Recibimos buenos comentarios con respecto a nuestro producto ClusterControl, especialmente lo fácil que es instalarlo y ponerlo en marcha. Instalar software nuevo es una cosa, pero usarlo correctamente es otra.
No es raro estar impaciente por probar un nuevo software y uno prefiere jugar con una aplicación nueva y emocionante que leer la documentación antes de comenzar. Eso es un poco desafortunado, ya que es posible que te pierdas funciones importantes o no entiendas cómo usarlas.
Esta serie de blog cubre todas las operaciones básicas de ClusterControl para MySQL, MongoDB y PostgreSQL con ejemplos sobre cómo aprovechar al máximo su configuración. Le proporciona una inmersión profunda en diferentes temas para ahorrarle tiempo.
Estos son los temas tratados en esta serie:
- Implementación de los primeros clústeres
- Agregar su infraestructura existente
- Supervisión del rendimiento y la salud
- Haciendo que sus componentes sean HA
- Gestión del flujo de trabajo
- Proteger sus datos
- Proteger sus datos
- Caso de uso detallado
En la publicación de hoy, cubriremos la instalación de ClusterControl y la implementación de sus primeros clústeres.
Preparativos
En esta serie, haremos uso de un conjunto de cajas Vagrant, pero puede usar su propia infraestructura si lo desea. En caso de que quiera probarlo con Vagrant, pusimos a su disposición una configuración de ejemplo en el siguiente repositorio de Github:https://github.com/severalnines/vagrant
Clone el repositorio en su propia máquina:
$ git clone [email protected]:severalnines/vagrant.gitLa topología de los nodos vagabundos es la siguiente:
- vm1:control de clúster
- vm2:base de datos nodo1
- vm3:base de datos nodo2
- vm4:base de datos nodo3
Si lo desea, puede agregar fácilmente nodos adicionales cambiando la siguiente línea:
4.times do |n|El archivo Vagrant está configurado para instalar automáticamente ClusterControl en el primer nodo y reenviar la interfaz de usuario de ClusterControl al puerto 8080 en su host que ejecuta Vagrant. Entonces, si la dirección IP de su host es 192.168.1.10, encontrará la interfaz de usuario de ClusterControl aquí:http://192.168.1.10:8080/clustercontrol/
Instalando Cluster Control
Puede omitir esto si elige usar el archivo Vagrant y obtener la instalación automática. Pero la instalación de ClusterControl es sencilla y llevará menos de cinco minutos.
Con la instalación del paquete, todo lo que tiene que hacer es ejecutar los siguientes tres comandos en el nodo ClusterControl para instalarlo:
$ wget http://www.severalnines.com/downloads/cmon/install-cc
$ chmod +x install-cc
$ ./install-cc # as root or sudo userEso es todo:no puede ser más fácil que esto. Si el script de instalación no ha encontrado ningún problema, entonces ClusterControl debe estar instalado y funcionando. Ahora puede iniciar sesión en ClusterControl en la siguiente URL:http://192.168.1.210/clustercontrol
Después de crear una cuenta de administrador e iniciar sesión, se le pedirá que agregue su primer clúster.
