquí. Primero, Match Digest. Podemos establecer aquí una expresión regular que coincidirá con una cadena de consulta generalizada que representa algún tipo de consulta. Por ejemplo, para nuestra consulta:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cLa representación genérica será:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN ? AND ? ORDER BY cComo puede ver, eliminó los argumentos de la cláusula WHERE, por lo que todas las consultas de este tipo se representan como una sola cadena. Esta opción es bastante agradable de usar porque coincide con todo el tipo de consulta y, lo que es aún más importante, se eliminan los espacios en blanco. Esto hace que sea mucho más fácil escribir una expresión regular, ya que no tiene que tener en cuenta los saltos de línea extraños, los espacios en blanco al principio o al final de la cadena, etc.
Digest es básicamente un hash que ProxySQL calcula sobre el formulario Match Digest.
Finalmente, Match Pattern coincide con el texto completo de la consulta, tal como lo envió el cliente. En nuestro caso, la consulta tendrá una forma de:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cVamos a utilizar Match Digest porque queremos que todas esas consultas estén cubiertas por la regla de consulta. Si quisiéramos almacenar en caché solo esa consulta en particular, una buena opción sería usar Match Pattern.
La expresión regular que usamos es:
SELECT DISTINCT c FROM sbtest[0-9]+ WHERE id BETWEEN \? AND \? ORDER BY cEstamos haciendo coincidir literalmente la cadena de consulta generalizada exacta con una excepción:sabemos que esta consulta afectó a varias tablas, por lo que agregamos una expresión regular para que coincida con todas ellas.
Una vez hecho esto, podemos ver si la regla de consulta está en vigor o no.
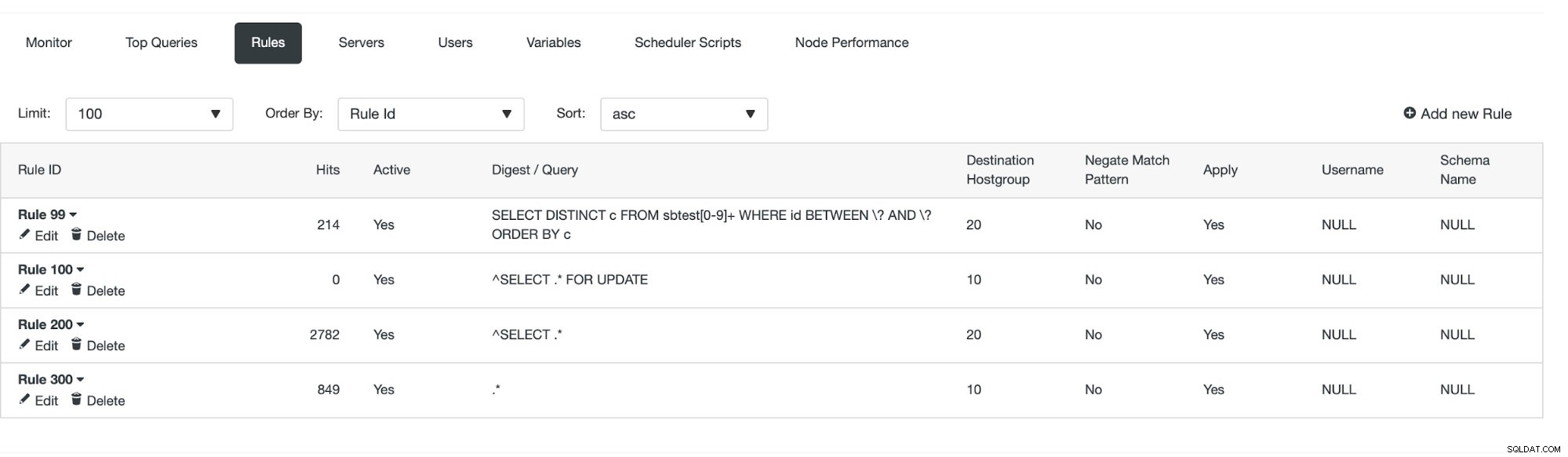
Podemos ver que los "Accesos" están aumentando, lo que significa que se está utilizando nuestra regla de consulta. A continuación, veremos otra forma de crear una regla de consulta.
