Galera Cluster viene con muchas características notables que no están disponibles en la replicación estándar de MySQL (o replicación de grupo); aprovisionamiento automático de nodos, verdadero multimaestro con resolución de conflictos y conmutación por error automática. También hay una serie de limitaciones que podrían afectar potencialmente el rendimiento del clúster. Afortunadamente, si no está al tanto de esto, existen soluciones alternativas. Y si lo hace bien, puede minimizar el impacto de estas limitaciones y mejorar el rendimiento general.
Anteriormente cubrimos muchos consejos y trucos relacionados con Galera Cluster, incluida la ejecución de Galera en la nube de AWS. Esta publicación de blog se sumerge claramente en los aspectos de rendimiento, con ejemplos sobre cómo aprovechar Galera al máximo.
Carga útil de replicación
Un poco de introducción:Galera replica los conjuntos de escritura durante la etapa de confirmación, transfiriendo los conjuntos de escritura desde el nodo de origen a los nodos receptores de forma síncrona a través del complemento de replicación wsrep. Este complemento también certificará los conjuntos de escritura en los nodos receptores. Si el proceso de certificación pasa, devuelve OK al cliente en el nodo de origen y se aplicará en los nodos de recepción en un momento posterior de forma asíncrona. De lo contrario, la transacción se revertirá en el nodo de origen (devolviendo el error al cliente) y los conjuntos de escritura que se hayan transferido a los nodos de recepción se descartarán.
Un conjunto de escritura consta de operaciones de escritura dentro de una transacción que cambia el estado de la base de datos. En Galera Cluster, confirmación automática está predeterminado en 1 (habilitado). Literalmente, cualquier instrucción SQL ejecutada en Galera Cluster se adjuntará como una transacción, a menos que comience explícitamente con BEGIN, START TRANSACTION o SET autocommit=0. El siguiente diagrama ilustra la encapsulación de una declaración DML única en un conjunto de escritura:
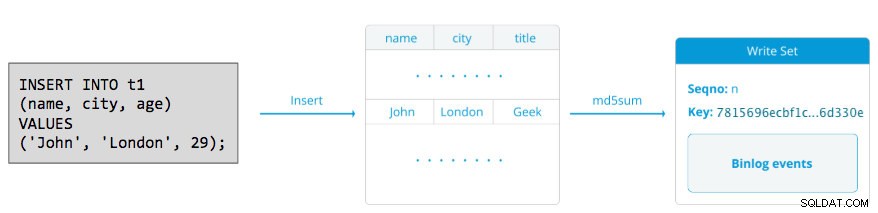
Para DML (INSERTAR, ACTUALIZAR, ELIMINAR...), la carga útil del conjunto de escritura consiste en los eventos de registro binario para una transacción en particular, mientras que para DDL (ALTERAR, CONCEDER, CREAR...), la carga útil del conjunto de escritura es la instrucción DDL en sí. Para DML, el conjunto de escritura deberá estar certificado contra conflictos en el nodo receptor, mientras que para DDL (dependiendo de wsrep_osu_method , predeterminado en TOI), el clúster del clúster ejecuta la instrucción DDL en todos los nodos en la misma secuencia de orden total, bloqueando la confirmación de otras transacciones mientras el DDL está en curso (consulte también RSU). En palabras simples, Galera Cluster maneja la replicación DDL y DML de manera diferente.
Tiempo de ida y vuelta
En general, los siguientes factores determinan qué tan rápido Galera puede replicar un conjunto de escritura desde un nodo originador a todos los nodos receptores:
- Tiempo de ida y vuelta (RTT) al nodo más alejado del clúster desde el nodo de origen.
- El tamaño de un conjunto de escritura que se transferirá y certificará en caso de conflicto en el nodo receptor.
Por ejemplo, si tenemos un clúster de Galera de tres nodos y uno de los nodos se encuentra a 10 milisegundos (0,01 segundos), es muy poco probable que pueda escribir más de 100 veces por segundo en la misma fila sin generar conflictos. Hay una cita popular de Mark Callaghan que describe bastante bien este comportamiento:
"[En un clúster de Galera] una fila determinada no se puede modificar más de una vez por RTT"
Para medir el valor de RTT, simplemente realice un ping en el nodo de origen al nodo más alejado del clúster:
$ ping 192.168.55.173 # the farthest nodeEspere un par de segundos (o minutos) y finalice el comando. La última línea de la sección de estadísticas de ping es lo que estamos buscando:
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 msEl máximo el valor es 1,340 ms (0,00134 s) y debemos tomar este valor al estimar el mínimo transacciones por segundo (tps) para este clúster. El promedio el valor es 0.431ms (0.000431s) y podemos usarlo para estimar el promedio tps mientras min el valor es 0.111ms (0.000111s) que podemos usar para estimar el máximo tps. El mdev significa cómo se distribuyeron las muestras de RTT a partir del promedio. Un valor más bajo significa un RTT más estable.