Implementar un clúster de Galera
Se le pedirá que cree un nuevo servidor/clúster de base de datos o que importe un servidor o clúster existente (es decir, ya implementado):
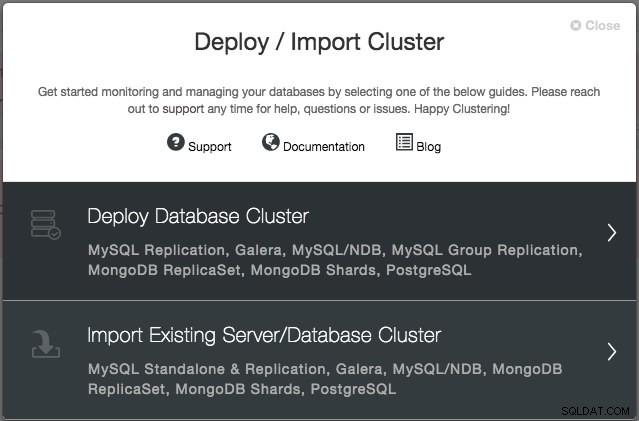
Vamos a implementar un clúster Galera. Hay dos secciones que deben completarse. La primera pestaña está relacionada con SSH y la configuración general:
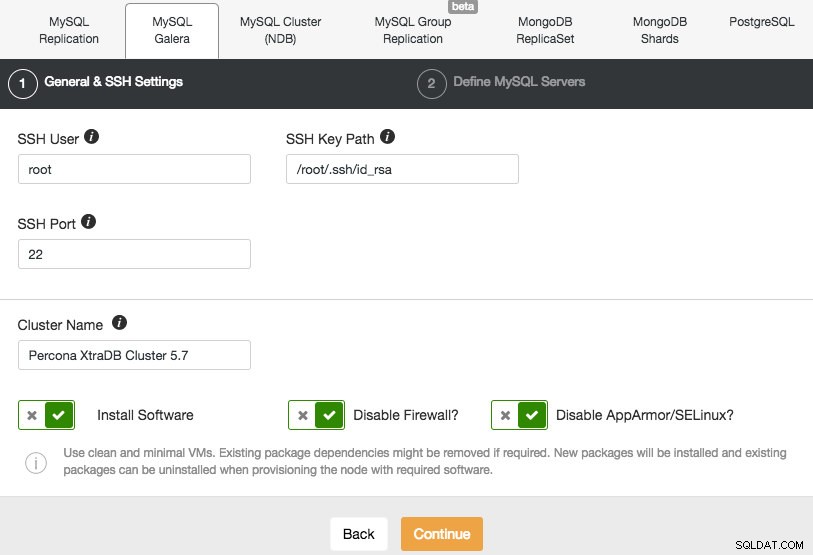
Para permitir que ClusterControl instale los nodos de Galera, usamos el usuario raíz al que los scripts de arranque de Vagrant le otorgaron acceso SSH. En caso de que elija usar su propia infraestructura, debe ingresar un usuario aquí que tenga permiso para hacer SSH sin contraseña a los nodos que controlará ClusterControl. Solo tenga en cuenta que debe configurar SSH sin contraseña desde ClusterControl a todos los nodos de la base de datos usted mismo de antemano.
También asegúrese de deshabilitar AppArmor/SELinux. Vea aquí por qué.
Luego, continúe con la segunda etapa y especifique la información relacionada con la base de datos y los hosts de destino:
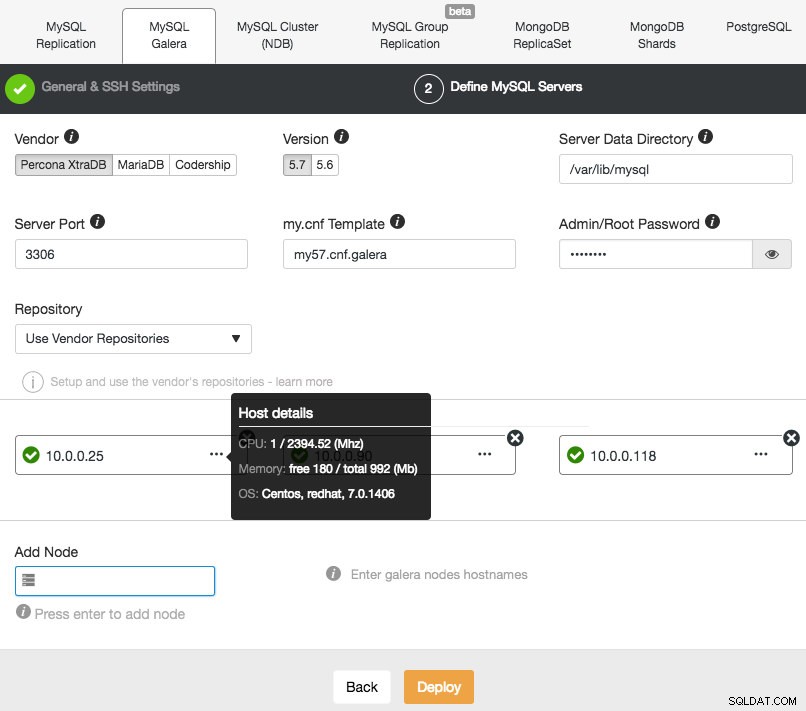
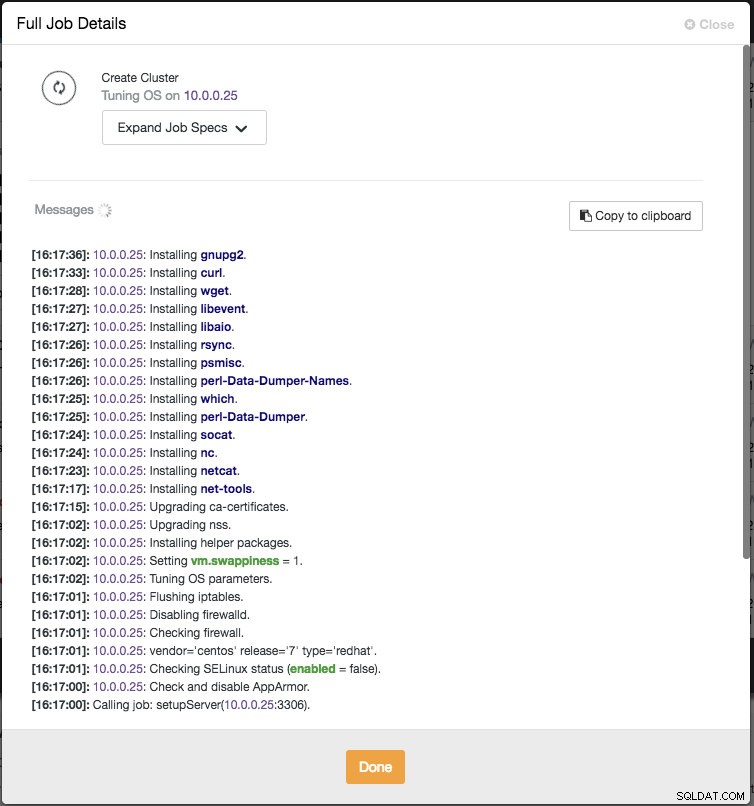
