Para operar cualquier base de datos de manera eficiente, debe conocer el rendimiento de la base de datos. Esto puede no ser obvio cuando todo va bien, pero tan pronto como algo sale mal, el acceso a la información puede ser fundamental para diagnosticar el problema de forma rápida y correcta.
Todas las bases de datos ponen a disposición de los usuarios algunos de sus datos internos de estado. En MySQL, puede obtener estos datos principalmente ejecutando 'MOSTRAR ESTADO' y 'MOSTRAR ESTADO GLOBAL', ejecutando 'MOSTRAR ESTADO DE INNODB DEL MOTOR', verificando las tablas de esquema de información y, en versiones más recientes, consultando las tablas de esquema de rendimiento.

Estos métodos están lejos de ser convenientes en las operaciones diarias, de ahí la popularidad de las diferentes soluciones de monitoreo y tendencias. Herramientas como Nagios/Icinga están diseñadas para monitorear hosts/servicios y alertar cuando un servicio se encuentra fuera de un rango aceptable. Otras herramientas, como Cacti y Munin, brindan una vista gráfica de la información del host/servicio y brindan un contexto histórico para el rendimiento y el uso. ClusterControl combina estos dos tipos de monitoreo, por lo que veremos la información que presenta y cómo debemos interpretarla.
Si está utilizando Galera Cluster (MySQL Galera Cluster by Codership o MariaDB Cluster o Percona XtraDB Cluster), es posible que haya notado la siguiente sección en la pestaña "Descripción general" de ClusterControl:
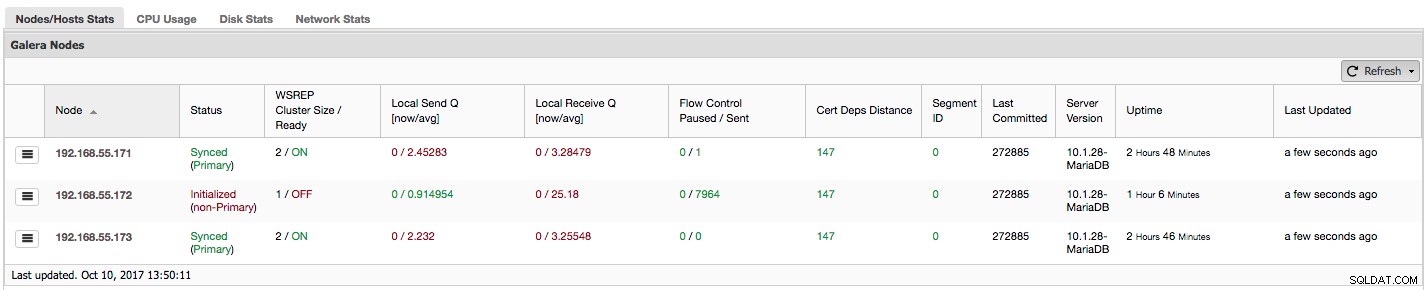
Veamos, paso a paso, qué tipo de datos tenemos aquí.
La primera columna contiene la lista de nodos con sus direcciones IP; no hay mucho más que decir al respecto.
La segunda columna es más interesante:describe el estado del nodo (wsrep_local_state_comment estado). Un nodo puede estar en diferentes estados:
- Inicializado:el nodo está en funcionamiento, pero no forma parte de un clúster. Puede deberse, por ejemplo, a problemas de red;
- Unirse:el nodo está en proceso de unirse al clúster y está recibiendo o solicitando una transferencia de estado de uno de los otros nodos;
- Donante/Desincronizado:el nodo sirve como donante para otro nodo que se une al clúster;
- Unido:el nodo está unido al clúster, pero está ocupado poniéndose al día con los conjuntos de escritura confirmados;
- Sincronizado:el nodo funciona con normalidad.
En la misma columna dentro del paréntesis se encuentra el estado del clúster (wsrep_cluster_status estado). Puede tener tres estados distintos:
- Principal:la comunicación entre los nodos funciona y el quórum está presente (la mayoría de los nodos están disponibles)
- No principal:el nodo formaba parte del clúster pero, por alguna razón, perdió el contacto con el resto del clúster. Como resultado, este nodo se considera inactivo y no aceptará consultas
- Desconectado:el nodo no pudo establecer comunicación grupal.
"Tamaño de clúster de WSREP/Listo" nos informa sobre el tamaño de un clúster tal como lo ve el nodo y si el nodo está listo para aceptar consultas. Los componentes no primarios crean un clúster con un tamaño de 1 y la preparación de wsrep está desactivada.