Por lo tanto, las transacciones por segundo se pueden estimar dividiendo RTT (en segundos) en 1 segundo:

Resultante,
- Tps mínimo:1/0,00134 (RTT máx.) =746,26 ~ 746 tps
- Promedio de tps:1/0,000431 (RTT medio) =2320,19 ~ 2320 tps
- Tps máximo:1/0,000111 (RTT mínimo) =9009,01 ~ 9009 tps
Tenga en cuenta que esto es solo una estimación para anticipar el rendimiento de la replicación. No hay mucho que podamos hacer para mejorar esto en el lado de la base de datos, una vez que tengamos todo implementado y funcionando. Excepto si mueve o migra los servidores de la base de datos más cerca uno del otro para mejorar el RTT entre nodos o actualizar los periféricos o la infraestructura de la red. Esto requeriría una ventana de mantenimiento y una planificación adecuada.
Dividir grandes transacciones
Otro factor es el tamaño de la transacción. Después de que se transfiera el conjunto de escritura, habrá un proceso de certificación. La certificación es un proceso para determinar si el nodo puede o no aplicar el conjunto de escritura. Galera genera pseudoclaves de suma de comprobación MD5 a partir de cada fila completa. El costo de la certificación depende del tamaño del conjunto de escritura, lo que se traduce en una serie de búsquedas de claves únicas en el índice de certificación (una tabla hash). Si actualiza 500 000 filas en una sola transacción, por ejemplo:
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;Lo anterior generará un único conjunto de escritura con 500 000 eventos de registro binario. Este enorme conjunto de escritura no supera wsrep_max_ws_size (predeterminado en 2 GB) por lo que será transferido por el complemento de replicación de Galera a todos los nodos del clúster, certificando estas 500 000 filas en los nodos receptores para cualquier transacción en conflicto que aún esté en la cola esclava. Finalmente, el estado de certificación se devuelve al complemento de replicación de grupo. Cuanto mayor sea el tamaño de la transacción, mayor será el riesgo de que entre en conflicto con otras transacciones que provienen de otro maestro. Las transacciones en conflicto desperdician los recursos del servidor, además de causar una gran reversión al nodo de origen. Tenga en cuenta que una operación de reversión en MySQL es mucho más lenta y menos optimizada que una operación de confirmación.
La declaración SQL anterior se puede reescribir en una declaración más amigable con Galera con la ayuda de un bucle simple, como el ejemplo a continuación:
(bash)$ for i in {1..500}; do \
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000"; \
sleep 2; \
doneEl comando de shell anterior actualizaría 1000 filas por transacción 500 veces y esperaría 2 segundos entre ejecuciones. También podría usar un procedimiento almacenado u otros medios para lograr un resultado similar. Si reescribir la consulta SQL no es una opción, simplemente indique a la aplicación que ejecute la gran transacción durante una ventana de mantenimiento para reducir el riesgo de conflictos.
Para eliminaciones grandes, considere usar pt-archiver de Percona Toolkit, un trabajo de solo avance de bajo impacto para eliminar datos antiguos de la tabla sin afectar mucho las consultas OLTP.
Hilos esclavos paralelos
En Galera, el aplicador es un proceso de múltiples subprocesos. Applier es un subproceso que se ejecuta dentro de Galera para aplicar los conjuntos de escritura entrantes desde otro nodo. Lo que significa que es posible que todos los receptores ejecuten múltiples operaciones DML que provienen directamente del nodo originador (maestro) simultáneamente. La replicación paralela de Galera solo se aplica a las transacciones cuando es seguro hacerlo. Mejora la probabilidad de que el nodo se sincronice con el nodo de origen. Sin embargo, la velocidad de replicación todavía está limitada a RTT y al tamaño del conjunto de escritura.
Para sacar lo mejor de esto, necesitamos saber dos cosas:
- La cantidad de núcleos que tiene el servidor.
