Una de las formas más populares de lograr alta disponibilidad para MySQL es la replicación. La replicación existe desde hace muchos años y se volvió mucho más estable con la introducción de los GTID. Pero incluso con estas mejoras, el proceso de replicación puede fallar debido a varias razones, por ejemplo, cuando el maestro y el esclavo no están sincronizados porque las escrituras se enviaron directamente al esclavo. ¿Cómo soluciona los problemas de replicación y cómo los soluciona?
En esta publicación de blog, analizaremos algunos de los problemas comunes con la replicación y cómo solucionarlos con ClusterControl. Comencemos con el primero.
Replicación detenida con algún error
La mayoría de los DBA de MySQL suelen ver este tipo de problema al menos una vez en su carrera. Por varias razones, un esclavo puede corromperse o dejar de sincronizarse con el maestro. Cuando esto sucede, lo primero que debe hacer para iniciar la solución de problemas es verificar el registro de errores en busca de mensajes. La mayoría de las veces, el mensaje de error se puede rastrear fácilmente en el registro de errores o ejecutando la consulta SHOW SLAVE STATUS.
Veamos el siguiente ejemplo de SHOW STATUS SLAVE:
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0Podemos ver claramente que el error está relacionado con Obtuvo el error fatal 1236 del maestro al leer datos del registro binario:'No se pudo encontrar el estado de GTID solicitado por el esclavo en ningún archivo binlog. Probablemente el estado esclavo es demasiado antiguo y los archivos binlog necesarios se han eliminado.'. En otras palabras, lo que el error nos dice esencialmente es que hay incoherencias en los datos y que los archivos de registro binarios necesarios ya se han eliminado.