ClusterControl realizará inmediatamente algunas comprobaciones de cordura cada vez que presione Entrar al agregar un nodo. Puede ver el resumen del host al pasar el cursor sobre cada nodo definido. Una vez que todo esté en verde, significa que ClusterControl tiene conectividad con todos los nodos, puede hacer clic en Implementar. Se generará un trabajo para construir el nuevo clúster. Lo bueno es que puede realizar un seguimiento del progreso de este trabajo haciendo clic en Actividad -> Trabajos -> Crear grupo -> Detalles completos del trabajo :
Una vez que el trabajo ha terminado, acaba de crear su primer clúster. La descripción general del clúster debería verse así:
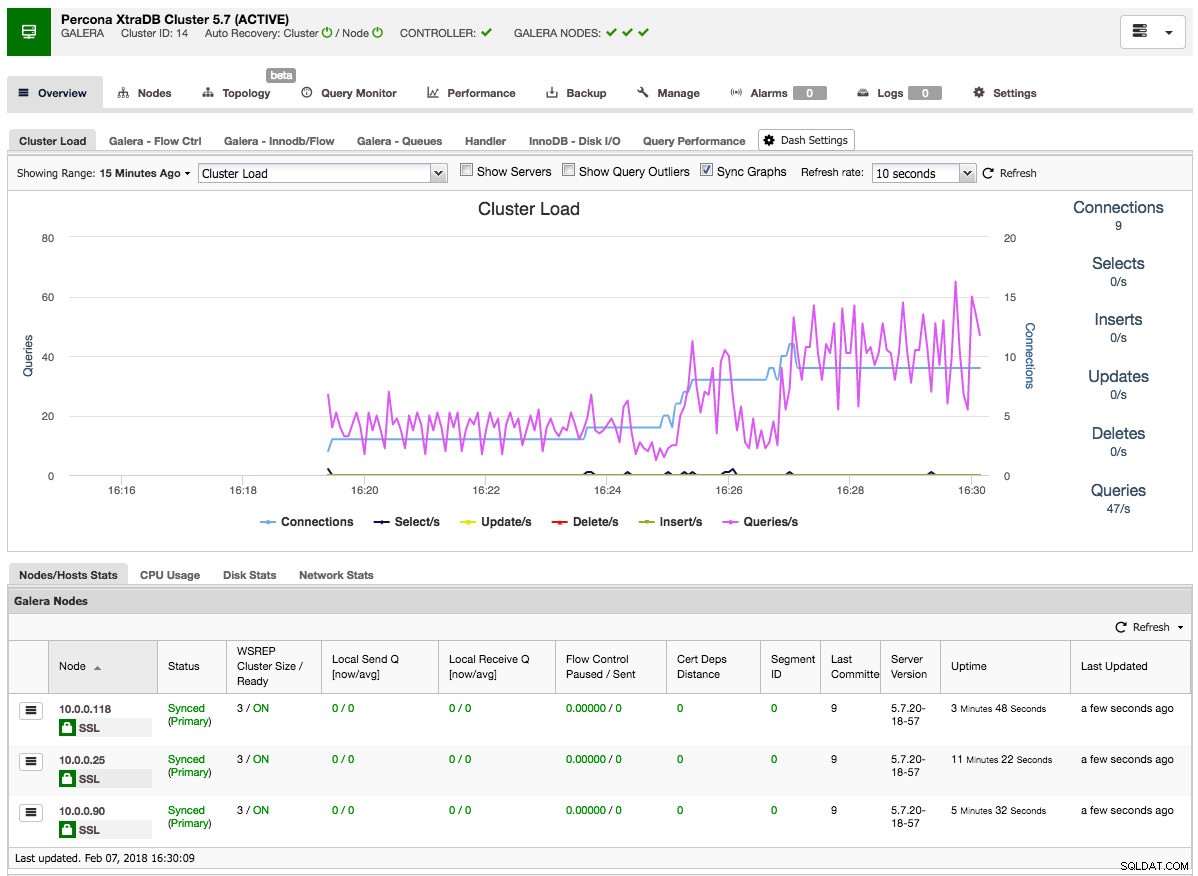
En la pestaña de nodos, puede hacer cualquier operación que normalmente haría en un clúster. El monitor de consultas le brinda una buena descripción general de las consultas principales y en ejecución. La pestaña de rendimiento lo ayudará a vigilar de cerca el rendimiento de su clúster y también presenta los asesores que lo ayudan a actuar de manera proactiva sobre las tendencias en los datos. La pestaña de copia de seguridad le permite programar fácilmente copias