- El valor de wsrep_cert_deps_distance estado.
El estado wsrep_cert_deps_distance nos dice el grado potencial de paralelización. Es el valor de la distancia promedio entre los valores de seqno más altos y más bajos que posiblemente se pueden aplicar en paralelo. Puede utilizar la wsrep_cert_deps_distance variable de estado para determinar el número máximo de subprocesos esclavos posibles. Tenga en cuenta que este es un valor promedio a lo largo del tiempo. Por lo tanto, para obtener un buen valor, debe ingresar al clúster con operaciones de escritura a través de una carga de trabajo de prueba o un punto de referencia hasta que vea un valor estable.
Para obtener la cantidad de núcleos, simplemente puede usar el siguiente comando:
$ grep -c processor /proc/cpuinfo
4Idealmente, 2, 3 o 4 subprocesos de aplicador esclavo por núcleo de CPU es un buen comienzo. Por lo tanto, el valor mínimo para los subprocesos esclavos debe ser 4 x la cantidad de núcleos de CPU y no debe exceder la wsrep_cert_deps_distance valor:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+Puede controlar el número de subprocesos del aplicador esclavo utilizando wsrep_slave_thread variable. Aunque esta es una variable dinámica, solo aumentar el número tendría un efecto inmediato. Si reduce el valor dinámicamente, tomará algún tiempo, hasta que el hilo del aplicador salga después de que termine de aplicarse. Un valor recomendado es entre 16 y 48:
mysql> SET GLOBAL wsrep_slave_threads = 48;Tenga en cuenta que para que funcionen los subprocesos esclavos paralelos, se debe configurar lo siguiente (que generalmente está preconfigurado para Galera Cluster):
innodb_autoinc_lock_mode=2Caché de Galera (gcache)
Galera usa un archivo preasignado con un tamaño específico llamado gcache, donde un nodo de Galera guarda una copia de los conjuntos de escritura en un estilo de búfer circular. Por defecto, su tamaño es de 128 MB, que es bastante pequeño. La transferencia de estado incremental (IST) es un método para preparar un ensamblador enviando solo los conjuntos de escritura faltantes disponibles en el gcache del donante. IST es más rápido que la transferencia de instantáneas de estado (SST), no bloquea y no tiene un impacto significativo en el rendimiento del donante. Debe ser la opción preferida siempre que sea posible.
IST solo se puede lograr si todos los cambios perdidos por el ensamblador todavía están en el archivo gcache del donante. La configuración recomendada para esto es que sea tan grande como todo el conjunto de datos de MySQL. Si el espacio en disco es limitado o costoso, es crucial determinar el tamaño correcto de gcache, ya que puede influir en el rendimiento de la sincronización de datos entre los nodos de Galera.
La siguiente declaración nos dará una idea de la cantidad de datos replicados por Galera. Ejecute la siguiente instrucción en uno de los nodos de Galera durante las horas pico (probado en MariaDB>10.0 y PXC>5.6, galera>3.x):
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+
Podemos estimar que el nodo de Galera puede tener aproximadamente 16 minutos de tiempo de inactividad, sin necesidad de que SST se una (a menos que Galera no pueda determinar el estado de unión). Si es demasiado poco tiempo y tiene suficiente espacio en disco en sus nodos, puede cambiar wsrep_provider_options="gcache.size=
También se recomienda usar gcache.recover=yes en wsrep_provider_options (Galera>3.19), donde Galera intentará recuperar el archivo gcache a un estado utilizable en el inicio en lugar de eliminarlo, preservando así la capacidad de tener IST y evitando SST tanto como sea posible. Codership y Percona han cubierto esto en detalle en sus blogs. IST siempre es el mejor método para sincronizar después de que un nodo se reincorpora al clúster. Es un 50 % más rápido que xtrabackup o mariabackup y 5 veces más rápido que mysqldump.
Esclavo asíncrono
Los nodos de Galera están estrechamente acoplados, donde el rendimiento de replicación es tan rápido como el nodo más lento. Galera utiliza un mecanismo de control de flujo para controlar el flujo de replicación entre los miembros y eliminar cualquier retraso esclavo. La replicación puede ser rápida o lenta en cada nodo y Galera la ajusta automáticamente. Si desea obtener información sobre el control de flujo, lea esta publicación de blog de Jay Janssen de Percona.
