ProxySQL comúnmente se encuentra entre los niveles de la aplicación y la base de datos, en el llamado nivel de proxy inverso. Cuando Kubernetes organiza y administra los contenedores de su aplicación, es posible que desee utilizar ProxySQL delante de sus servidores de base de datos.
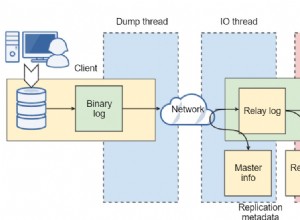
En esta publicación, le mostraremos cómo ejecutar ProxySQL en Kubernetes como un contenedor auxiliar en un pod. Vamos a utilizar Wordpress como aplicación de ejemplo. El servicio de datos lo proporciona nuestra replicación de MySQL de dos nodos, implementada mediante ClusterControl y ubicada fuera de la red de Kubernetes en una infraestructura completa, como se ilustra en el siguiente diagrama:
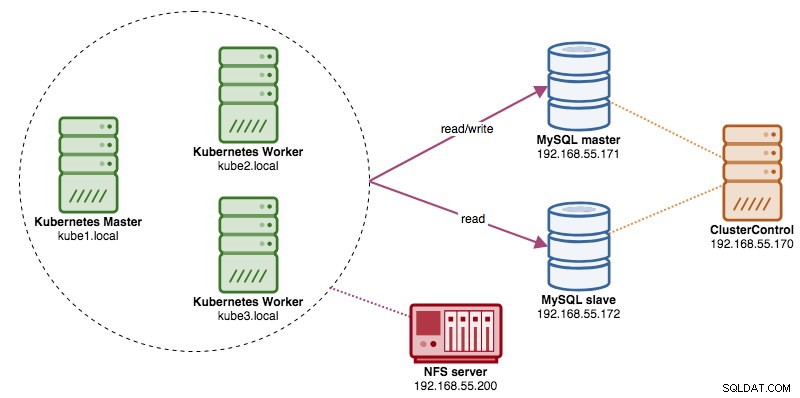
Imagen de ventana acoplable de ProxySQL
En este ejemplo, vamos a utilizar la imagen ProxySQL Docker mantenida por Variousnines, una imagen pública general creada para uso multipropósito. La imagen viene sin secuencia de comandos de punto de entrada y es compatible con Galera Cluster (además de la compatibilidad integrada con la replicación de MySQL), donde se requiere una secuencia de comandos adicional para fines de verificación de estado.
Básicamente, para ejecutar un contenedor ProxySQL, simplemente ejecute el siguiente comando:
$ docker run -d -v /path/to/proxysql.cnf:/etc/proxysql.cnf severalnines/proxysqlEsta imagen le recomienda vincular un archivo de configuración de ProxySQL al punto de montaje, /etc/proxysql.cnf, aunque puede omitirlo y configurarlo más tarde mediante la consola de administración de ProxySQL. Se proporcionan configuraciones de ejemplo en la página de Docker Hub o en la página de Github.
ProxySQL en Kubernetes
El diseño de la arquitectura de ProxySQL es un tema subjetivo y depende en gran medida de la ubicación de los contenedores de la aplicación y la base de datos, así como de la función de ProxySQL en sí. ProxySQL no solo enruta las consultas, sino que también se puede usar para reescribir y almacenar en caché las consultas. Los hits de caché eficientes pueden requerir una configuración personalizada diseñada específicamente para la carga de trabajo de la base de datos de la aplicación.
Idealmente, podemos configurar ProxySQL para que sea administrado por Kubernetes con dos configuraciones:
- ProxySQL como servicio de Kubernetes (implementación centralizada).
- ProxySQL como contenedor auxiliar en un pod (implementación distribuida).
La primera opción es bastante sencilla, en la que creamos un pod de ProxySQL y le adjuntamos un servicio de Kubernetes. Las aplicaciones luego se conectarán al servicio ProxySQL a través de la red en los puertos configurados. El valor predeterminado es 6033 para el puerto de carga equilibrada de MySQL y 6032 para el puerto de administración de ProxySQL. Esta implementación se tratará en la próxima entrada del blog.