Echemos un vistazo a la captura de pantalla anterior y veamos qué nos dice sobre Galera. Podemos ver tres nodos. Dos de ellos (192.168.55.171 y 192.168.55.173) están perfectamente bien, ambos están "Sincronizados" y el clúster está en estado "Principal". El clúster consta actualmente de dos nodos. El nodo 192.168.55.172 está "inicializado" y forma un componente "no principal". Significa que este nodo perdió la conexión con el clúster, probablemente algún tipo de problema de red (de hecho, usamos iptables para bloquear el tráfico a este nodo desde 192.168.55.171 y 192.168.55.173).
En este momento tenemos que detenernos un poco y describir cómo funciona Galera Cluster internamente. No entraremos en demasiados detalles ya que no está dentro del alcance de esta publicación de blog, pero se requiere cierto conocimiento para comprender la importancia de los datos presentados en las siguientes columnas.
Galera es un clúster multimaestro "virtualmente" síncrono. Significa que debe esperar que los datos se transfieran a través de los nodos "virtualmente" al mismo tiempo (no más problemas molestos con los esclavos retrasados) y que puede escribir en cualquier nodo en un clúster (no más problemas molestos con la promoción de un esclavo a maestro ). Para lograrlo, Galera utiliza conjuntos de escritura, un conjunto atómico de cambios que se replican en todo el clúster. Un conjunto de escritura puede contener varios cambios de fila e información adicional necesaria, como datos relacionados con el bloqueo.
Una vez que un cliente emite COMMIT, pero antes de que MySQL realmente confirme algo, se crea un conjunto de escritura y se envía a todos los nodos del clúster para su certificación. Todos los nodos verifican si es posible confirmar los cambios o no (ya que los cambios pueden interferir con otras escrituras ejecutadas, mientras tanto, directamente en otro nodo). En caso afirmativo, MySQL confirma los datos; de lo contrario, se ejecuta la reversión.
Lo que es importante recordar es el hecho de que los nodos, similares a los esclavos en la replicación regular, pueden funcionar de manera diferente:algunos pueden tener mejor hardware que otros, algunos pueden estar más cargados que otros. Sin embargo, Galera les exige que procesen los conjuntos de escritura de forma breve y rápida, a fin de mantener la sincronización "virtual". Tiene que haber un mecanismo que pueda acelerar la replicación y permitir que los nodos más lentos se mantengan al día con el resto del clúster.
Echemos un vistazo a las columnas "Q de envío local [ahora/promedio]" y "Q de recepción local [ahora/promedio]". Cada nodo tiene una cola local para enviar y recibir conjuntos de escritura. Permite paralelizar algunas de las escrituras y datos en cola que no podrían procesarse a la vez si el nodo no puede mantenerse al día con el tráfico. En MOSTRAR ESTADO GLOBAL podemos encontrar ocho contadores que describen ambas colas, cuatro contadores por cola:
- wsrep_local_send_queue - estado actual de la cola de envío
- wsrep_local_send_queue_min - mínimo desde ESTADO DE LIMPIEZA
- wsrep_local_send_queue_max - máximo desde ESTADO DE LIMPIEZA
- wsrep_local_send_queue_avg - promedio desde ESTADO DE LIMPIEZA
- wsrep_local_recv_queue - estado actual de la cola de recepción
- wsrep_local_recv_queue_min - mínimo desde ESTADO DE LIMPIEZA
- wsrep_local_recv_queue_max - máximo desde ESTADO DE LIMPIEZA
- wsrep_local_recv_queue_avg - promedio desde ESTADO DE LIMPIEZA
Las métricas anteriores se unifican en todos los nodos en ClusterControl -> Rendimiento -> Estado de la base de datos:
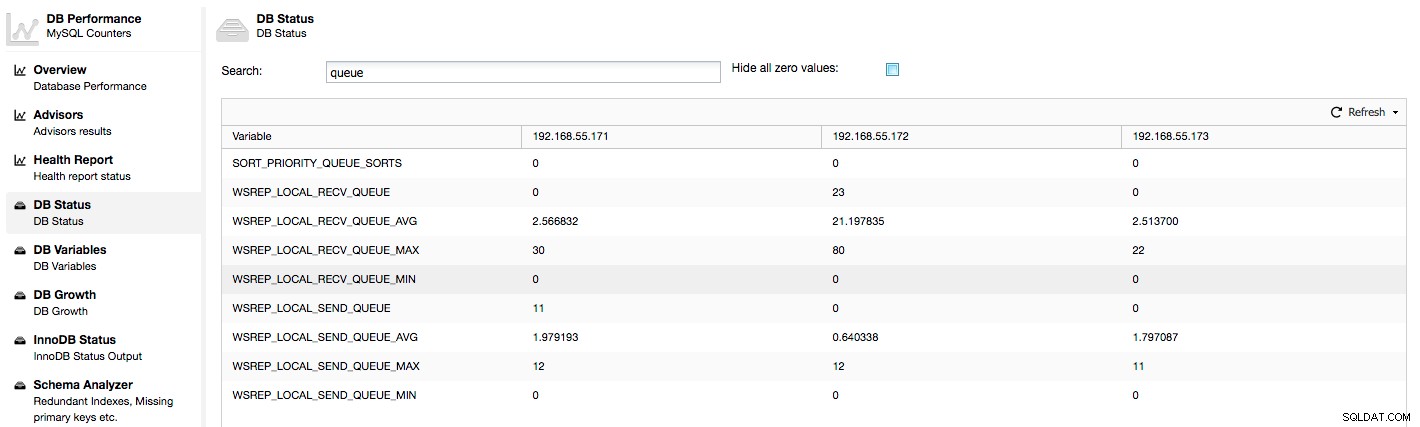
ClusterControl muestra los contadores "ahora" y "promedio", ya que son los más significativos como un solo número (también puede crear gráficos personalizados basados en variables que describen el estado actual de las colas). Cuando vemos que una de las colas está aumentando, esto significa que el nodo no puede seguir el ritmo de la replicación y otros nodos tendrán que reducir la velocidad para permitir que se ponga al día. Recomendamos investigar una carga de trabajo de ese nodo determinado:verifique la lista de procesos para ver si hay consultas de ejecución prolongada, verifique las estadísticas del sistema operativo, como la utilización de la CPU y la carga de trabajo de E/S. Tal vez también sea posible redistribuir parte del tráfico de ese nodo al resto del clúster.
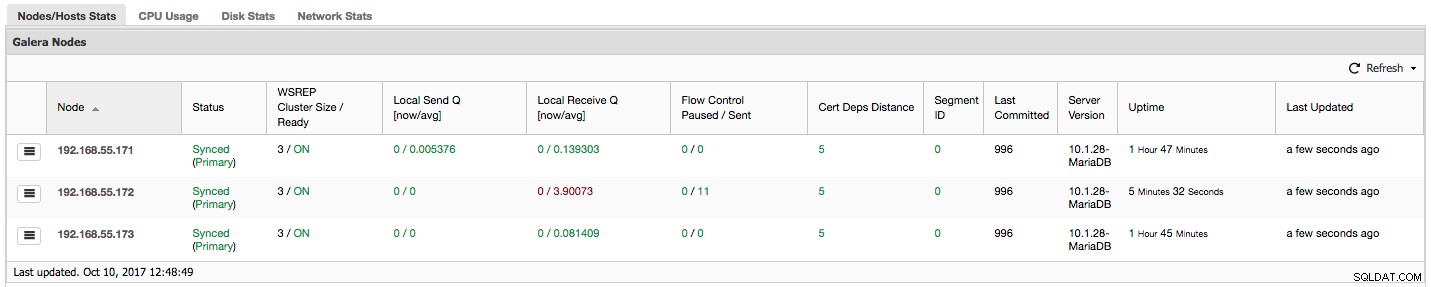
"Control de flujo en pausa" muestra información sobre el porcentaje de tiempo que un nodo determinado tuvo que pausar su replicación debido a una carga demasiado pesada. Cuando un nodo no puede mantenerse al día con la carga de trabajo, envía paquetes de control de flujo a otros nodos, informándoles que deben reducir el envío de conjuntos de escritura. En nuestra captura de pantalla, tenemos un valor de '0.30' para el nodo 192.168.55.172. Esto significa que casi el 30% del tiempo este nodo tuvo que pausar la replicación porque no pudo mantenerse al día con la tasa de certificación de conjunto de escritura requerida por otros nodos (o más simple, ¡demasiadas escrituras lo alcanzaron!). Como podemos ver, es "Local Receive Q [avg]" que también nos indica este hecho.
La siguiente columna, "Control de flujo enviado", nos brinda información sobre cuántos paquetes de control de flujo envió un nodo determinado al clúster. Nuevamente, vemos que es el nodo 192.168.55.172 el que está ralentizando el clúster.