En la mayoría de los casos, las operaciones pesadas como los análisis de ejecución prolongada (intensivos de lectura) y las copias de seguridad (intensivos de lectura, bloqueo) suelen ser inevitables, lo que podría degradar el rendimiento del clúster. La mejor manera de ejecutar este tipo de consultas es enviándolas a un servidor réplica débilmente acoplado, por ejemplo, un esclavo asíncrono.
Un esclavo asíncrono replica desde un nodo Galera utilizando el protocolo de replicación asíncrona estándar de MySQL. No hay límite en la cantidad de esclavos que se pueden conectar a un nodo Galera, y también es posible encadenarlo con un maestro intermedio. Las operaciones de MySQL que se ejecutan en este servidor no afectarán el rendimiento del clúster, aparte de la fase de sincronización inicial en la que se debe realizar una copia de seguridad completa en el nodo Galera para organizar el esclavo antes de establecer el enlace de replicación (aunque ClusterControl le permite construir el nodo asíncrono esclavo de una copia de seguridad existente primero, antes de conectarlo al clúster).
GTID (Identificador de transacción global) proporciona un mejor mapeo de transacciones entre nodos y es compatible con MySQL 5.6 y MariaDB 10.0. Con GTID, la operación de conmutación por error de un esclavo a otro maestro (otro nodo de Galera) se simplifica, sin necesidad de averiguar el archivo de registro y la posición exactos. Galera también viene con su propia implementación de GTID, pero estos dos son independientes entre sí.
El escalado horizontal de un esclavo asíncrono está a un clic de distancia si está utilizando ClusterControl -> Agregar función de esclavo de replicación:
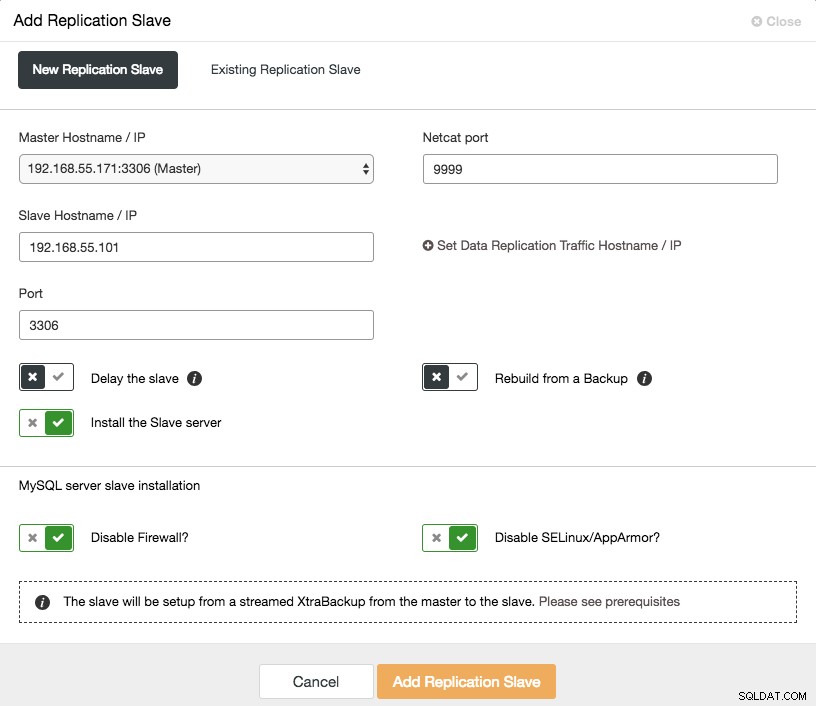
Tenga en cuenta que los registros binarios deben estar habilitados en el maestro (el nodo de Galera elegido) antes de que podamos continuar con esta configuración. También hemos cubierto la forma manual en esta publicación anterior.