La segunda opción es un poco diferente. Kubernetes tiene un concepto llamado "pod". Puede tener uno o más contenedores por cápsula, estos están acoplados de manera relativamente estrecha. Los contenidos de un pod siempre se ubican y programan conjuntamente, y se ejecutan en un contexto compartido. Un pod es la unidad de contenedor manejable más pequeña en Kubernetes.
Ambas implementaciones se pueden distinguir fácilmente observando el siguiente diagrama:
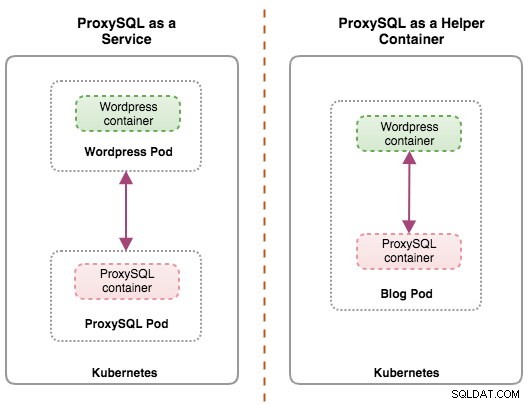
La razón principal por la que los pods pueden tener varios contenedores es para admitir aplicaciones auxiliares que ayudan a una aplicación principal. Ejemplos típicos de aplicaciones auxiliares son extractores de datos, impulsores de datos y proxies. Las aplicaciones auxiliares y primarias a menudo necesitan comunicarse entre sí. Por lo general, esto se hace a través de un sistema de archivos compartido, como se muestra en este ejercicio, o a través de la interfaz de red de bucle invertido, localhost. Un ejemplo de este patrón es un servidor web junto con un programa auxiliar que sondea un repositorio de Git en busca de nuevas actualizaciones.
Esta publicación de blog cubrirá la segunda configuración:ejecutar ProxySQL como un contenedor auxiliar en un pod.
ProxySQL como asistente en un pod
En esta configuración, ejecutamos ProxySQL como un contenedor auxiliar para nuestro contenedor de Wordpress. El siguiente diagrama ilustra nuestra arquitectura de alto nivel:
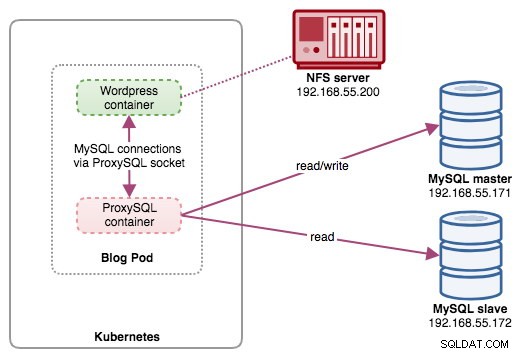
En esta configuración, el contenedor de ProxySQL está estrechamente relacionado con el contenedor de Wordpress, y lo llamamos pod de "blog". Si se produce una reprogramación, por ejemplo, el nodo trabajador de Kubernetes deja de funcionar, estos dos contenedores siempre se reprogramarán juntos como una unidad lógica en el próximo host disponible. Para mantener el contenido de los contenedores de la aplicación persistente en varios nodos, tenemos que usar un sistema de archivos remoto o en clúster, que en este caso es NFS.
El rol de ProxySQL es proporcionar una capa de abstracción de base de datos al contenedor de la aplicación. Dado que estamos ejecutando una replicación de MySQL de dos nodos como servicio de base de datos back-end, la división de lectura y escritura es vital para maximizar el consumo de recursos en ambos servidores MySQL. ProxySQL sobresale en esto y requiere cambios mínimos o nulos en la aplicación.
Hay una serie de otros beneficios al ejecutar ProxySQL en esta configuración:
- Acerque la capacidad de almacenamiento en caché de consultas a la capa de aplicación que se ejecuta en Kubernetes.
- Implementación segura al conectarse a través del archivo de socket ProxySQL UNIX. Es como una tubería que el servidor y los clientes pueden usar para conectarse e intercambiar solicitudes y datos.