de seguridad y almacenarlas en el almacenamiento local o en la nube. La pestaña de administración le permite expandir su clúster o hacerlo altamente disponible para sus aplicaciones a través de un balanceador de carga.
Toda esta funcionalidad se tratará en publicaciones de blog posteriores de esta serie.
Implementar un clúster de replicación de MySQL
La implementación de una configuración de replicación de MySQL es similar a la implementación de la base de datos de Galera, excepto que tiene una pestaña adicional en el cuadro de diálogo de implementación donde puede definir la topología de replicación:
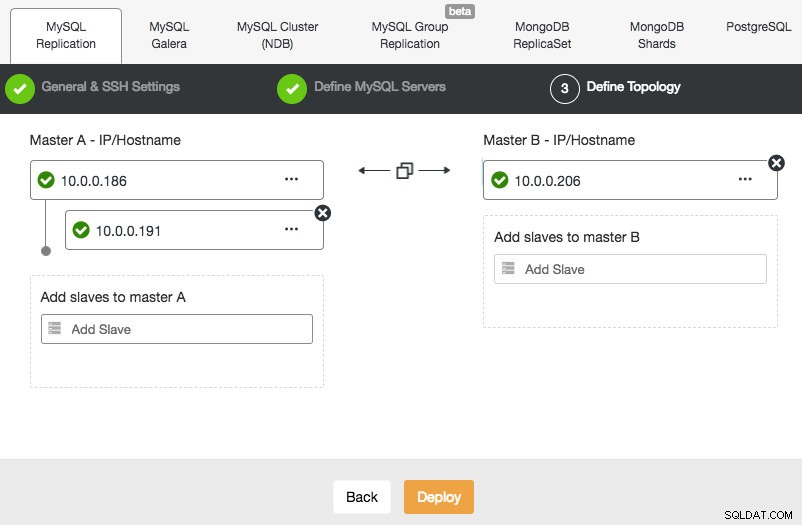
Puede configurar la replicación maestro-esclavo estándar, así como la replicación maestro-maestro. En el caso de este último, solo se podrá escribir en un maestro a la vez. Tenga en cuenta que la replicación maestro-maestro no viene con resolución de conflictos y consistencia de datos garantizada, como en el caso de Galera. Use esta configuración con precaución o busque en el clúster de Galera. Una vez que todo esté en verde y haya hecho clic en Implementar, se generará un trabajo para construir el nuevo clúster.