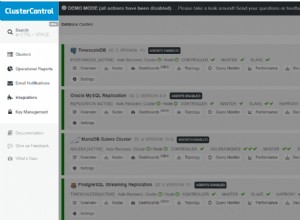
La siguiente captura de pantalla de ClusterControl muestra la topología del clúster, ilustra nuestra arquitectura Galera Cluster con un esclavo asíncrono:
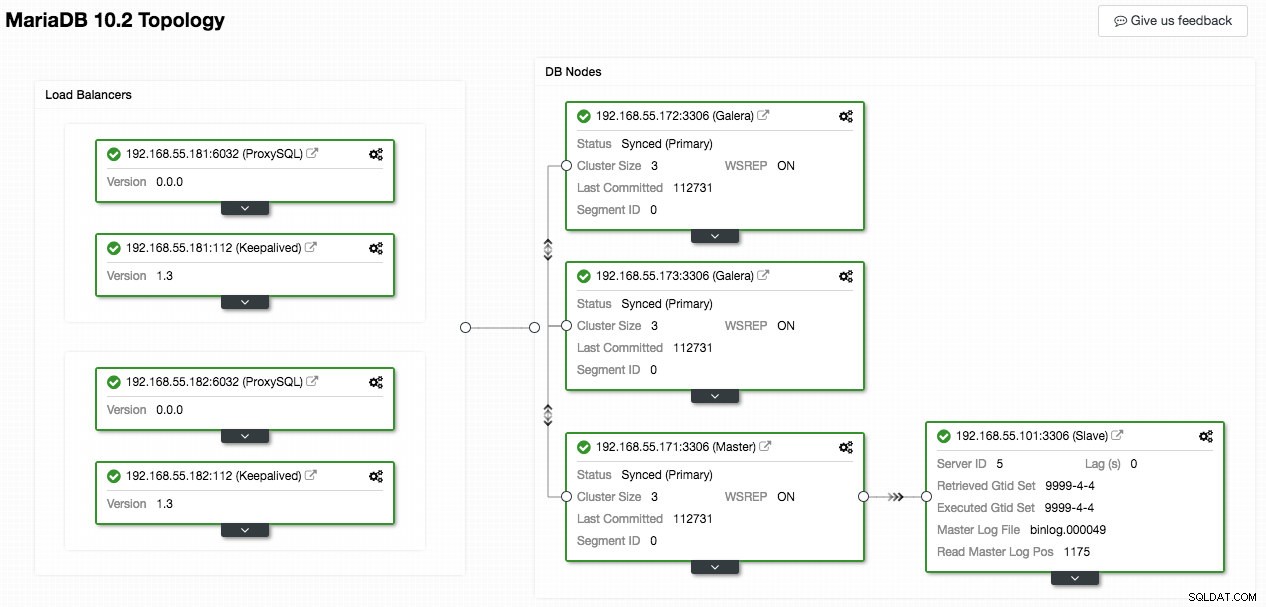
ClusterControl descubre automáticamente la topología y genera el diagrama súper genial como el anterior. También puede realizar tareas de administración directamente desde esta página haciendo clic en el icono de engranaje de la parte superior derecha de cada cuadro.
Proxy inverso compatible con SQL
ProxySQL y MariaDB MaxScale son proxies inversos inteligentes que comprenden el protocolo MySQL y son capaces de actuar como puerta de enlace, enrutador, equilibrador de carga y cortafuegos frente a sus nodos Galera. Con la ayuda de un proveedor de dirección IP virtual como LVS o Keepalived, y combinándolo con la tecnología de replicación multimaestro de Galera, podemos tener un servicio de base de datos de alta disponibilidad, eliminando todos los posibles puntos únicos de falla (SPOF) desde el punto de aplicación. -de vista. Esto seguramente mejorará la disponibilidad y confiabilidad de la arquitectura en su conjunto.
Otra ventaja con este enfoque es que tendrá la capacidad de monitorear, reescribir o redirigir las consultas SQL entrantes en función de un conjunto de reglas antes de que lleguen al servidor de la base de datos real, minimizando los cambios en la aplicación o del lado del cliente y enrutando las consultas a un nodo más adecuado para un rendimiento óptimo. Las consultas riesgosas para Galera, como LOCK TABLES y FLUSH TABLES WITH READ LOCK, pueden evitarse mucho antes de que causen estragos en el sistema, mientras que las consultas impactantes como las consultas de "punto de acceso" (una fila a la que diferentes consultas desean acceder al mismo tiempo) pueden ser reescrito o ser redirigido a un solo nodo de Galera para reducir el riesgo de conflictos de transacción. Para consultas pesadas de solo lectura como OLAP o copia de seguridad, puede enrutarlas a un esclavo asíncrono si tiene alguno.