- Nivel de proxy inverso distribuido con arquitectura compartida.
- Menos sobrecarga de la red debido a la implementación de "omisión de redes".
- Enfoque de implementación sin estado utilizando Kubernetes ConfigMaps.
Preparación de la base de datos
Cree la base de datos de wordpress y el usuario en el maestro y asigne el privilegio correcto:
mysql-master> CREATE DATABASE wordpress;
mysql-master> CREATE USER [email protected]'%' IDENTIFIED BY 'passw0rd';
mysql-master> GRANT ALL PRIVILEGES ON wordpress.* TO [email protected]'%';Además, cree el usuario de supervisión de ProxySQL:
mysql-master> CREATE USER [email protected]'%' IDENTIFIED BY 'proxysqlpassw0rd';Luego, vuelve a cargar la tabla de subvenciones:
mysql-master> FLUSH PRIVILEGES;Preparación de la vaina
Ahora, copie y pegue las siguientes líneas en un archivo llamado blog-deployment.yml en el host donde está configurado kubectl:
apiVersion: apps/v1
kind: Deployment
metadata:
name: blog
labels:
app: blog
spec:
replicas: 1
selector:
matchLabels:
app: blog
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: blog
tier: frontend
spec:
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmp
- image: severalnines/proxysql
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}El archivo YAML tiene muchas líneas y veamos solo la parte interesante. La primera sección:
apiVersion: apps/v1
kind: DeploymentLa primera línea es apiVersion. Nuestro clúster de Kubernetes se ejecuta en v1.12, por lo que debemos consultar la documentación de la API de Kubernetes v1.12 y seguir la declaración de recursos de acuerdo con esta API. El siguiente es el tipo, que indica qué tipo de recurso queremos implementar. Deployment, Service, ReplicaSet, DaemonSet, PersistentVolume son algunos de los ejemplos.
La siguiente sección importante es la sección de "contenedores". Aquí definimos todos los contenedores que nos gustaría ejecutar juntos en este pod. La primera parte es el contenedor de Wordpress:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmpEn esta sección, le decimos a Kubernetes que implemente Wordpress 4.9 usando el servidor web Apache y le dimos al contenedor el nombre "wordpress". También queremos que Kubernetes pase una serie de variables de entorno:
- WORDPRESS_DB_HOST - El host de la base de datos. Dado que nuestro contenedor ProxySQL reside en el mismo Pod que el contenedor de Wordpress, es más seguro usar un archivo de socket ProxySQL en su lugar. El formato para usar el archivo de socket en Wordpress es "localhost:{ruta al archivo de socket}". De forma predeterminada, se encuentra en el directorio /tmp del contenedor ProxySQL. Esta ruta /tmp se comparte entre los contenedores de Wordpress y ProxySQL mediante el uso de montajes de volumen de "datos compartidos", como se muestra más abajo. Ambos contenedores deben montar este volumen para compartir el mismo contenido en el directorio /tmp.
- WORDPRESS_DB_USER - Especifique el usuario de la base de datos de wordpress.
- WORDPRESS_DB_PASSWORD - La contraseña para WORDPRESS_DB_USER . Como no queremos exponer la contraseña en este archivo, podemos ocultarla usando Kubernetes Secrets. Aquí le indicamos a Kubernetes que lea el recurso secreto "mysql-pass" en su lugar. Los secretos deben crearse por adelantado antes de la implementación del pod, como se explica más adelante.
También queremos publicar el puerto 80 del contenedor para el usuario final. El contenido de Wordpress almacenado dentro de /var/www/html en el contenedor se montará en nuestro almacenamiento persistente que se ejecuta en NFS.