¿Qué podemos hacer con esta información? Principalmente, deberíamos investigar qué está pasando en el nodo lento. Verifique la utilización de la CPU, verifique el rendimiento de E/S y las estadísticas de la red. Este primer paso ayuda a evaluar a qué tipo de problema nos enfrentamos.
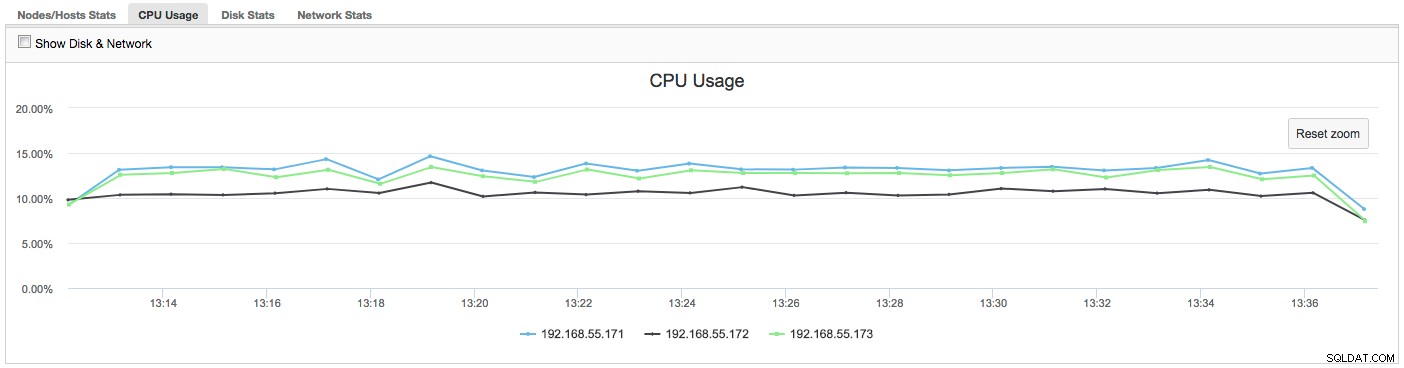
En este caso, una vez que cambiamos a la pestaña Uso de la CPU, queda claro que la utilización extensiva de la CPU está causando nuestros problemas. El siguiente paso sería identificar al culpable mirando PROCESSLIST (Monitor de consultas -> Consultas