Uso de ClusterControl para crear reglas de consulta
ProxySQL tiene una funcionalidad útil de recopilar estadísticas de las consultas que enrutó. Puede realizar un seguimiento de datos como el tiempo de ejecución, cuántas veces se ejecutó una consulta determinada, etc. Estos datos también están presentes en ClusterControl:
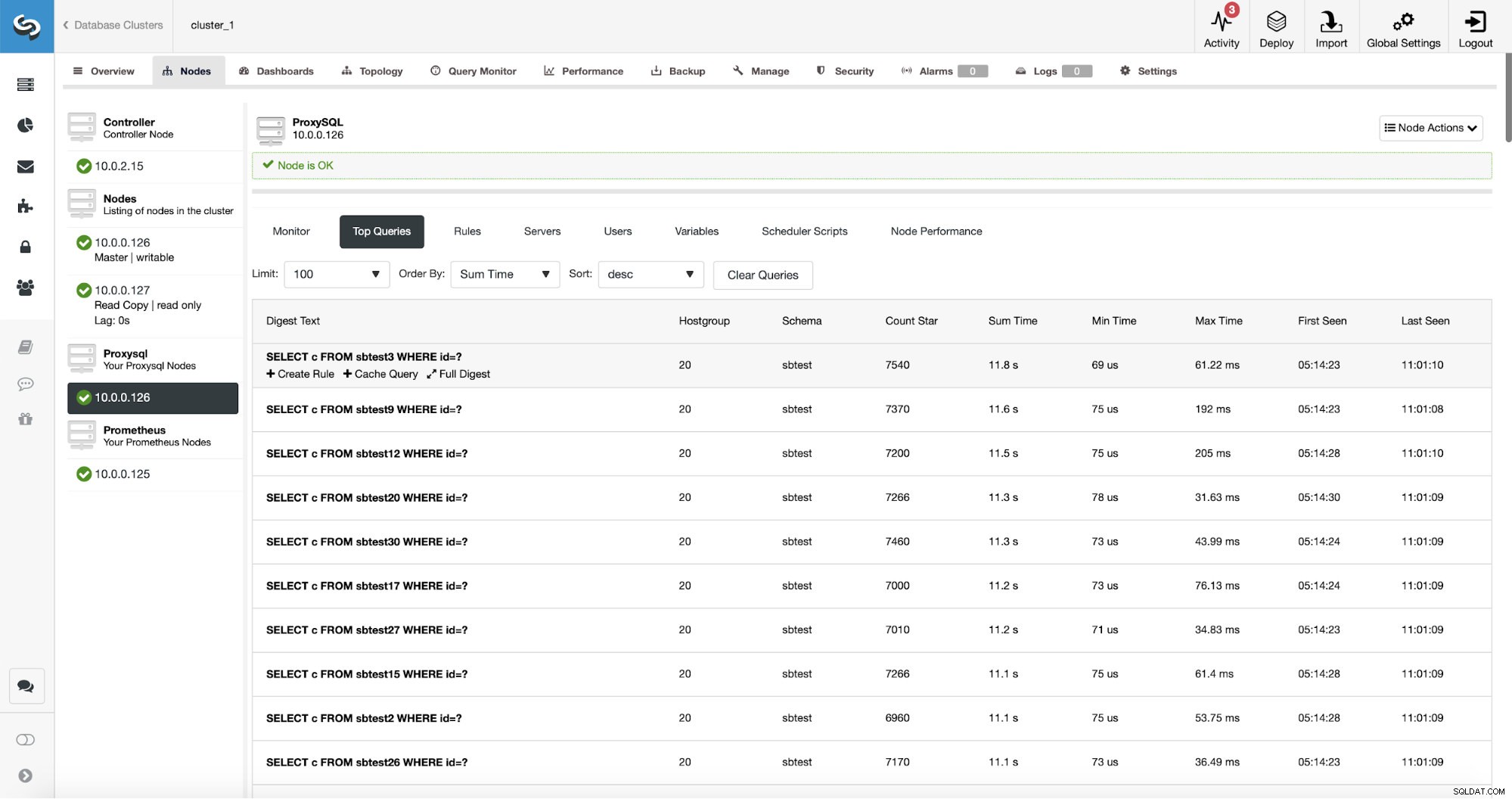
Lo que es aún mejor, si apunta a un tipo de consulta determinado, puede crear una regla de consulta relacionada con él. También puede almacenar fácilmente en caché este tipo de consulta en particular.