A continuación, definimos el contenedor ProxySQL:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
ports:
- containerPort: 6033
name: proxysqlEn la sección anterior, le decimos a Kubernetes que implemente un ProxySQL usando severalnines/proxysql imagen versión 1.4.12. También queremos que Kubernetes monte nuestro archivo de configuración personalizado y preconfigurado y lo asigne a /etc/proxysql.cnf dentro del contenedor. Habrá un volumen llamado "datos compartidos" que se asigna al directorio /tmp para compartir con la imagen de Wordpress, un directorio temporal que comparte la vida útil de un pod. Esto permite que el archivo de socket ProxySQL (/tmp/proxysql.sock) sea utilizado por el contenedor de Wordpress cuando se conecta a la base de datos, sin pasar por la red TCP/IP.
La última parte es la sección "volúmenes":
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}Kubernetes tendrá que crear tres volúmenes para este pod:
- wordpress-persistent-storage:use PersistentVolumeClaim recurso para mapear la exportación de NFS en el contenedor para el almacenamiento persistente de datos para el contenido de Wordpress.
- proxysql-config - Usa el ConfigMap recurso para asignar el archivo de configuración de ProxySQL.
- datos compartidos:use el emptyDir resource para montar un directorio compartido para nuestros contenedores dentro del Pod. dirección vacía resource es un directorio temporal que comparte la vida útil de un pod.
Por lo tanto, según nuestra definición de YAML anterior, tenemos que preparar una serie de recursos de Kubernetes antes de que podamos comenzar a implementar el pod de "blog":
- Volumen persistente y Reclamación de volumen persistente - Para almacenar los contenidos web de nuestra aplicación Wordpress, de modo que cuando el pod se reprograme a otro nodo trabajador, no perderemos los últimos cambios.
- Secretos - Para ocultar la contraseña de usuario de la base de datos de Wordpress dentro del archivo YAML.
- Mapa de configuración - Para asignar el archivo de configuración al contenedor ProxySQL, de modo que cuando se reprograme a otro nodo, Kubernetes pueda volver a montarlo automáticamente.
PersistentVolume y PersistentVolumeClaim
Todos los nodos de Kubernetes del clúster deberían poder acceder a un buen almacenamiento persistente para Kubernetes. Por el bien de esta publicación de blog, usamos NFS como el proveedor PersistentVolume (PV) porque es fácil y compatible de forma inmediata. El servidor NFS está ubicado en algún lugar fuera de nuestra red de Kubernetes y lo hemos configurado para permitir todos los nodos de Kubernetes con la siguiente línea dentro de /etc/exports:
/nfs 192.168.55.*(rw,sync,no_root_squash,no_all_squash)Tenga en cuenta que el paquete de cliente NFS debe estar instalado en todos los nodos de Kubernetes. De lo contrario, Kubernetes no podría montar el NFS correctamente. En todos los nodos:
$ sudo apt-install nfs-common #Ubuntu/Debian
$ yum install nfs-utils #RHEL/CentOSAdemás, asegúrese de que en el servidor NFS exista el directorio de destino:
(nfs-server)$ mkdir /nfs/kubernetes/wordpressLuego, crea un archivo llamado wordpress-pv-pvc.yml y agregue las siguientes líneas:
apiVersion: v1
kind: PersistentVolume
metadata:
name: wp-pv
labels:
app: blog
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 3Gi
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /nfs/kubernetes/wordpress
server: 192.168.55.200
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: wp-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
selector:
matchLabels:
app: blog
tier: frontendEn la definición anterior, nos gustaría que Kubernetes asignara 3 GB de espacio de volumen en el servidor NFS para nuestro contenedor de Wordpress. Tome nota del uso de producción, NFS debe configurarse con aprovisionador automático y clase de almacenamiento.
Cree los recursos PV y PVC:
$ kubectl create -f wordpress-pv-pvc.ymlVerifique si esos recursos están creados y el estado debe ser "Bound":
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/wp-pv 3Gi RWO Recycle Bound default/wp-pvc 22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/wp-pvc Bound wp-pv 3Gi RWO 22hSecretos
El primero es crear un secreto para ser utilizado por el contenedor de Wordpress para WORDPRESS_DB_PASSWORD Variable ambiental. La razón es simplemente porque no queremos exponer la contraseña en texto claro dentro del archivo YAML.