en ejecución -> filtrar por 192.168.55.172) para verificar si hay consultas infractoras:
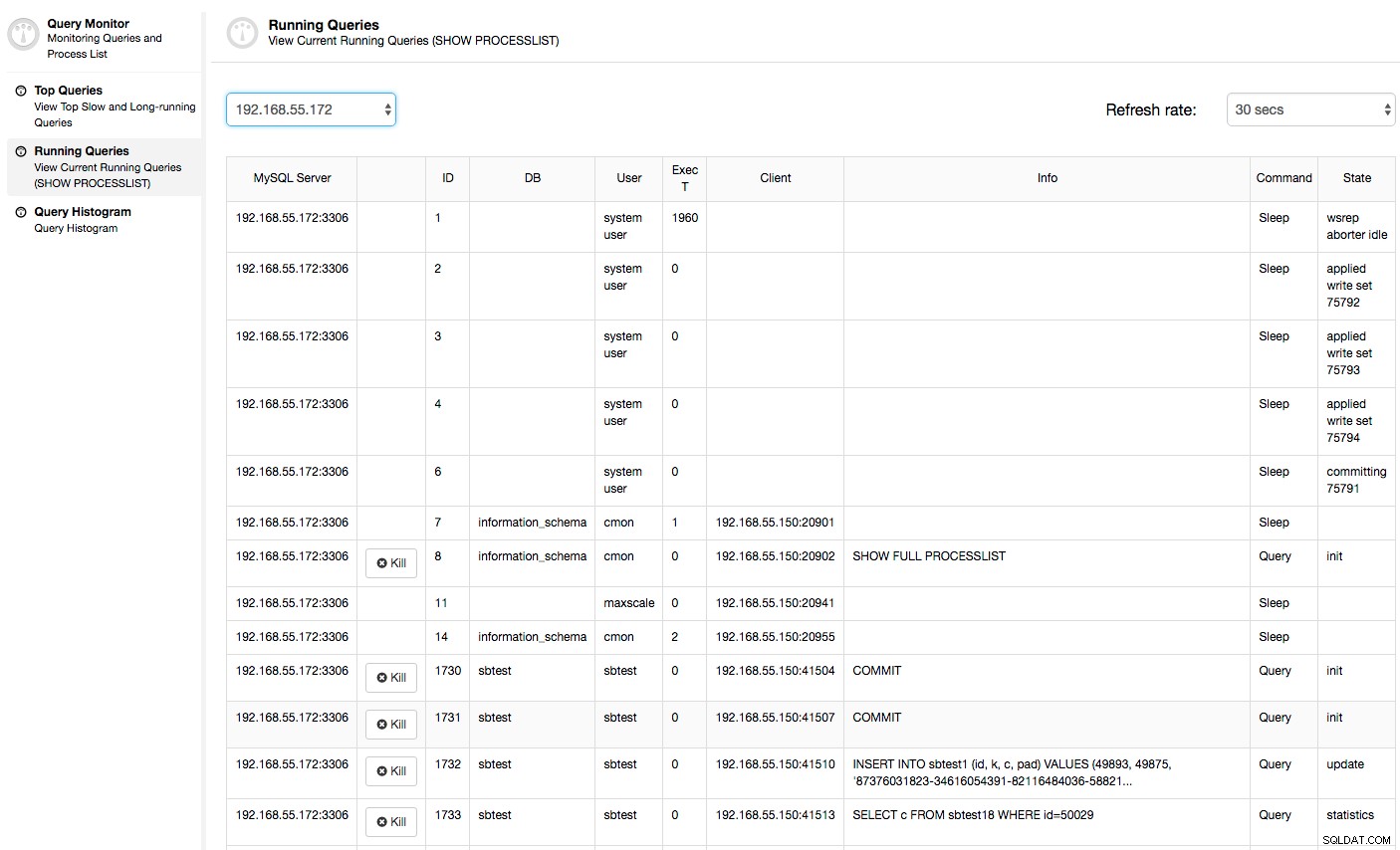
O verifique los procesos en el nodo desde el lado del sistema operativo (Nodos -> 192.168.55.172 -> Arriba) para ver si la carga no es causada por algo fuera de Galera/MySQL.
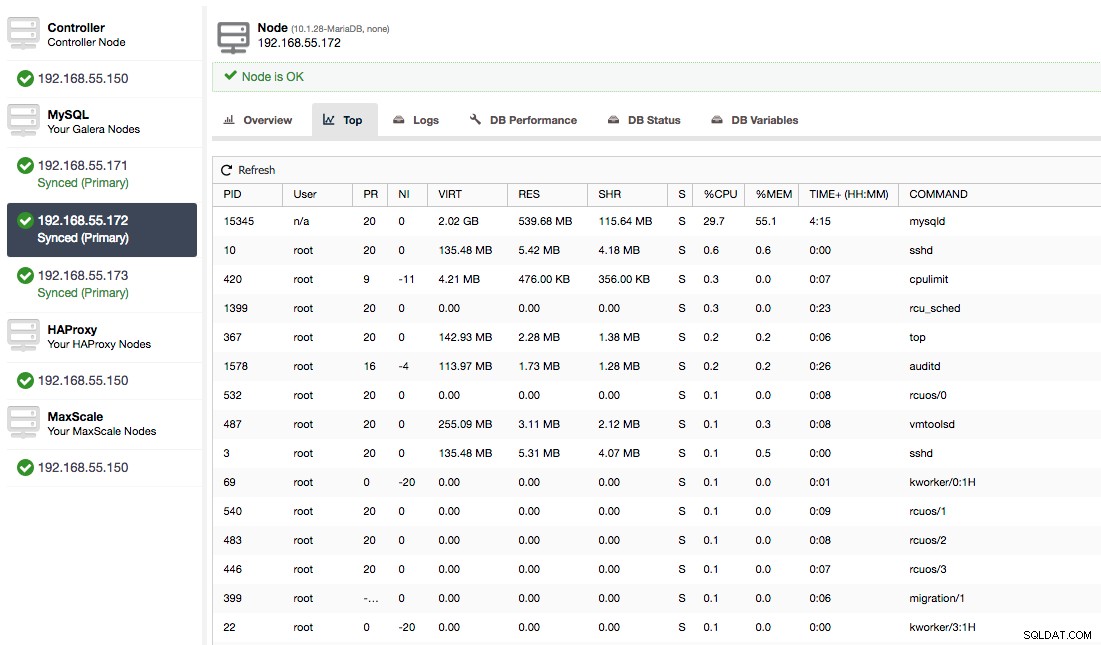
En este caso, hemos ejecutado el comando mysqld a través de cpulimit, para simular un uso lento de la CPU específicamente para el proceso mysqld limitándolo al 30 % del 400 % de la CPU disponible (el servidor tiene 4 núcleos).