Una vez más, el progreso de la implementación está disponible en Actividad -> Trabajos.
Para escalar el esclavo (copia de lectura), simplemente use la opción "Agregar nodo" en la lista de clústeres:
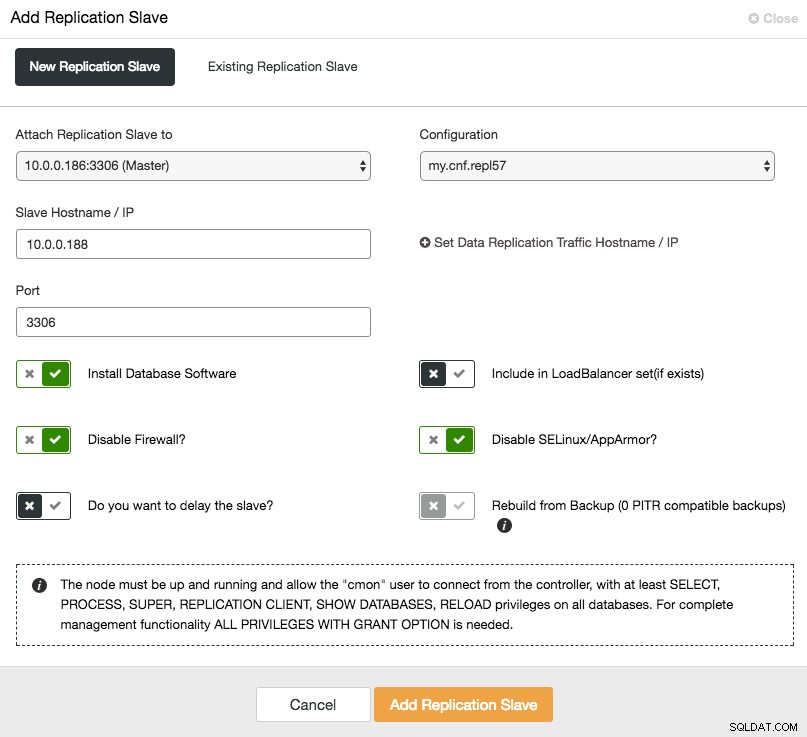
Después de agregar el nodo esclavo, ClusterControl proporcionará al esclavo una copia de los datos de su maestro mediante Xtrabackup o de cualquier copia de seguridad compatible con PITR existente para ese clúster.
Implementar la replicación de PostgreSQL
ClusterControl admite la implementación de PostgreSQL versión 9.x y superior. Los pasos son similares con la implementación de MySQL Replication, donde al final del paso de implementación, puede definir la topología de la base de datos al agregar los nodos:
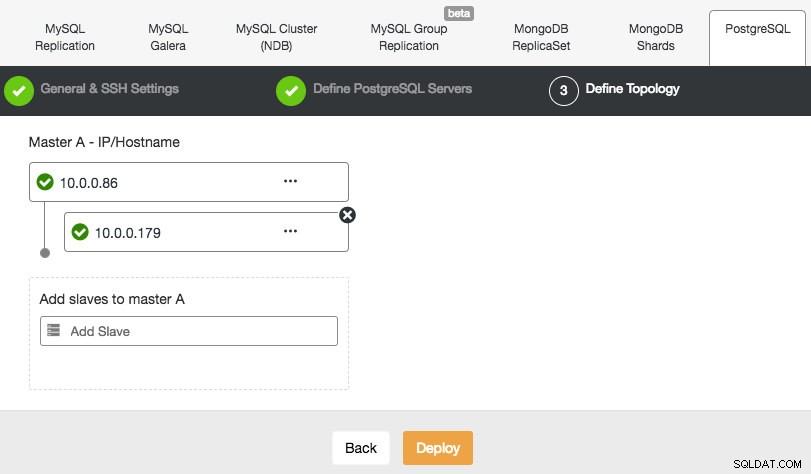