Cree un recurso secreto llamado mysql-pass y pase la contraseña correspondiente:
$ kubectl create secret generic mysql-pass --from-literal=password=passw0rdVerifica que nuestro secreto esté creado:
$ kubectl get secrets mysql-pass
NAME TYPE DATA AGE
mysql-pass Opaque 1 7h12mMapa de configuración
También necesitamos crear un recurso ConfigMap para nuestro contenedor ProxySQL. Un archivo ConfigMap de Kubernetes contiene pares clave-valor de datos de configuración que pueden consumirse en pods o usarse para almacenar datos de configuración. ConfigMaps le permite separar los artefactos de configuración del contenido de la imagen para mantener la portabilidad de las aplicaciones en contenedores.
Dado que nuestro servidor de base de datos ya se ejecuta en servidores completos con un nombre de host y una dirección IP estáticos, además de un nombre de usuario y una contraseña de monitoreo estáticos, en este caso de uso, el archivo ConfigMap almacenará información de configuración preconfigurada sobre el servicio ProxySQL que queremos usar.
Primero cree un archivo de texto llamado proxysql.cnf y agregue las siguientes líneas:
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="admin:adminpassw0rd"
mysql_ifaces="0.0.0.0:6032"
refresh_interval=2000
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033;/tmp/proxysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.1.30"
connect_timeout_server=10000
monitor_history=60000
monitor_connect_interval=200000
monitor_ping_interval=200000
ping_interval_server_msec=10000
ping_timeout_server=200
commands_stats=true
sessions_sort=true
monitor_username="proxysql"
monitor_password="proxysqlpassw0rd"
}
mysql_servers =
(
{ address="192.168.55.171" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.171" , port=3306 , hostgroup=20, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=20, max_connections=100 }
)
mysql_users =
(
{ username = "wordpress" , password = "passw0rd" , default_hostgroup = 10 , active = 1 }
)
mysql_query_rules =
(
{
rule_id=100
active=1
match_pattern="^SELECT .* FOR UPDATE"
destination_hostgroup=10
apply=1
},
{
rule_id=200
active=1
match_pattern="^SELECT .*"
destination_hostgroup=20
apply=1
},
{
rule_id=300
active=1
match_pattern=".*"
destination_hostgroup=10
apply=1
}
)
mysql_replication_hostgroups =
(
{ writer_hostgroup=10, reader_hostgroup=20, comment="MySQL Replication 5.7" }
)Preste especial atención a las secciones "mysql_servers" y "mysql_users", donde es posible que deba modificar los valores para adaptarlos a la configuración del clúster de su base de datos. En este caso, tenemos dos servidores de bases de datos que se ejecutan en MySQL Replication, como se resume en la siguiente captura de pantalla de topología tomada de ClusterControl:
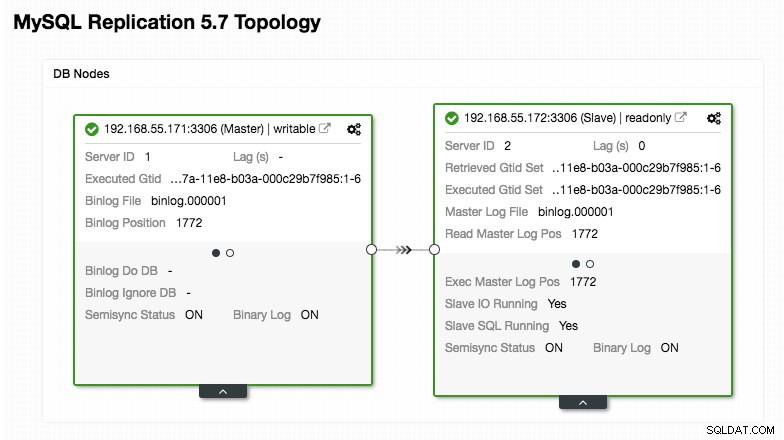
Todas las escrituras deben ir al nodo maestro mientras que las lecturas se reenvían al grupo de host 20, como se define en la sección "mysql_query_rules". Eso es lo básico de la división de lectura/escritura y queremos utilizarlos por completo.