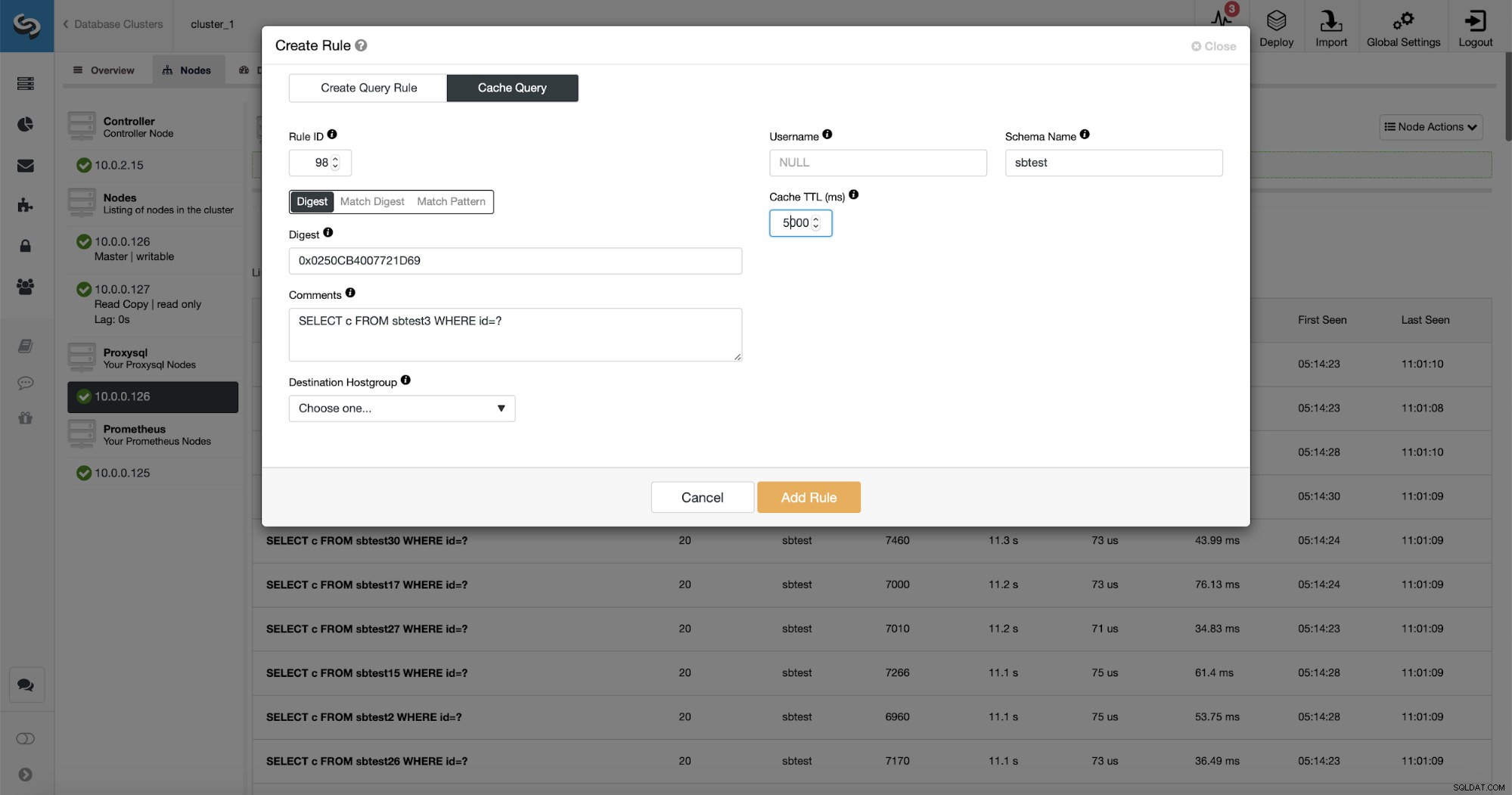
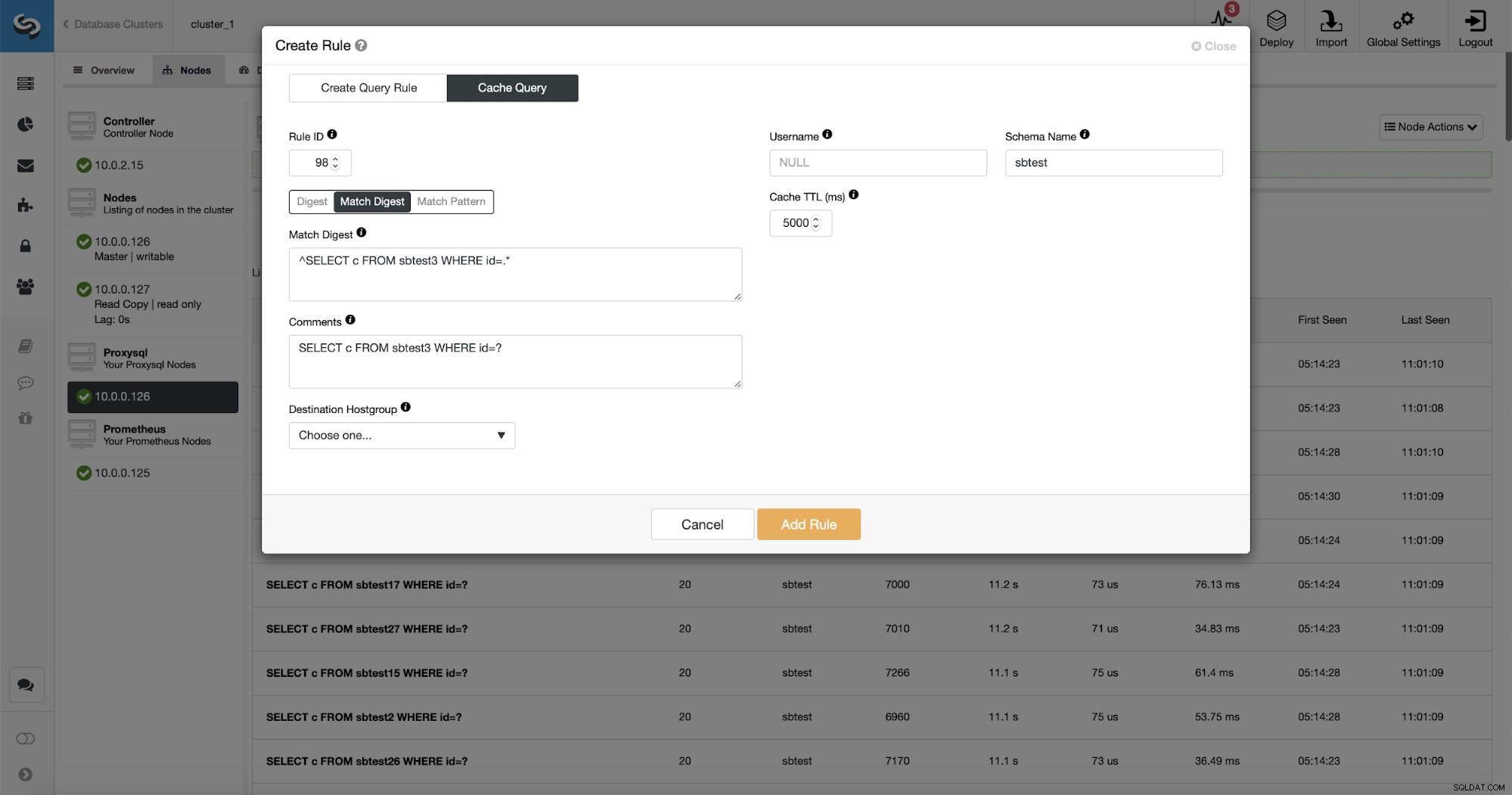
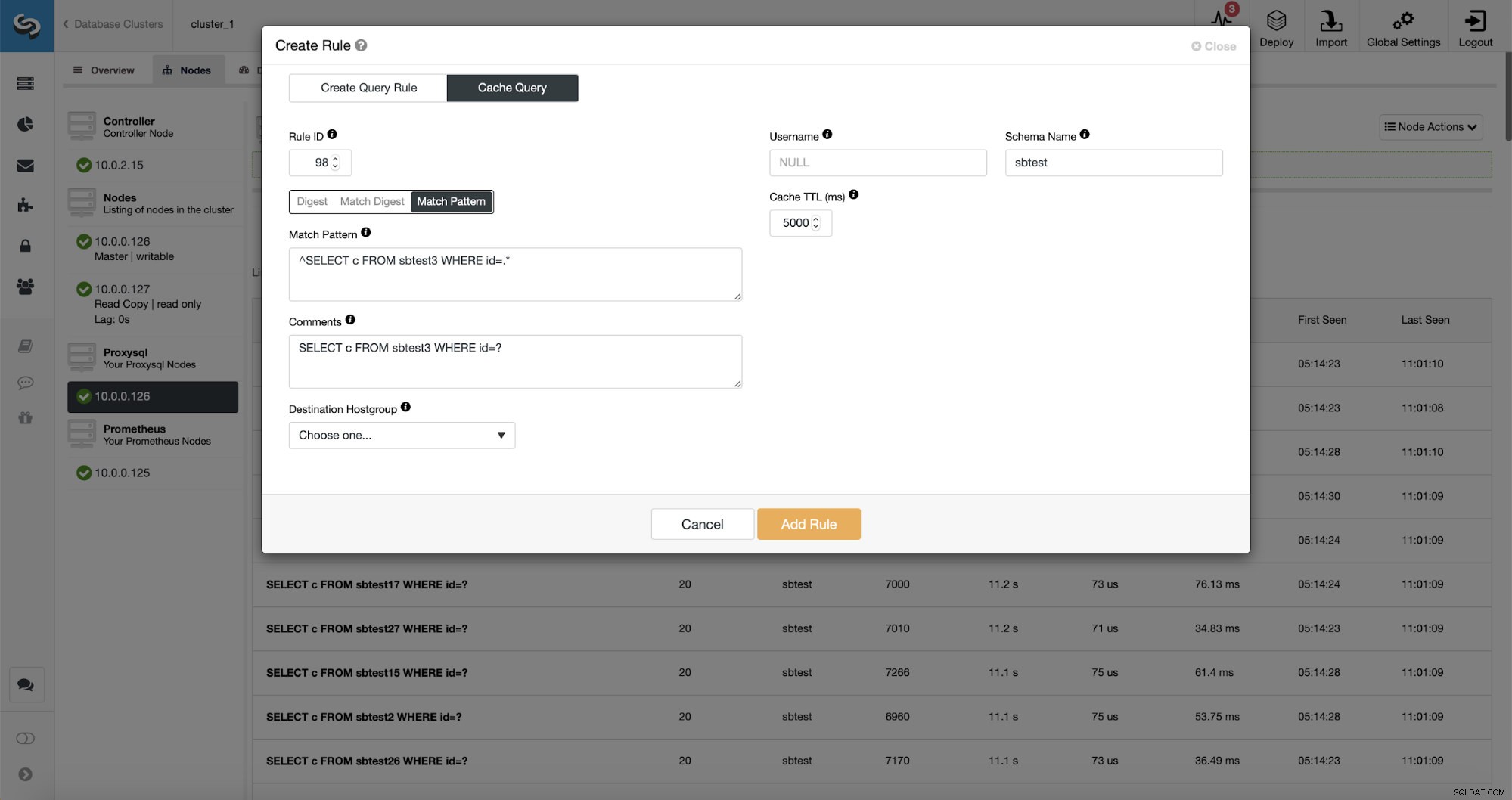
Como puede ver, algunos de los datos como Rule IP, Cache TTL o Schema Name ya están completos. ClusterControl también completará los datos según el mecanismo de coincidencia que haya decidido usar. Podemos usar fácilmente hash para un tipo de consulta determinado o podemos usar Match Digest o Match Pattern si deseamos ajustar la expresión regular (por ejemplo, haciendo lo mismo que hicimos antes y extendiendo la expresión regular para que coincida con todos los tablas en el esquema sbtest).
Esto es todo lo que necesita para crear fácilmente reglas de caché de consultas en ProxySQL. Descarga ClusterControl para probarlo hoy.