Este es un buen ejemplo donde el proceso de replicación deja de funcionar. Además de MOSTRAR ESTADO DE ESCLAVO, también puede realizar un seguimiento del estado en la pestaña "Descripción general" del clúster en ClusterControl. Entonces, ¿cómo solucionar esto con ClusterControl? Tienes dos opciones para probar:
-
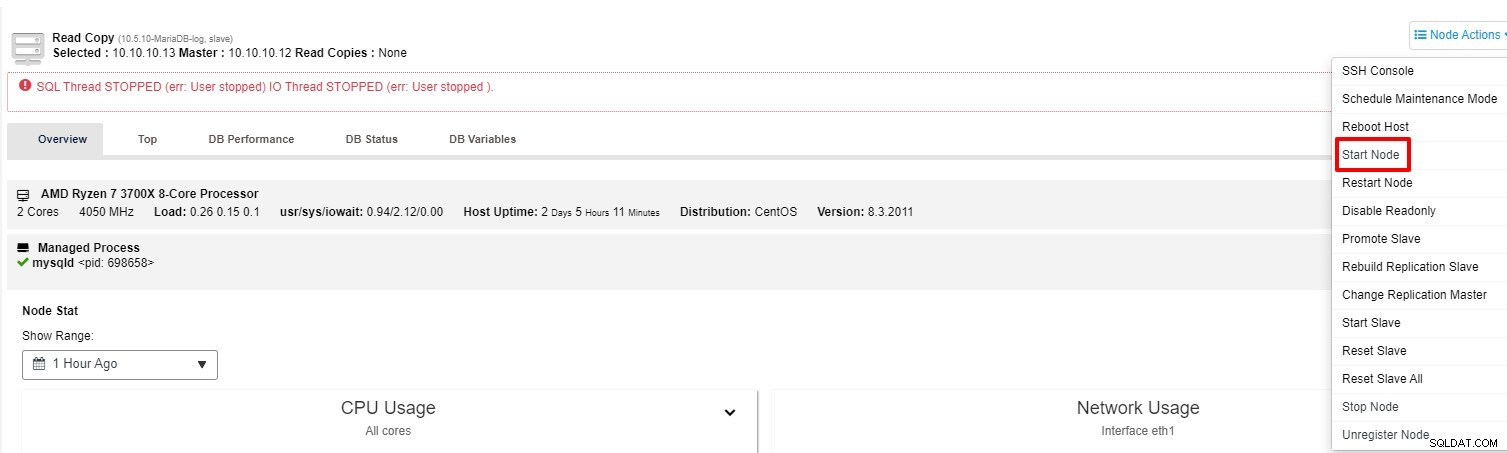
Puede intentar iniciar el esclavo nuevamente desde la "Acción de nodo"
-
Si el esclavo aún no funciona, puede ejecutar el trabajo "Reconstruir esclavo de replicación" de la “Acción de nodo”
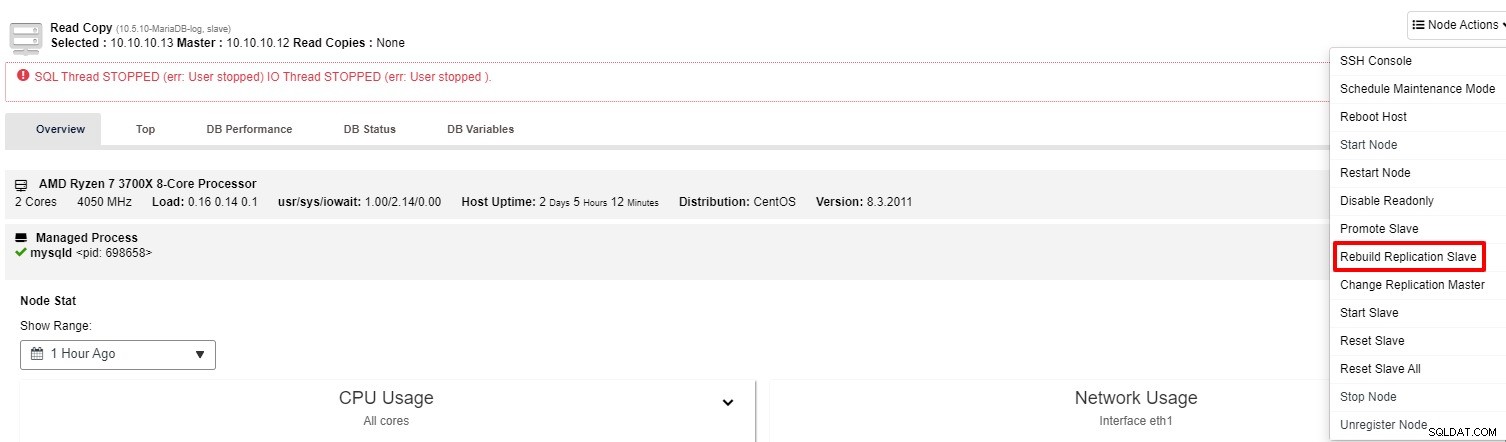
La mayoría de las veces, la segunda opción resolverá el problema. ClusterControl realizará una copia de seguridad del maestro y reconstruirá el esclavo dañado mediante la restauración de los datos. Una vez que se restauran los datos, el esclavo se conecta al maestro para que pueda ponerse al día.
También hay varias formas manuales de reconstruir el esclavo, como se indica a continuación. También puede consultar este enlace para obtener más detalles:
-
Uso de Mysqldump para reconstruir un esclavo MySQL inconsistente
-
Uso de Mydumper para reconstruir un esclavo MySQL inconsistente
-
Uso de una instantánea para reconstruir un esclavo MySQL inconsistente
-
Uso de Xtrabackup o Mariabackup para reconstruir un esclavo MySQL inconsistente
Convertir a un esclavo en maestro
Con el tiempo, el sistema operativo o la base de datos deben parchearse o actualizarse para mantener la estabilidad y la seguridad. Una de las mejores prácticas para minimizar el tiempo de inactividad, especialmente para una actualización importante, es promover uno de los esclavos a maestro después de que la actualización se haya realizado con éxito en ese nodo en particular.