Luego, importe el archivo de configuración a ConfigMap:
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnf
configmap/proxysql-configmap createdVerifique si el ConfigMap está cargado en Kubernetes:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 45sImplementación del módulo
Ahora deberíamos estar listos para implementar el blog pod. Envíe el trabajo de implementación a Kubernetes:
$ kubectl create -f blog-deployment.ymlVerifique el estado del pod:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-t4cb7 2/2 Running 0 100sDebe mostrar 2/2 debajo de la columna LISTO, lo que indica que hay dos contenedores funcionando dentro del módulo. Use el indicador de opción -c para verificar los contenedores de Wordpress y ProxySQL dentro del módulo del blog:
$ kubectl logs blog-54755cbcb5-t4cb7 -c wordpress
$ kubectl logs blog-54755cbcb5-t4cb7 -c proxysqlDesde el registro del contenedor de ProxySQL, debería ver las siguientes líneas:
2018-10-20 08:57:14 [INFO] Dumping current MySQL Servers structures for hostgroup ALL
HID: 10 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 10 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: OFFLINE_HARD , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:HID 10 (grupo de host escritor) debe tener solo un nodo EN LÍNEA (que indica un solo maestro) y el otro host debe estar al menos en estado OFFLINE_HARD. Para HID 20, se espera que esté EN LÍNEA para todos los nodos (lo que indica varias réplicas de lectura).
Para obtener un resumen de la implementación, use el indicador de descripción:
$ kubectl describe deployments blogNuestro blog ahora se está ejecutando, sin embargo, no podemos acceder a él desde fuera de la red de Kubernetes sin configurar el servicio, como se explica en la siguiente sección.
Creación del servicio de blogs
El último paso es crear un servicio adjunto a nuestro pod. Esto para garantizar que nuestro blog de Wordpress sea accesible desde el mundo exterior. Cree un archivo llamado blog-svc.yml y pegue la siguiente línea:
apiVersion: v1
kind: Service
metadata:
name: blog
labels:
app: blog
tier: frontend
spec:
type: NodePort
ports:
- name: blog
nodePort: 30080
port: 80
selector:
app: blog
tier: frontendCree el servicio:
$ kubectl create -f blog-svc.ymlVerifique si el servicio se creó correctamente:
[email protected]:~/proxysql-blog# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
blog NodePort 10.96.140.37 <none> 80:30080/TCP 26s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 43hEl puerto 80 publicado por el blog pod ahora está asignado al mundo exterior a través del puerto 30080. Podemos acceder a nuestra publicación de blog en http://{any_kubernetes_host}:30080/ y debe ser redirigido a la página de instalación de Wordpress. Si procedemos con la instalación, se saltaría la parte de conexión a la base de datos y mostraría directamente esta página:
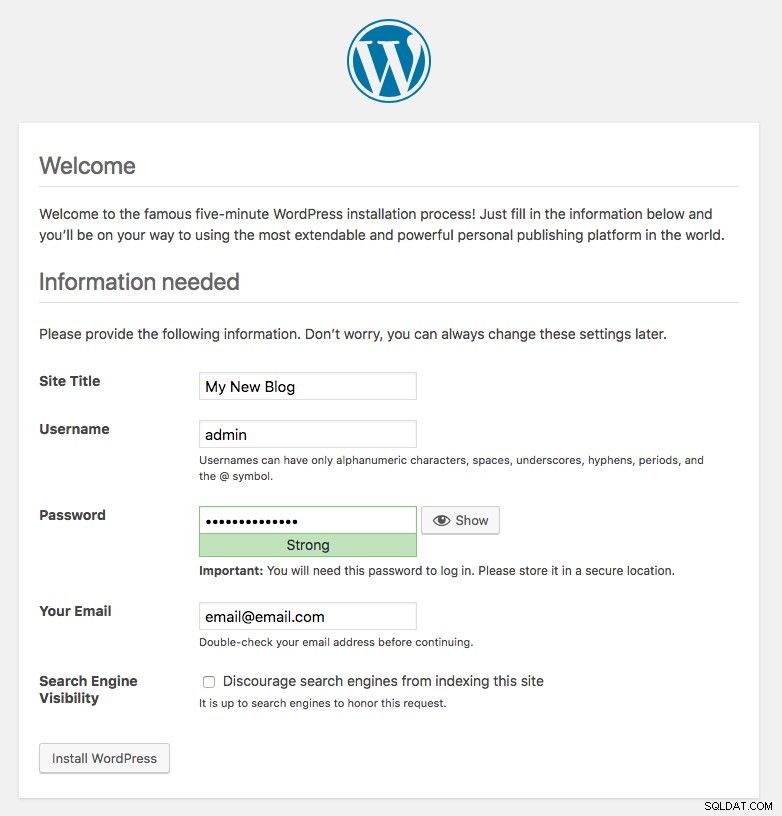
Indica que nuestra configuración de MySQL y ProxySQL está correctamente configurada dentro del archivo wp-config.php. De lo contrario, sería redirigido a la página de configuración de la base de datos.