La columna "Cert Deps Distance" nos brinda información sobre cuántos conjuntos de escritura, en promedio, se pueden aplicar en paralelo. Los conjuntos de escritura pueden, a veces, ejecutarse al mismo tiempo; Galera aprovecha esto al usar múltiples wsrep_slave_threads para aplicar conjuntos de escritura. Esta columna le da una idea de cuántos subprocesos esclavos podría usar en su carga de trabajo. Vale la pena señalar que no tiene sentido configurar wsrep_slave_threads variable a valores superiores a los que ve en esta columna o en wsrep_cert_deps_distance variable de estado, en la que se basa la columna "Cert Deps Distance". Otra nota importante:tampoco tiene sentido configurar wsrep_slave_threads variable a más de la cantidad de núcleos que tiene su CPU.
"ID de segmento":esta columna requerirá más explicaciones. Los segmentos son una nueva característica añadida en Galera 3.0. Antes de esta versión, los conjuntos de escritura se intercambiaban entre todos los nodos. Digamos que tenemos dos centros de datos:
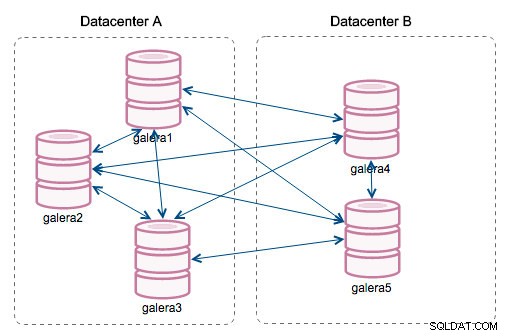
Este tipo de charla funciona bien en las redes locales, pero la WAN es una historia diferente:la certificación se ralentiza debido al aumento de la latencia, se generan costos adicionales debido al ancho de banda de la red que se usa para transferir conjuntos de escritura entre cada miembro del clúster.
Con la introducción de "Segmentos", las cosas cambiaron. Puede asignar un nodo a un segmento modificando wsrep_provider_options variable y añadiéndole "gmcast.segment=x" (0, 1, 2). Los nodos con el mismo número de segmento se tratan como si estuvieran en el mismo centro de datos, conectados por una red local. Nuestro gráfico entonces se vuelve diferente:
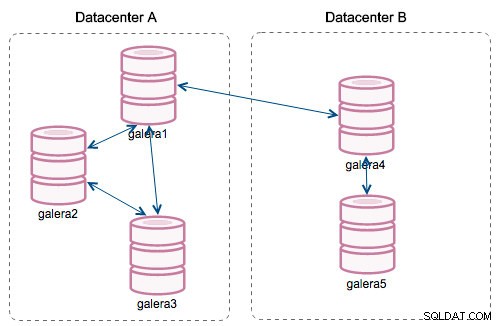
La principal diferencia es que ya no se trata de una comunicación de todos para todos. Dentro de cada segmento, sí, sigue siendo el mismo mecanismo, pero ambos segmentos se comunican solo a través de una única conexión entre dos nodos elegidos. En caso de tiempo de inactividad, esta conexión se conmutará automáticamente. Como resultado, obtenemos menos conversaciones en la red y menos uso de ancho de banda entre los centros de datos remotos. Entonces, básicamente, la columna "ID de segmento" nos dice a qué segmento se asigna un nodo.
La columna "Última confirmación" nos brinda información sobre el número de secuencia del conjunto de escritura que se ejecutó por última vez en un nodo determinado. Puede ser útil para determinar qué nodo es el más actual si es necesario arrancar el clúster.
El resto de las columnas se explican por sí mismas:versión del servidor, tiempo de actividad de un nodo y cuándo se actualizó el estado.
Como puede ver, la sección "Nodos de Galera" de "Estadísticas de nodos/hosts" en la pestaña "Descripción general" le brinda una comprensión bastante buena de la salud del clúster, ya sea que forme un componente "Principal", cuántos nodos están en buen estado , ¿hay algún problema de rendimiento con algunos nodos y, en caso afirmativo, qué nodo está ralentizando el clúster?
Este conjunto de datos es muy útil cuando opera su clúster Galera, por lo que, con suerte, no volverá a volar a ciegas :-)