De manera similar a la replicación de MySQL, una vez que se completa la implementación, puede escalar horizontalmente agregando un esclavo de replicaciones al clúster. El paso es tan simple como seleccionar el maestro y completar el FQDN para el nuevo esclavo:
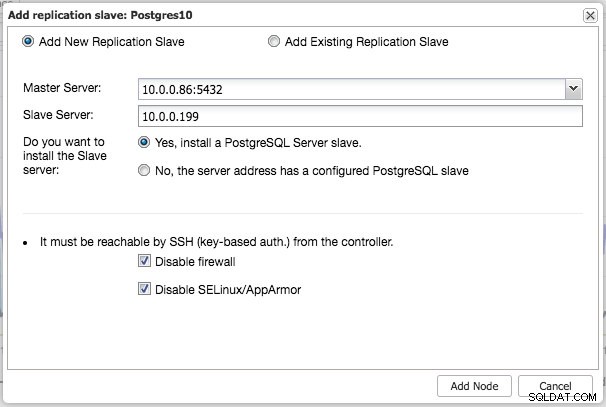
Luego, ClusterControl realizará la preparación de datos necesaria desde el maestro elegido mediante pg_basebackup, configurará el usuario de replicación y habilitará la replicación de transmisión. La descripción general del clúster de PostgreSQL le brinda una idea de su configuración:
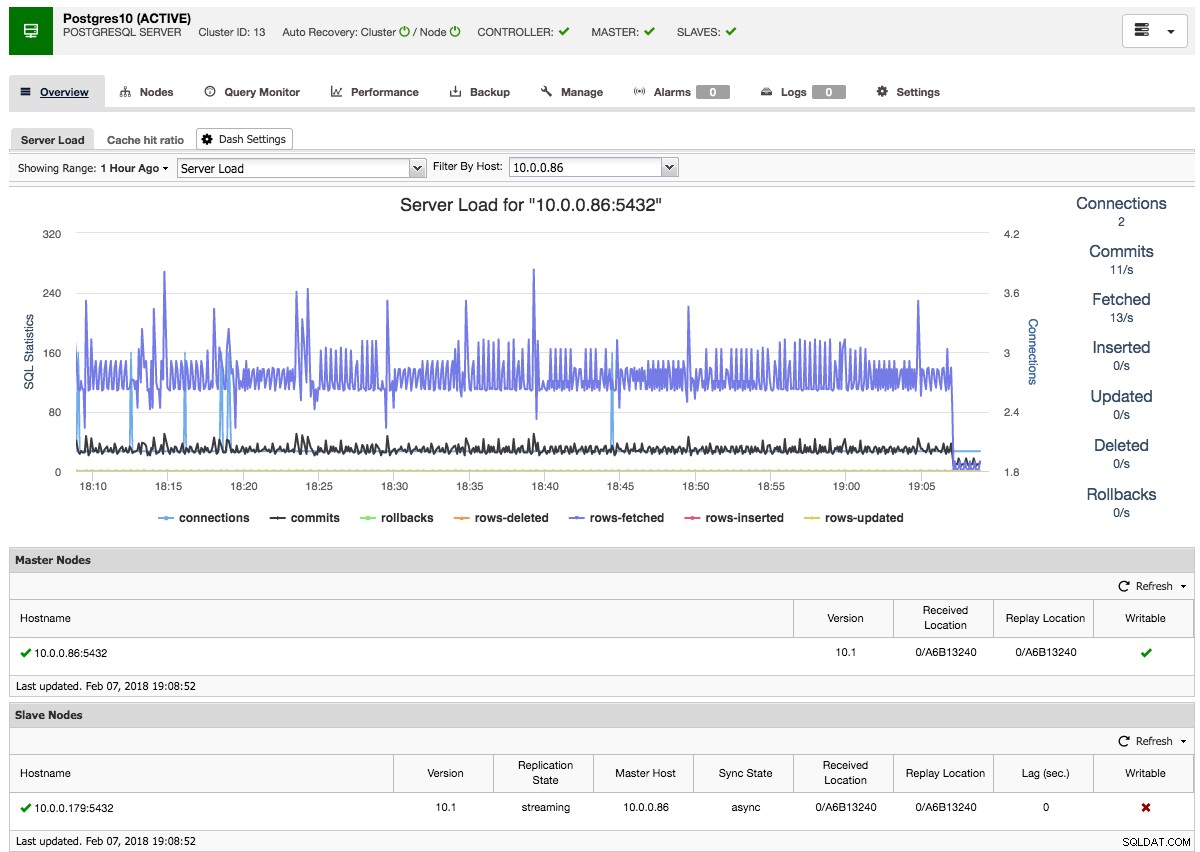
Al igual que con las descripciones generales de los clústeres de Galera y MySQL, aquí puede encontrar todas las pestañas y funciones necesarias:el monitor de consultas, el rendimiento y las pestañas de copia de seguridad le permiten realizar las operaciones necesarias.