Nuestro despliegue ahora está completo.
Administrar el contenedor ProxySQL dentro de un pod
Se espera que Kubernetes maneje automáticamente la conmutación por error y la recuperación. Por ejemplo, si el trabajador de Kubernetes deja de funcionar, el pod se volverá a crear en el siguiente nodo disponible después de --pod-eviction-timeout (predeterminado en 5 minutos). Si el contenedor falla o muere, Kubernetes lo reemplazará casi al instante.
Se espera que algunas tareas de administración comunes sean diferentes cuando se ejecutan dentro de Kubernetes, como se muestra en las siguientes secciones.
Ampliar y reducir
En la configuración anterior, estábamos implementando una réplica en nuestra implementación. Para escalar, simplemente cambie spec.replicas valor en consecuencia usando el comando de edición de kubectl:
$ kubectl edit deployment blogAbrirá la definición de implementación en un archivo de texto predeterminado y simplemente cambiará spec.replicas valor a algo superior, por ejemplo, "réplicas:3". Luego, guarde el archivo e inmediatamente verifique el estado de implementación usando el siguiente comando:
$ kubectl rollout status deployment blog
Waiting for deployment "blog" rollout to finish: 1 of 3 updated replicas are available...
Waiting for deployment "blog" rollout to finish: 2 of 3 updated replicas are available...
deployment "blog" successfully rolled outEn este punto, tenemos tres grupos de blogs (Wordpress + ProxySQL) ejecutándose simultáneamente en Kubernetes:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 11m
blog-54755cbcb5-cwpdj 2/2 Running 0 11m
blog-54755cbcb5-jxtvc 2/2 Running 0 22mEn este punto, nuestra arquitectura se parece a esto:
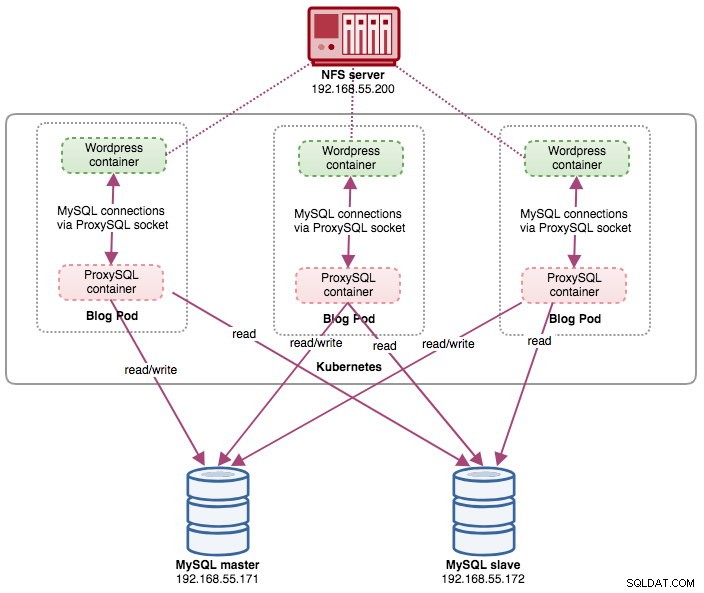
Tenga en cuenta que podría requerir más personalización que nuestra configuración actual para ejecutar Wordpress sin problemas en un entorno de producción de escala horizontal (piense en contenidos estáticos, administración de sesiones y otros). Esos están más allá del alcance de esta publicación de blog.