Al hacer esto, puede apuntar su aplicación al nuevo maestro y la replicación maestro-esclavo continuará funcionando. Mientras tanto, también puede continuar con la actualización del antiguo maestro con tranquilidad. Con ClusterControl, esto se puede ejecutar con unos pocos clics solo suponiendo que la replicación esté configurada como basada en ID de transacción global o basada en GTID para abreviar. Para evitar la pérdida de datos, vale la pena detener cualquier consulta de la aplicación en caso de que el antiguo maestro funcione correctamente. Esta no es la única situación en la que podrías promocionar al esclavo. En caso de que el nodo principal esté inactivo, también puede realizar esta acción.
Sin ClusterControl, hay algunos pasos para promover el esclavo. Cada uno de los pasos también requiere algunas consultas para ejecutarse:
-
Eliminar manualmente al maestro
-
Seleccione el esclavo más avanzado para que sea maestro y prepárelo
-
Reconectar otros esclavos al nuevo maestro
-
Cambiando el antiguo maestro para que sea un esclavo
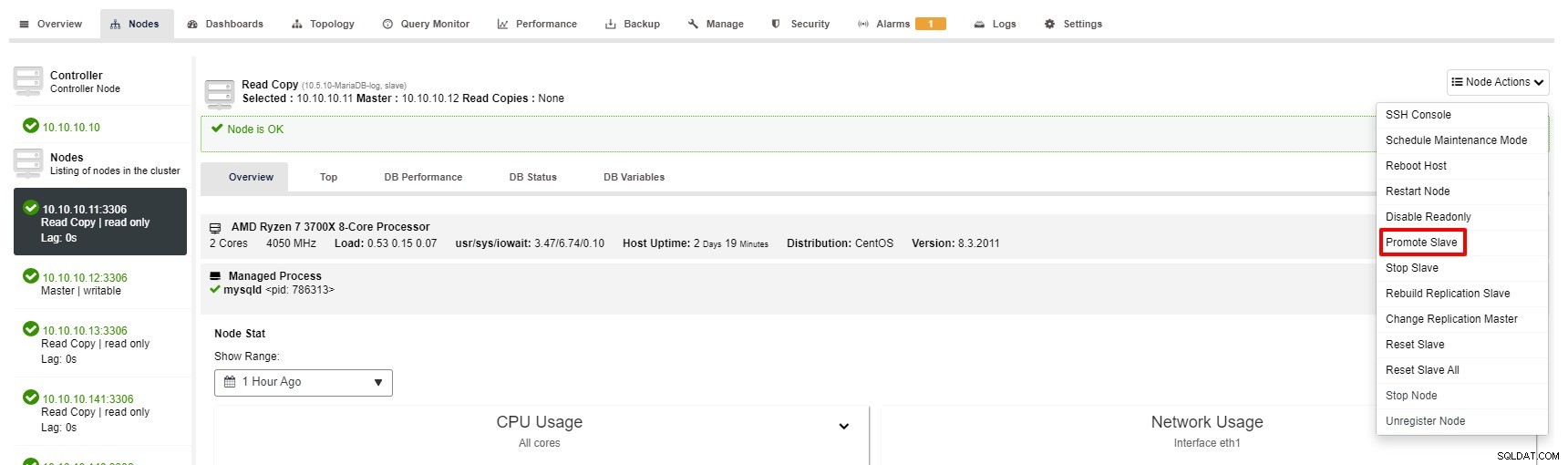
Sin embargo, los pasos para promocionar esclavo con ClusterControl son solo unos pocos clics:Clúster> Nodos> elegir nodo esclavo> Promover esclavo según la siguiente captura de pantalla:
El maestro deja de estar disponible
Imagínese que tiene grandes transacciones para ejecutar pero la base de datos no funciona. No importa cuán cuidadoso sea, esta es probablemente la situación más grave o crítica para una configuración de replicación. Cuando esto sucede, su base de datos no puede aceptar una sola escritura, lo cual es malo. Además, su(s) aplicación(es), por supuesto, no funcionarán correctamente.
Hay algunas razones o causas que conducen a este problema. Algunos de los ejemplos son fallas de hardware, corrupción del sistema operativo, corrupción de la base de datos, etc. Como DBA, debe actuar rápidamente para restaurar la base de datos maestra.