Implementar un conjunto de réplicas de MongoDB
La implementación de un nuevo conjunto de réplicas de MongoDB es similar a la de los otros clústeres. En el cuadro de diálogo Implementar clúster de base de datos, elija MongoDB ReplicatSet, defina las opciones de base de datos preferidas y agregue los nodos de la base de datos:
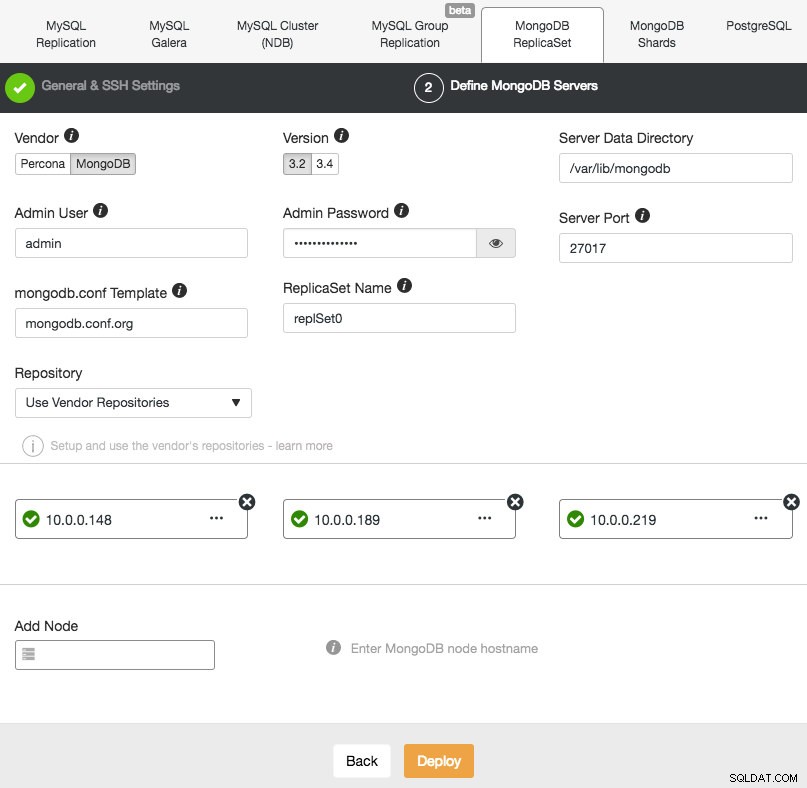
Puede optar por instalar Percona Server para MongoDB de Percona o MongoDB Server de MongoDB, Inc (anteriormente 10gen). También debe especificar el usuario y la contraseña del administrador de MongoDB, ya que ClusterControl implementará de manera predeterminada un clúster de MongoDB con la autenticación habilitada.