Los procedimientos de reducción son similares.
Gestión de la configuración
La gestión de la configuración es importante en ProxySQL. Aquí es donde ocurre la magia, donde puede definir su propio conjunto de reglas de consulta para realizar el almacenamiento en caché de consultas, el cortafuegos y la reescritura. Contrariamente a la práctica común, donde ProxySQL se configuraría a través de la consola de administración y se impulsaría a la persistencia usando "SAVE .. TO DISK", nos quedaremos con los archivos de configuración solo para hacer que las cosas sean más portátiles en Kubernetes. Esa es la razón por la que usamos ConfigMaps.
Dado que confiamos en nuestra configuración centralizada almacenada por Kubernetes ConfigMaps, hay varias formas de realizar cambios de configuración. En primer lugar, usando el comando de edición de kubectl:
$ kubectl edit configmap proxysql-configmapAbrirá la configuración en un editor de texto predeterminado y podrá realizar cambios directamente y guardar el archivo de texto una vez hecho. De lo contrario, recrear los mapas de configuración también debería hacer:
$ vi proxysql.cnf # edit the configuration first
$ kubectl delete configmap proxysql-configmap
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnfDespués de enviar la configuración a ConfigMap, reinicie el pod o contenedor como se muestra en la sección Control de servicios. La configuración del contenedor a través de la interfaz de administración de ProxySQL (puerto 6032) no lo hará persistente después de que Kubernetes reprograme el pod.
Control de Servicios
Dado que los dos contenedores dentro de un pod están estrechamente acoplados, la mejor manera de aplicar los cambios de configuración de ProxySQL es obligar a Kubernetes a reemplazar el pod. Considere que tenemos tres grupos de blogs ahora después de que ampliamos:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-jxtvc 2/2 Running 1 22mUse el siguiente comando para reemplazar un pod a la vez:
$ kubectl get pod blog-54755cbcb5-6fnqn -n default -o yaml | kubectl replace --force -f -
pod "blog-54755cbcb5-6fnqn" deleted
pod/blog-54755cbcb5-6fnqnLuego, verifique con lo siguiente:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-qs6jm 2/2 Running 1 2m26sNotará que el pod más reciente se ha reiniciado al mirar la columna EDAD y REINICIO, apareció con un nombre de pod diferente. Repita los mismos pasos para las vainas restantes. De lo contrario, también puede usar el comando "docker kill" para eliminar el contenedor ProxySQL manualmente dentro del nodo de trabajo de Kubernetes. Por ejemplo:
(kube-worker)$ docker kill $(docker ps | grep -i proxysql_blog | awk {'print $1'})Kubernetes luego reemplazará el contenedor ProxySQL eliminado por uno nuevo.
Monitoreo
Use el comando kubectl exec para ejecutar la instrucción SQL a través del cliente mysql. Por ejemplo, para monitorear la digestión de consultas:
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032
mysql> SELECT * FROM stats_mysql_query_digest;O con una sola línea:
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032 -e 'SELECT * FROM stats_mysql_query_digest'Al cambiar la instrucción SQL, puede monitorear otros componentes de ProxySQL o realizar cualquier tarea de administración a través de esta consola de administración. Nuevamente, solo persistirá durante la vida útil del contenedor ProxySQL y no se mantendrá si se reprograma el pod.
Reflexiones finales
ProxySQL tiene un papel clave si desea escalar sus contenedores de aplicaciones y tener una forma inteligente de acceder a un backend de base de datos distribuido. Hay varias formas de implementar ProxySQL en Kubernetes para respaldar el crecimiento de nuestra aplicación cuando se ejecuta a escala. Esta publicación de blog solo cubre uno de ellos.
En una próxima publicación de blog, veremos cómo ejecutar ProxySQL en un enfoque centralizado usándolo como un servicio de Kubernetes.