Gracias a la función de clúster "Recuperación automática" que está disponible en ClusterControl, el proceso de conmutación por error se puede automatizar. Se puede habilitar o deshabilitar con un solo clic. Como dice el nombre, lo que hará es mostrar toda la topología del clúster cuando sea necesario. Por ejemplo, una replicación maestro-esclavo debe tener al menos un maestro vivo en un momento dado, independientemente de la cantidad de esclavos disponibles. Cuando el maestro no está disponible, automáticamente promoverá a uno de los esclavos.
Veamos la siguiente captura de pantalla:
En la captura de pantalla anterior, podemos ver que la "Recuperación automática" está habilitada tanto para el clúster como para el nodo. En la topología, observe que la dirección IP maestra actual es 10.10.10.11. ¿Qué sucederá si eliminamos el nodo maestro con fines de prueba?
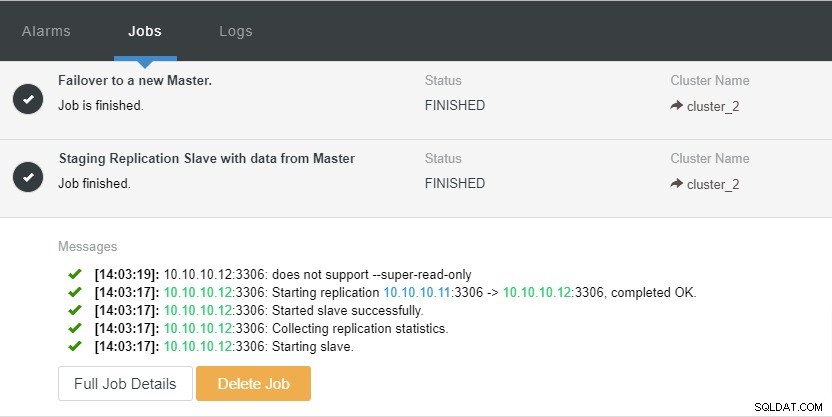
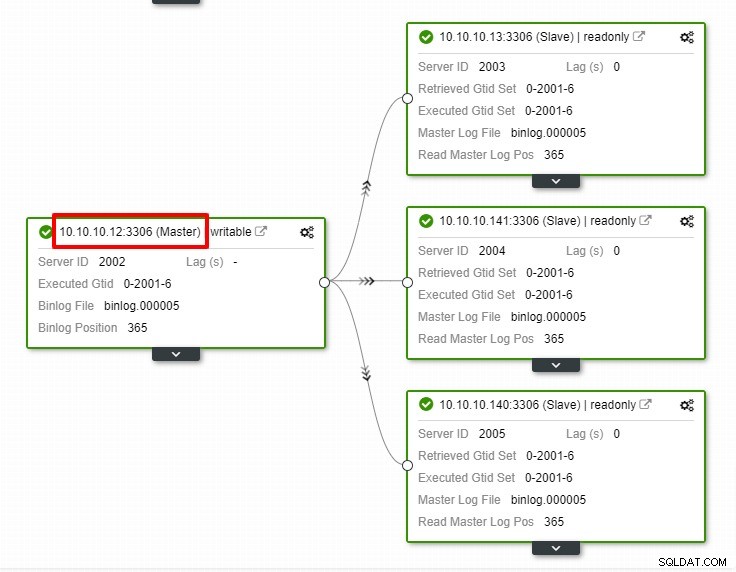
Como puede ver, el nodo esclavo con IP 10.10.10.12 es automáticamente promovido a maestro, para que la topología de replicación se vuelva a configurar. En lugar de hacerlo manualmente, lo que, por supuesto, requerirá muchos pasos, ClusterControl lo ayuda a mantener su configuración de replicación al quitarle las molestias de las manos.
Conclusión
En cualquier evento desafortunado con su replicación, la solución es muy simple y menos complicada con ClusterControl. ClusterControl lo ayuda a recuperar sus problemas de replicación rápidamente, lo que aumenta el tiempo de actividad de sus bases de datos.