Después de instalar el clúster, puede agregar un nodo esclavo o árbitro adicional al conjunto de réplicas usando el menú "Agregar nodo" en el mismo menú desplegable de la descripción general del clúster:
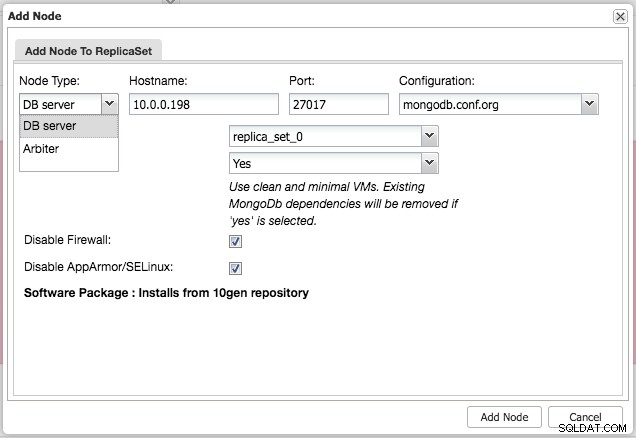
Después de agregar el esclavo o el árbitro al conjunto de réplicas, se generará un trabajo. Una vez que este trabajo haya finalizado, tomará un poco de tiempo antes de que MongoDB lo agregue al clúster y se vuelva visible en la descripción general del clúster:
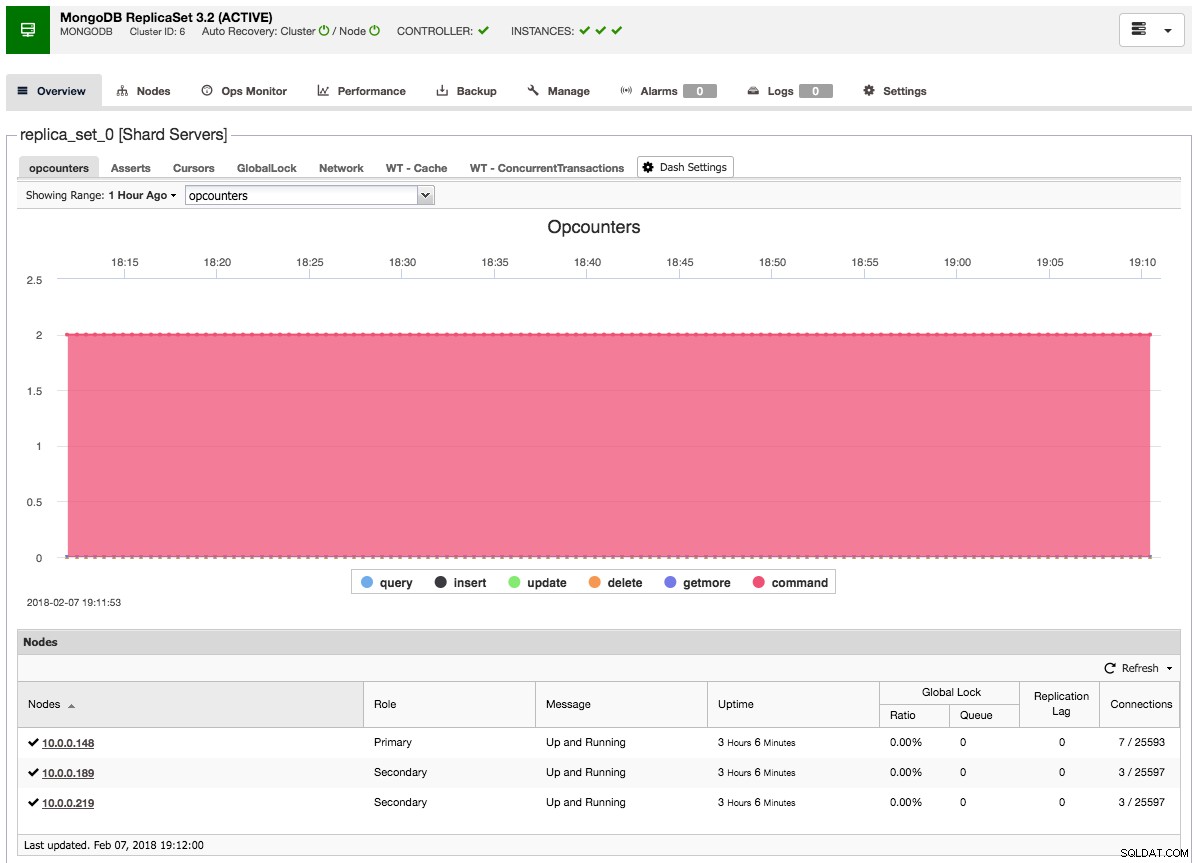
Reflexiones finales
Con estos tres ejemplos, te mostramos lo fácil que es configurar diferentes clústeres desde cero en solo un par de minutos. La belleza de usar esta configuración de Vagrant es que, tan fácil como generar este entorno, también puede eliminarlo y luego generarlo nuevamente. Impresione a sus compañeros mostrando lo rápido que puede configurar un entorno de trabajo.
Por supuesto, sería igualmente interesante agregar hosts existentes y clústeres ya implementados en ClusterControl, y eso es lo que cubriremos la próxima vez.