El proxy inverso también supervisa el estado de la base de datos, las consultas y las variables para comprender los cambios en la topología y producir una decisión de enrutamiento precisa a los servidores back-end. Indirectamente, centraliza el monitoreo de los nodos y la descripción general del clúster sin la necesidad de verificar todos y cada uno de los nodos de Galera con regularidad. La siguiente captura de pantalla muestra el panel de monitoreo de ProxySQL en ClusterControl:
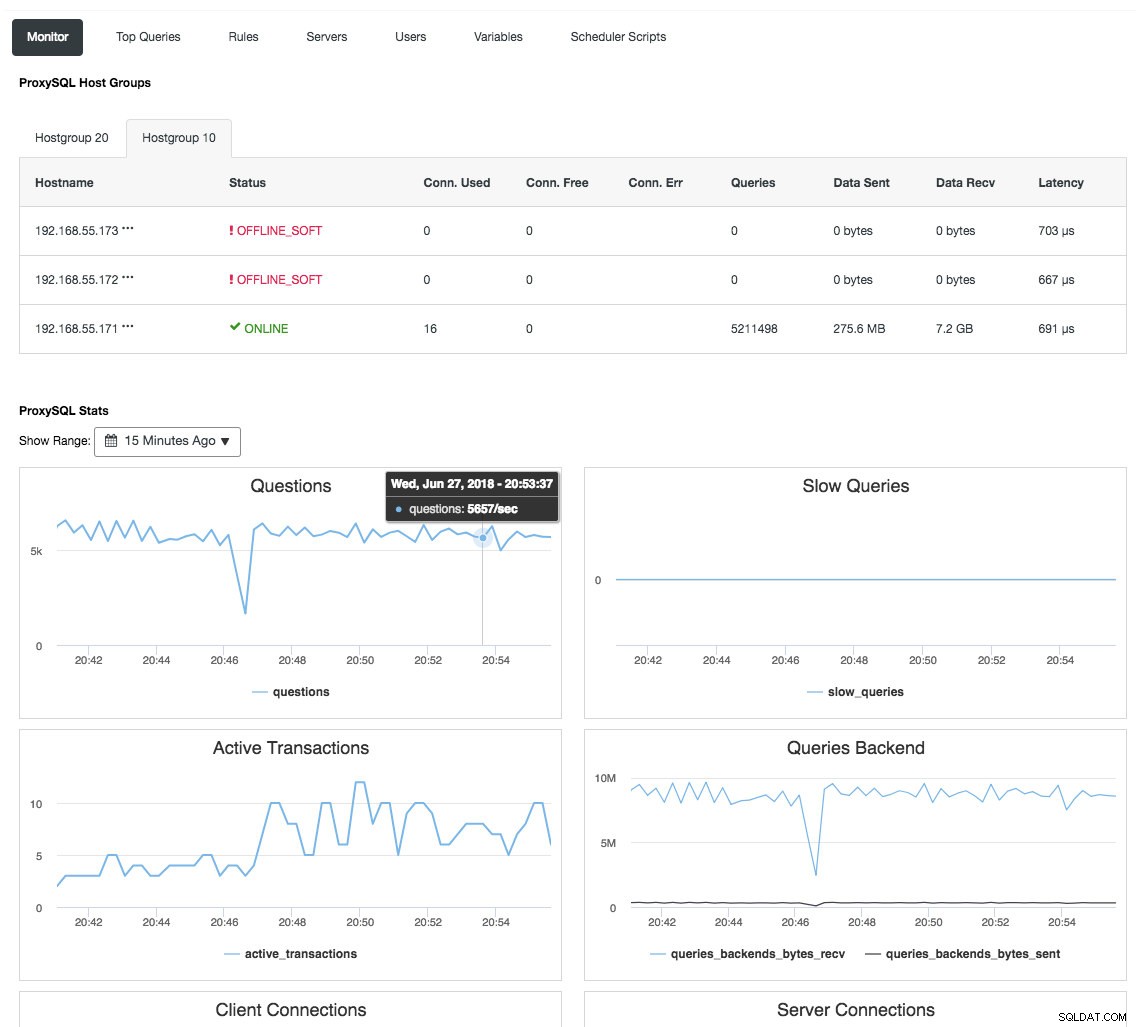
También hay muchos otros beneficios que un balanceador de carga puede aportar para mejorar Galera Cluster significativamente, como se explica en detalles en esta publicación de blog, Conviértase en un DBA de ClusterControl:Hacer que sus componentes de base de datos sean HA a través de Load Balancers.
Reflexiones finales
Con una buena comprensión de cómo funciona internamente Galera Cluster, podemos solucionar algunas de las limitaciones y mejorar el servicio de la base de datos. ¡Feliz agrupamiento!